













业务和管理需求使得数据中心管理和灾难恢复的缺陷更加明显。二十年前,用货车运输磁带进行存储就能满足需求了。十年前,两个数据中心的距离只要能进行I/O,就能满足需求。现在,随着电子商务成为首要的负载,恢复计划还得考虑数据中心的地理距离,这一点限制了恢复时间。
地理距离与数据中心管理
概念上,这是关于两个不同位置的数据中心,如图1所示。在数目也许会扩展到更多站点。
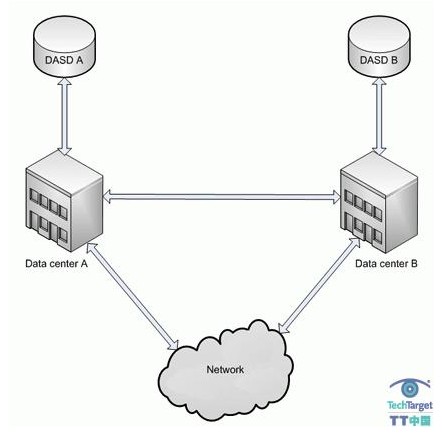
图1:地理性分离数据中心的示意图
图中两个数据中心是分离的,这对于进行同步磁盘输入输出来说,实在太远了,这导致了很多需求。首先每个数据中心必须得有自己的直接存取存储设备(Direct Access Storage Device,简称DASD)场所来进行管理。第二是同步硬件复制会因为网络延迟而无法工作。***,距离也意味着,每个数据中心的逻辑分区(logical partition,简称LPAR)不能处于同一个Sysplex(Systems Complex,系统联合体)里面。
网络在数据中心管理中占了重要位置,是两个数据中心之间的切换开关。有了合适的内部通讯系统,以后的要求都可以基于不同标准,按路线分给每个数据中心。其实,有了现在基于浏览器的应用,用户可以实现不同数据中心的不间断切换。
因为硬件复制不可用,数据必须在逻辑数据库或者访问方式(access method)的级别上被获取。有几个产品可以做这件事。部分产品得通过读数据库或Virtual Storage Access Method(简称VSAM)记录来升级。变更投到其他数据中心,通过通信线路使用多种的传输协议。在接收端,由另一个软件发给数据库或访问方式命令来完成远程升级。
为相隔两地的数据中心配置
分离的数据中心有好几种方式来配置,能想到的有以下几种:
Hot-warm
企业中一个数据中心被指派成为所有网络流量的目标。在***个数据中心的升级会被复制到第二个数据中心站点,第二个会接收并把这些改变用在本地的DASD场所。一旦***个数据中心故障,若第二个站点在线,混乱会降至***。
升级-查询
在升级-查询的方案中,一个数据中心地区全体升级,而其他只允许查询。升级的站点为只读的系统联合体及时带来改变。如果升级数据中心失败,负责查询的系统联合体得负全责。
网络在进行这种安装时,起决定性作用,它必须能问信息内容,来区分询问和升级事务。工作站可能也会使用网络来平衡负载,使每个数据中心能够带上属于自己的只读流量。
升级-升级
这是个实实在在的事。每个数据中心支持所有数据的所有升级。两种方式的复制流经通信连接,保持数据库的同步。一旦发生故障,没有出问题的数据中心承担所有即将到来的流量。
注意当两个数据中心都升级时,数据在逻辑上可能会分离。比如说对用户的初级数据库在密西西比河西边的“A数据中心”,第二个只读的数据在“B数据中心”。用户在哪一边都可能是反向的。最终,这意味着网络必须足够智能,知道客户的初级数据在哪。
其他的问题
相信各位深思熟虑的读者已经想到不少这些问题。但是还有更多令人不安的不稳定因素。
批处理——在升级-升级的模式下,生产量会问题多多。企业得决定哪一方进行批处理,如果批处理两方都得进行就更头疼了。还得考虑对带宽的需求,用以从I/O相关批处理事务中挤出空间升级,通过复制链接。
复制的延迟——现代通信连接又快有可靠,但还会有问题。就算是最快最***的通信线也不能和DASD I/O一样同步和快速。因此,系统基础架构和一部分应用必须准备好应对延迟和“过时”的数据。
冲突问题——数据库管理系统(Database Management Systems,简称DBMS)在不同的系统联合体中,不能从太宽的距离锁定数据库记录。这导致在不同数据中心内,相同的数据库记录可能会同时升级。基础设施和应用需要准备好应对混乱。
控制改变——基础设施、应用和数据库设计的改变一定得认真管理,避免破坏在不同数据中心复制的一致性。
漂移——没有异步复制技术在逻辑I/O层面是***的,企业会发现分叉数据存储变慢。整理这些不同需要周期性的调和进程。
死亡——对于数据中心来说,什么算死?数据中心通过复制流量和heartbeat来保持联系。但是复制流量的减慢可能预示着一个数据中心工作做的少了。同样地,一些遗落的heartbeat也暗示着网络故障或减慢,而不是数据中心故障。
探查和遵照这些察觉到的故障来行事,要求精心策划的政策、高度自动化和仔细的管理。好消息是数据中心的地理分离逐渐变得平常,解决这些问题的政策也变得更加便于学习。
















