关于Linux性能监控相信大家已经小有了解,对于IO篇,让我们先分析一些具体的情况,在这些情况下I/O会成为系统的瓶颈。我们会用到工具top,vmstat,iostat,sar等。每一个工具的输出都从不同的方面反映除系统的性能情况。
Linux性能监控情况1:同一时间进行大量的I/O操作
在这种情况时我们会发现CPU的wa时间百分比会上升,证明系统的idle时间大部分都是在等待I/O操作。
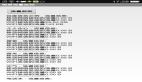
# vmstat 1
procs -----memory----- ---swap---io---- --system--cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
3 2 0 55452 9236 1739020 0 0 9352 0 2580 8771 20 24 0 57
2 3 0 53888 9232 1740836 0 0 14860 0 2642 8954 23 25 0 52
2 2 0 51856 9212 1742928 0 0 12688 0 2636 8487 23 25 0 52
从这个输出我们可以看到CPU有50%的时间都在等待I/O操作,我们还可以看到系统的bi值很大,证明系统有大量的I/O请求将磁盘内容读入内存。
没有很好的工具能看到到底是哪个进程在进行I/O读写。但我们可以通过top命令的输出来猜测
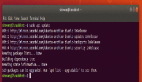
# top -d 1
top - 19:45:07 up 1:40, 3 users, load average: 6.36, 5.87, 4.40
Tasks: 119 total, 3 running, 116 sleeping, 0 stopped, 0 zombie
Cpu(s): 5.9% us, 87.1% sy, 0.0% ni, 0.0% id, 5.9% wa, 1.0% hi, 0.0% si
Mem: 2075672k total, 2022668k used, 53004k free, 7156k buffers
Swap: 2031608k total, 132k used, 2031476k free, 1709372k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ nFLT COMMAND
3069 root 5 -10 450m 303m 280m S 61.5 15.0 10:56.68 4562 vmware-vmx
3016 root 5 -10 447m 300m 280m S 21.8 14.8 12:22.83 3978 vmware-vmx
3494 root 5 -10 402m 255m 251m S 3.0 12.6 1:08.65 3829 vmware-vmx
3624 root 5 -10 401m 256m 251m S 1.0 12.6 0:29.92 3747 vmware-vmx
将top的输出通过faults进行排序。我们可以看到vmware产生最多的page faults。也就是说它进行了大量的IO操作。
Linux性能监控情况2:管道太小
任何I/O操作都需要一定的时间,而且这些时间对于硬盘来说是确定的,它包含磁盘旋转的延时RD(rotation delay)和磁头搜索时间DS(disk seek)。RD由磁盘转速(RPM)决定。RD是磁盘旋转一周所需时间的一半。如RPM为10000.
RPS=RPM/60=166
1/166=0.0006=6ms 磁盘旋转一周要6毫秒
RD=6ms/2=3ms
磁盘平均搜索时间是3ms,数据传输的平均延时是2ms,这样一次I/O操作的平均时间是:
3ms+3ms+2ms=8ms
IOPS=1000/8=125 这块磁盘的每秒IO数(IOPS)为125。所以对于10000RPM的磁盘来说它所能承受的IO操作在IOPS在120~150之间。如果系统的I/O请求超过这个值,就会使磁盘成为系统的瓶颈。
对与系统而言有两种不同种类的I/O压力,连续I/O和随机I/O。
连续I/O常常出现在企业级数据库这样的应用中,需要连续的读取大量数据。这种系统的性能依靠它读取和移动数据的大小和快慢。我们用iostat来监控,会发现rKB/s,wKB/s会很高。
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 12891.43 0.00 105.71 0.00 106080.00 0.00 53040.00 1003.46 1099.43 3442.43 26.49 280.00
从输出我们看到w/s=105,wKB/s=53040.所以53040/105=505KB per I/O.
对于随机I/O的系统来说性能的关注点不在搜传输数据的大小和速度,而是在磁盘的IOPS。这类系统的I/O请求比较小但是数量很大,如Web服务器和Mail服务器。他们的性能主要依赖每秒钟可处理的请求数:
# iostat -x 1
avg-cpu: %user %nice %sys %idle
2.04 0.00 97.96 0.00
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 633.67 3.06 102.31 24.49 5281.63 12.24 2640.82 288.89 73.67 113.89 27.22 50.00
从输出我们看到w/s=102,wKB/s=2640.所以2640/102=23KB per I/O.因此对于连续I/O系统来说我们要关注系统读取大量数据的能力即KB per request.对于随机I/O系统我们注重IOPS值.