之前在微博上调查过大家正在使用的分布式内存队列系统,反馈有Memcacheq,Fqueue, RabbitMQ, Beanstalkd以及linkedin的kafka。RabbitMQ使用比较广泛,Beanstalkd是后起之秀。Beanstalkd之于RabbitMQ,就好比Nginx之于Apache,Varnish之于Squid。后面在项目中使用Beanstalkd的过程中,更发现其简单、轻量级、高性能、易使用等特点,以及优先级、多队列、持久化、分布式容错、超时控制等特性。下面就简单介绍一下Beanstalkd,不足之处请大家指正。
设计思想
高性能离不开异步,异步离不开队列,而其内部都是Producer-Comsumer模式的原理。
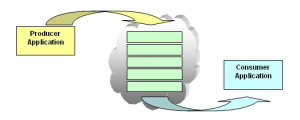
图1 Producer-Comsumer模式
应用
Beanstalkd,一个高性能、轻量级的分布式内存队列系统,最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web应用系统的页面访问延迟,支持过有9.5 million用户的Facebook Causes应用。后来开源,现在有PostRank大规模部署和使用,每天处理***任务。Beanstalkd是典型的类Memcached设计,协议和使用方式都是同样的风格,所以使用过memcached的用户会觉得Beanstalkd似曾相识。
核心概念
Beanstalkd设计里面的核心概念:
◆ job
一个需要异步处理的任务,是Beanstalkd中的基本单元,需要放在一个tube中。
◆ tube
一个有名的任务队列,用来存储统一类型的job,是producer和consumer操作的对象。
◆ producer
Job的生产者,通过put命令来将一个job放到一个tube中。
◆ consumer
Job的消费者,通过reserve/release/bury/delete命令来获取job或改变job的状态。
Beanstalkd中一个job的生命周期如图2所示。一个job有READY, RESERVED, DELAYED, BURIED四种状态。当producer直接put一个job时,job就处于READY状态,等待consumer来处理,如果选择延迟put,job就先到DELAYED状态,等待时间过后才迁移到READY状态。consumer获取了当前READY的job后,该job的状态就迁移到RESERVED,这样其他的consumer就不能再操作该job。当consumer完成该job后,可以选择delete, release或者bury操作;delete之后,job从系统消亡,之后不能再获取;release操作可以重新把该job状态迁移回READY(也可以延迟该状态迁移操作),使其他的consumer可以继续获取和执行该job;有意思的是bury操作,可以把该job休眠,等到需要的时候,再将休眠的job kick回READY状态,也可以delete BURIED状态的job。正是有这些有趣的操作和状态,才可以基于此做出很多意思的应用,比如要实现一个循环队列,就可以将RESERVED状态的job休眠掉,等没有READY状态的job时再将BURIED状态的job一次性kick回READY状态。
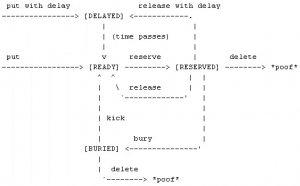
图2 Beanstalkd中job的生命周期
特性
Beanstalkd基于的源码安装和使用很简单,在此略过。这里重点介绍一下其几个很nice的特性。
◆ 优先级
支持0到2**32的优先级,值越小,优先级越高,默认优先级为1024。
◆ 持久化
可以通过binlog将job及其状态记录到文件里面,在Beanstalkd下次启动时可以通过读取binlog来恢复之前的job及状态。
◆ 分布式容错
分布式设计和Memcached类似,beanstalkd各个server之间并不知道彼此的存在,都是通过client来实现分布式以及根据tube名称去特定server获取job。
◆ 超时控制
为了防止某个consumer长时间占用任务但不能处理的情况,Beanstalkd为reserve操作设置了timeout时间,如果该consumer不能在指定时间内完成job,job将被迁移回READY状态,供其他consumer执行。
不足
在使用中发现一个Beanstalkd尚无提供删除一个tube的操作,只能将tube的job依次删除,并让Beanstalkd来自动删除空tube。还有就是Beanstalkd不支持客户端认证机制(开发者将应用场景定位在局域网)。
后续工作
1.介绍Beanstalkd的命令和使用
2. 翻译Beanstalkd协议
3. 分析Beanstalkd源码
原文:http://rdc.taobao.com/blog/cs/?p=1201
【编辑推荐】