












引 言
随着XML技术在各种应用领域中广泛的使用,越来越多的数据以XML文档形式呈现。如何对海量的XML文档进行有效管理,已成为人们所研究的热点。目前,主要有两类技术来管理大批量XML文档,分别是XML原生数据库技术和关系数据库扩展技术。前者主要以开源软件居多,且内部多依靠Xpath、XQuery技术实现,现已有eXist、MonetDB/XQuery和BaseX等十余款产品;后者基本上是成熟的商业关系数据库,通过附加插件的方式,以增加对XML文档管理的能力,代表产品有IBM的PureXML、Oracle的XDK等。
伴随着XML文档管理技术的发展,衡量各种技术的处理效率的要求也日益增长。XML基准测试是一种衡量XML文档管理技术的测试方法。对开发者而言,通过XML基准测试,可以衡量已有技术的处理效率,对未来的开发有指导意义;对用户来说,它的结果是选择XML文档管理产品时的可靠依据。
XML基准测试简介
从1999年FK提出XML 数据向关系数据库映射效率问题起,到2001年首个开源产品Xmach-1面世,再到2007年首个有工业支持背景的TpoX,其间出现了多种XML基准测试。截止2010年,共有Xmach-1、Xmark、MBench等十余款产品面世。其设计出发点、测试重点、实现机制各不相同。本文挑选了在实际应用中获得广泛使用的五种主流基准测试作为研究对象进行阐述。
Xmach-1是莱比锡大学E. Rahm与T. Böhme在2000年研发的一款多用户基准测试。其系统框架包括XML数据库、应用服务器、数据负载器和用户端浏览器。其不仅是第一款开源产品,也是第一款面向多用户的基准测试。
Xmark是CWI小组的R. Busse、M. Carey等人在2003年提出的。它是单用户级别的基准测试。它模拟了一个网络拍卖的应用环境。与其他测试不同的是,它只采用了一个容量可伸缩,最大可达10GB的XML文件,作为测试基础数据。
Xbench是滑铁卢大学B.Yao与M. Tamer Özsu等人与2002年提出。其将实际中的XML文档应用,按单、多文档和数据集中、文本集中等特征进行交叉划分,分为四类应用类型。基于各种类型,有不同的测试策略。
XOO7是在完善的OO7基准测试的基础上,U. Nambiar等人在2001年扩充完成的。其出发点是测试基于面向对象技术的数据库管理系统,对XML文档的处理能力。
TpoX是M. Nicola和A. Gonzalez等人在2007年提出的。与前述基准测试不同,TpoX项目的参与人员均来自商业公司,是第一款有工业背景的基准测试。它模拟了一个多用户的金融应用环境。
比较与分析
尽管各种测试的研发出发点和实现技术各不相同,但其执行流程都遵循如下顺序:先生成测试场景,再基于场景生成测试基础数据,最后再使用XQuery对数据进行操作,即输出最终的测试用例。以下也从该三方面进行比较与分析。
测试场景
测试场景是与待测试软件的执行相对应的一个活动场景,由一系列活动按照一定的顺序组成,它描述了系统的典型活动过程,是系统业务特性的一种体现。一个设计优秀的测试场景,将使测试更符合实际使用情况,揭示出产品在现实应用中的真实表现。
Xmach-1的测试场景是构建了一个多用户的图书论文管理系统,共有目录文档和受管文档两类文档,其各自又包含结构化数据和文本数据两种数据类型。测试场景映射为数据库的ER图后,包含文档、题目、章节、作者名等共8个实体,及这些实体之间的18个相互关系。
Xmark的测试场景是构建了一个单用户的网络拍卖站点,模拟一个注册用户从挑选拍卖品开始,到出价定拍结束的整个流程。其主要实体有注册用户、拍卖品、出价等共6个,其之间交互关系有9个。
Xbench将测试场景依据应用特性和数据特性分为四类:DC/SD、DC/MD、TC/SC和TC/MD。其分别模拟不同的在线应用,如DC/SD模拟一个在线购物网站,DC/MD为B2B系统。但总体来说,其性质还是偏向电子商务类的应用系统。四类中最为复杂的DC/SD,其实体包括日期、发布者等十余个,关系也达到了数十个。从数量上来说,是五种基准测试中最多的。
XOO7可以说是OO7基准测试的XML版,其测试场景也是依据OO7而设定。构建了一个用户交互频繁的电子商务系统。实体包括用户信息、基本汇集信息等共11个,关系也达到了42条。是本次比较中,实体数仅次于Xbench的。
TpoX是五种基准测试中面世最晚的,其在场景设计中,也借鉴了先前各种方法的经验。它仍然是构建一个基于Web的电子商务系统,但其实体数只有用户、账户等共5个,其关系没有事先指定,而是封装在了41个外部的XSD文件中。这样,在测试过程中,可以从XSD文件中灵活地选择搭配,来组合出符合测试者关注点的测试场景。
