本文我们主要介绍OPEN SOURCE数据库集群中间件CJDBC,通过它,我们可以方便地实现RAIDb - Redundant Array of Inexpensive Database 廉价数据库冗余阵列。 接下来就让我们一起来了解一下这部分内容。
由于CJDBC是一个JDBC的实现,所以偶们原先的应用不需要做任何的代码改动,只需要更换配置文件即可。 CJDBC有几种RAIDb的机制可以选择(只说3种偶了解的):
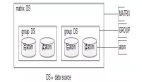
1. RAIDb-0
数据库中单个的table只分布在单个节点,没有任何的冗余阵列,但是不同的table可以分散在不同的节点,这样偶们可以把某些需要频繁查询的表分布在比较强劲的,loading比较轻的PC上。这种机制带来了查询性能的稍许提高,但是没有提供容错处理 (fault tolerance) 。

2. RAIDb-1
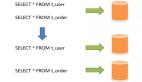
完全镜像处理机制,每个节点上都有完整的数据库结构,这种方式提供了***的容错处理,并且通过设置合理的Loading Balance策略,可以带来查询性能相当好的提高。但是由于对于任何的写操作(create/update/delete),需要在各个节点上进行传播复制,写操作就会比原来慢一些了。

3. RAIDb-2
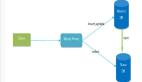
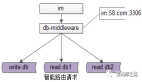
对于RAIDb-0和RAIDb-1的一个折中,看一下示意图就明白它了:

为了避免CJDBC controller成为容错处理中的single point of failure,CJDBC还提供了controller replication,它利用JGroups ( http://www.jgroups.org/ )做各个CJDBC controller节点的通讯(这个偶没有试验过,有兴趣的可以试试看)偶们使用CJDBC的实际项目目前有3个mysql database的节点(都是普通的PC),读/写操作的比例很高,CJDBC非常合适这种项目,随着并发用户人数的增加,用户只需要花个4000RMB左右的钱,购买一台PC加入到集群中,就可以应付了,确实是一个廉价的解决方案。
关于OPEN SOURCE数据库集群中间件CJDBC的使用就介绍到这里了,希望本次的介绍能够带给您一些收获!
【编辑推荐】