













【51CTO独家特稿】流式计算?云计算?最近各种计算让技术人员,特别是开发人员很头疼。其实这些名字已经慢慢变成现实,比如MapReduce,就已经成为了大型搜索引擎进行数据挖掘,数据分析的工具。
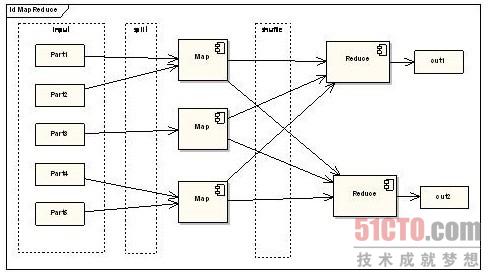
MapReduce结构图
互联网企业每天都在存储海量的非结构化数据和结构化数据,这些数据需要在短时间内被处理,否则就会让用户体验处于崩溃的边缘。好吧,MapReduce就被企业用来分布式处理这些数据,按照调度批量任务来操作静态数据。
流式计算呢?也跟MapReduce处理机制一样,把数据包分割成小块,然后通过并行计算的方式将这些数据快速处理。其实两者的差别在哪儿呢?
公交车PK大火车
MapReduce是严格按照调度命令来执行的,也就是说每一单位时间处理的数据量似乎是可定的。这就像铁路上的调度命令一辆18节的火车拉着旅客经过一个火车站,不管这个火车站上来多少人,火车还必须开走。这样的好处就是一次处理的数据量可以得到保证,但实时性较低,不能随着数据量的高低进行灵活变化。这一点似乎对于有些网站来说有些不可接受,因为这些站点经常会面对突如其来的流量高峰。
流式计算,根据定义的意思是可以理解为公交车。在开始的时候并没有乘客,经过若干站后数据进入到系统中,并被处理。流式计算希望乘客越快到达目的地越好,不用担心调度的相关命令。数据来了就尽快处理,不留下隐患。
这样流式计算就更能适应网站的流量高峰,因为不会根据调度命令死板的安排计算过程,数据被处理的速度很快。用户端的响应很快,让用户几乎没有抱怨的时间。
MapReduce真的要让位?
这么看来,流式计算比MapReduce更加灵活,MapReduce应该被尽快替代。51CTO认为这样的观点有其片面的理解。
诚然,流式计算更灵活,但势必比MapReduce多一些处理成本。MapReduce中的Hadoop已经被优化到***,其效率也不容小觑。在有些企业应用环境下,MapReduce这样更固定一些的处理机制意味着成本的控制度更好。
未来的分布式计算,MapReduce与流式计算代表的是不同需求下的不同方案。让这两者PK,还是要根据不同企业的不同需求。两者没有绝对意义上的优劣,只是在处理数据流程原则上的差异。
所以,要采用MapReduce还是流式计算,还是要看企业的数据来源具备什么样的特征。
【编辑推荐】















