互联网领域的实时计算一般都是针对海量数据进行的,除了像非实时计算的需求(如计算结果准确)以外,实时计算最重要的一个需求是能够实时响应计算结果,一般要求为秒级。个人理解,互联网行业的实时计算可以分为以下两种应用场景:
1) 数据源是实时的不间断的,要求对用户的响应时间也是实时的。
主要用于互联网流式数据处理。所谓流式数据是指将数据看作是数据流的形式来处理。数据流则是在时间分布和数量上无限的一系列数据记录的集合体;数据记录是数据流的最小组成单元。举个例子,对于大型网站,活跃的流式数据非常常见,这些数据包括网站的访问PV/UV、用户访问了什么内容,搜索了什么内容等。实时的数据计算和分析可以动态实时地刷新用户访问数据,展示网站实时流量的变化情况,分析每天各小时的流量和用户分布情况,这对于大型网站来说具有重要的实际意义。
2) 数据量大且无法或没必要预算,但要求对用户的响应时间是实时的。
主要用于特定场合下的数据分析处理。当数据量很大,同时发现无法穷举所有可能条件的查询组合或者大量穷举出来的条件组合无用的时候,实时计算就可以发挥作用,将计算过程推迟到查询阶段进行,但需要为用户提供实时响应[参考链接]。
2. 实时计算相关技术
互联网上海量数据(一般为日志流)的实时计算过程可以被划分为以下三个阶段:数据的产生与收集阶段、传输与分析处理阶段、存储对对外提供服务阶段。下面分别进行简单的介绍:

2.1 数据实时采集
需求:功能上保证可以完整的收集到所有日志数据,为实时应用提供实时数据;响应时间上要保证实时性、低延迟在1秒左右;配置简单,部署容易;系统稳定可靠等。
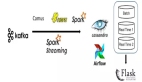
目前,互联网企业的海量数据采集工具,有Facebook开源的Scribe、LinkedIn开源的Kafka、Cloudera开源的Flume,淘宝开源的TimeTunnel、Hadoop的Chukwa等,均可以满足每秒数百MB的日志数据采集和传输需求。
2.2 数据实时计算
传统的数据操作,首先将数据采集并存储在DBMS中,然后通过query和DBMS进行交互,得到用户想要的答案。整个过程中,用户是主动的,而DBMS系统是被动的。

但是,对于现在大量存在的实时数据,比如股票交易的数据,这类数据实时性强,数据量大,没有止境,传统的架构并不合适。流计算就是专门针对这种数据类型准备的。在流数据不断变化的运动过程中实时地进行分析,捕捉到可能对用户有用的信息,并把结果发送出去。整个过程中,数据分析处理系统是主动的,而用户却是处于被动接收的状态。

需求:适应流式数据、不间断查询;系统稳定可靠、可扩展性好、可维护性好等。
实时流计算框架:Yahoo开源的S4、Twitter开源的Storm,还有Esper,Streambase,HStreaming等。
有关计算的一些注意点:分布式计算,并行计算(节点间的并行、节点内的并行),热点数据的缓存策略,服务端计算。
2.3 实时查询服务
全内存:直接提供数据读取服务,定期dump到磁盘或数据库进行持久化。
半内存:使用Redis、Memcache、MongoDB、BerkeleyDB等内存数据库提供数据实时查询服务,由这些系统进行持久化操作。
全磁盘:使用HBase等以分布式文件系统(HDFS)为基础的NoSQL数据库,对于key-value引擎,关键是设计好key的分布。
3. 应用举例
对于电子商务网站上的店铺:
1)实时展示一个店铺的到访顾客流水信息,包括访问时间、访客姓名、访客地理位置、访客IP、访客正在访问的页面等信息;
2)显示某个到访顾客的所有历史来访记录,同时实时跟踪显示某个访客在一个店铺正在访问的页面等信息;
3)支持根据访客地理位置、访问页面、访问时间等多种维度下的实时查询与分析。
更详细的内容,以后再进一步展开介绍。
4. 总结的话
1)并不是任何应用都做到实时计算才是最好的。
2)使用哪些技术和框架来搭建实时计算系统,需要根据实际业务需求进行选择。
3)对于分布式系统来说,系统的可配置性、可维护性、可扩展性十分重要,系统调优永无止境。
原文链接:http://www.cnblogs.com/panfeng412/archive/2011/10/28/2227195.html
【编辑推荐】