在当今企业中80%的数据都是非结构化数据,这些数据每年都按指数增长60%。大数据将挑战企业的存储架构、数据中心的基础设施等,也会引发数据仓库、数据挖掘、商业智能、云计算等应用的连锁反应。未来企业会将更多的TB级(1TB=1024GB)数据集用于商务智能和商务分析。到2020年,全球数据使用量预计将暴增44倍,达到35.2ZB(1ZB=10亿TB)。大数据正在彻底改变IT世界。大数据时代的来临已经毋庸置疑,尤其是在电信、金融 等行业,几乎已经到了“数据就是业务本身”的地步。这种趋势已经让很多相信数据之力量的企业做出改变。
恰逢此时,为了让更多的人了解和使用分析大数据,CSDN独家承办的大数据技术大会于2011年11月26日在北京中旅大厦隆重举行。本次大会汇集 Hadoop、NoSQL、数据分析与挖掘、数据仓库、商业智能以及开源云计算架构等诸多热点话题。包括百度、淘宝、新浪等业界知名专家与参会者齐聚一堂,共同探讨大数据浪潮下的行业应对法则以及大数据时代的抉择。
大会背景
大数据的浪潮已经影响到了很多企业。淘宝目前每天的活跃数据量已经超过50TB,共有4亿条产品讯息和2亿多名注册用户在上面活动,每天超过 4000万人次访问;百度每日新增数据10TB,每天系统需要处理1PB的数据,每天提交10000+ jobs,而每周有近百块硬盘故障;上海证券交易所每秒处理近9万笔业务,每日成交笔数达到3亿笔以上。
在这其中,还挟裹着一个更为重要的趋势,即数据的社会化(Socialization of Data)。从博客论坛到游戏社区再到微博,从互联网到移动互联网再到物联网,人类以及各类物理实体的实时联网已经而且还将继续产生难以估量的数据。对于时刻关注市场走向的企业来讲,他们需要关注的数据显然已经不仅限于企业内部数据库中的业务数据,还要包括互联网(以及未来的物联网)上各类网络活动所产生的相关数据记录。
与此同时,在“大数据”时代出现了不少新兴的数据挖掘技术,使得对数据财富的储存、处理和分析变得比以往任何时候都更便宜、更快速了。只要有了好的计算环境,那么大数据技术就能被众多的企业所用,从而改变很多行业经营业务的的方式。
大会三大亮点
本次大会包含最受关注的技术话题:Hadoop、NoSQL、数据分析与挖掘、数据仓库、商业智能、开源云计算架构等最受关注的技术热点;最资深的技术专家:百度、淘宝、新浪等业界知名数据处理专家齐聚;***行业应用实践:金融、广告、SNS、游戏、电子商务行业大数据架构***实践。九名讲师围绕架构、数据分析、商业智能等话题,深入分享实战经验,解析开发中普遍遇到的难点与技术热点。
大会精彩内容
金融领域大数据处理的专家ymall.com技术总监巨建华表示高频金融交易数据的主要特点是实时性和大规模,目前沪深两市每天4个小时的交易时间 会产生3亿条以上逐笔成交数据,随着时间的积累数据规模非常可观,与一般日志数据不同的是这些数据在金融工程领域有较高的分析价值,金融投资研究机构需要 经常对历史和实时数据进行挖掘创新,以创造和改进数量化交易模型,并将之应用在基于计算机模型的实时证券交易过程中,因此一般的数据库系统无法满足如此大 规模和实时性,灵活性的要求。
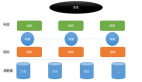
而来自淘宝的两位专家则分别介绍了淘宝在面临大数据时代是如何解决存储和数据处理的难题。淘宝核心系统存储系统研发专家杨志丰表示淘宝每天大约有 6000万用户登录以及20亿PV量。淘宝数据库对于淘宝来说非常重要。几乎所有淘宝业务都依赖淘宝数据库。淘宝数据库具备数以千计的数据库服务器同时要 应对单表几亿至几百亿条的记录以及每天几亿至几百亿次访问。为了应对大数据的冲击,淘宝将以前的Oracle、小型机、高端存储模式转变到现今的 MySQL、OceanBase、Hbase、MongoDB等数据库,并使用普通PC服务器。杨志丰表示OceanBase可扩展数千亿条记录、数百 TB数据、数十万QPS以及数万TPS。同时具备实时容错、自动故障恢复和99.999%高可用性。
淘宝数据产品团队负责人赵昆则表示现今淘宝面临数据量大;内容多样(日志型数据、文本数据、关系型数据);维度丰富(涵盖近100个不同行业的商品 维度,五级商品类目体系、近 80000个品牌、商品维度+卖家维度+买家维度);源数据质量不高(非法交易、恶意评价、用于自定义属性)等问题。对于淘宝面临的挑战,赵昆认为分布式 存储计算、实时计算、实时流处理、基于云计算的数据挖掘、数据可视化和数据产品实践等是应对大数据浪潮的关键技术。赵昆***向大家介绍了淘宝的数据魔方。 他表示数据魔方是淘宝***个基于全量数据的数据产品。也是***个成熟的、基于海量数据的商业数据产品。数据魔方底层基于云计算,同时明年计划开放数据给第 三方应用。
Admaster数据挖掘总监谢超作为数据分析领域的专家也阐述了当今大数据下数据分析的形势。他认为必须分布式存储(TB/天)、多个海量数据集 (千亿行join)、差的数据质量以及不统一的数据格式(结构化、半结构化等、非结构化合并分析数据集的特点)是数据存储方案面临的挑战。谢超表示大数据 BI的新需求包括大量化(多个大数据集并行分析)、多样化(结构化、半结构化、非结构化)、快速化(Velocity)和价值(易用性)。而计算分层(流 计算、块计算、全局计算)、快速分析(冗余维度、数据常驻在内存中分析)和接近价值(业务人员易用的命令、灵活的编程框架)是解决新需求的BI方案。
互联网巨头新浪的云计算高级技术经理丛磊透露了SAE的相关数据,他表示2011年新浪SAE平台注册用户已达50000,应用超过100000, 日均PV达到1亿,活跃开发者达到10000名。丛磊还介绍了新浪自己开发的的KVDB,KVDB用来支持公有云计算平台上的海量key-value存 储。KV DB支持的存储容量很大,对每个用户支持100G的存储空间,可支持1000000000条记录,用户可以用KV DB存放简单数据,如好友关系等。KVDB具备存储引擎可替换、任意模块水平扩展、支持读写分离、支持前缀查找、支持secondary index、支持认证、支持重平衡和无缝迁移等优势。
***人云科技创始人兼总经理吴朱华表示海量数据呈现“4V + 1C”的特点。既Variety:一般包括结构化、半结构化和非结构化等多类数据,而且它们处理和分析方式有区别;Volume:通过各种设备产生了大量 的数据,PB级别是常态;Velocity:要求快速处理,存在时效性;Vitality:分析和处理模型必须快速变化,因为需求在 变;Complexity:处理和分析的难度非常大。互联网企业、智能电网、车联网、医疗行业和安全领域等都充分体现出海量数据的用途和价值。他认为中小 企业面对大数据的解决之道应遵循采集、导入/处理、查询、挖掘的流程。