测试数据
测试数据是指依据已有的测试场景,遵循实体--关系的定义,自动生成的大批量基础数据。是在实际测试前,生成并输入到数据库中,做为测试用例的数据输入。衡量测试数据是否有效,一般从数据量和数据生成方式两方面进行。过小规模的数据量,无法模拟真实的使用环境;通过简单的随机方式生成的数据,也无法有效地反映XML文档管理系统的处理效率。
表1从默认数据集容量、生成方式及种子来源三个方面对五种基准测试进行了比较。
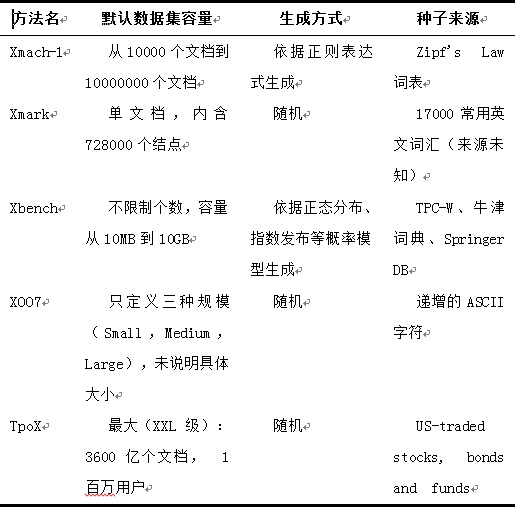
表1 测试数据比较
XQuery支持
W3C于2001年12月提出了XML查询语言规范—XQuery语言。XQuery是一种对XML结构的文档和数据进行查询的语言,它汲取了其它多种查询语言的优点,适用于各种类型的XML数据源的查询,而且简洁灵活易于实现。
当前几乎绝大多数的XML文档管理系统,都是基于XQuery来实现对XML文档的CRUD操作。相应的,五种基准测试均不同程度上使用了XQuery技术,来生成测试用例,以检验XML文档管理的处理效率。
W3C制定的XML Query Use Case中举出了XQuery操作实例,五种基准测试均借鉴了其操作方式。为便于比较,将操作实例映射为数据库的增加、查询、更新与删除操作(CRUD)。表2给出了各基准测试对XQuery支持的情况。
需要指出的是,所生成的XQuery,依赖于被测的XML文档管理系统。如TpoX所生成的XQuery查询语句针对DB2进行了许多优化,使得其七个语句充分扩展后,可以支持CRUD四种操作。

测试数据比较
3 现有问题
XML基准测试目前已经在众多实际XML数据集中的项目中,得到广泛应用:Amsterdam大学在ILPS项目中使用了xmach-1;Berkeley大学的B. Yanbin等人的XSet搜索引擎中使用了XBench;TPox在10T数据规模的实验室环境中,成功地进行了测试。
尽管XML基准测试在实际应用有不错的表现,但其仍存在一些问题:
1)生成的部分XQuery语句已经过时,与W3C标准不兼容
L. Afanasiev以Galax、SaxonB等以Native XML数据库存储XML文档,进行了XMach-1、XOO7共5款基准测试,发现在总共生成的163个XQuery语句中,有62个不符合W3C标准。XOO7由于开发版本较早,其22个语句竟然无一符合。
由于XML具有高度的自由性,尽管不符合W3C标准,仍能被处理。但W3C标准代表了业界开发标准,越来越多的产品以W3C标准作为开发规范。XML基准测试如不能与W3C标准较好兼容的话,其测试结果将不能真实体现这些产品的实际性能。
2)测试场景单一,与实际使用的系统相差较大
按测试场景的应用领域来分,Xmach-1模拟了图书论文管理系统,其余四款均是模拟了在线的电子商务系统。但对近年来大规模应用XML的社交网络、e-learning系统,以上五种测试均未涉及。此外,在已模拟的电子商务场景中,各种测试生成的模拟操作均是成功的流程用例。但实际环境中,存在大量的交易取消和交易失败的情况。Xbench对场景进行了细分,是五种测试中场景定义最好的,但也存在生成的用例,难以达到复杂应用对系统输入的要求。
3)测试数据类型只基于ASCII码;内容缺乏针对性;生成方式单一
五种基准测试生成的测试数据,绝大多数都是基于ASCII字符集的英文语系内容,没有设计其他语种的文字内容。在软件开发国际化要求越来越突出的背景下,不支持多语种大字符集(如Unicode)的基准测试,很难得到广泛应用。
此外,测试数据的内容过于宽泛,缺乏针对性。在使用非随机数的基准测试中,Xmach-1使用的是纯词频优先方式,对出现在主流报刊的词汇进行挑选;Xbench选择了牛津词典作为数据来源;Xmark与Xmach-1类似,将常见的词汇作为数据来源。这样所选取的数据,内容覆盖过广,缺乏代表性,不能较好体现被测系统所面向特定领域的特点。如药品的拉丁文英文译名在实际情况下,极少出现在一家出售家用电器的B2B系统中。
生成方式单一也有可能会导致数据质量不高。除Xbench使用了概率模型,其他几种主要使用了随机生成方法。由于随机种子的限制,很难保证数据不出现重复。而数据重复现象,在TB级别的数据生成时,将较大影响测试效果。
结 论
XML基准测试是一种衡量XML文档管理技术的测试方法。本文从测试场景、测试数据和对XQuery支持三方面对五种主流的XML基准测试进行了比较与分析。此后,指出了其现存的问题。
XML基准测试在实际应用中使用频率逐渐增加,日益得到人们认可。如能在未来的研发过程中,不断完善功能,弥补自身现有缺陷,将成为评测XML文档管理技术的有力工具。
















