MongoDB是怎么实现数据的备份与恢复,故障切换以及数据库服务器的负载均衡等功能的呢?本文我们就介绍这些知识。
备份与恢复
在创建MongoDB服务的时候,通过--dbpath指定目录就是存放mongdb数据库文件目录,我们可以通过复制这些文件实现数据库的冷备,但是这种方式不太安全。因此在冷备前,要关闭服务器,这个在第一节中介绍过平滑关闭server的命令。
- >use admin
- >db.shutdownServer()
或者可以通过fsync方式使MongoDB将数据写入缓存中,然后再复制备份
- >use admin
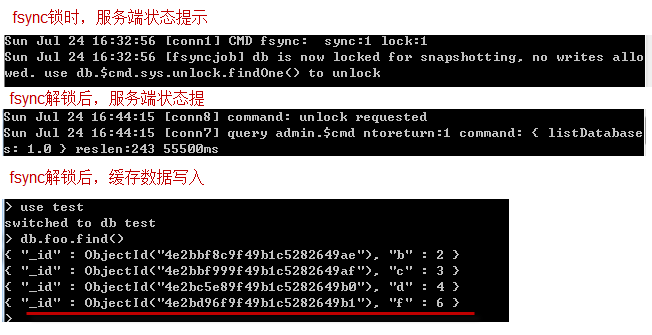
- >db.runCommand({"fsync":1,"lock":1})
这个时候我往test.foo 插入了一条数据 f:6 ,在执行db.foo.find()后,并没有查到这条记录,说明记录没有直接写入数据库,而是被缓冲到缓存中了。
备份完后,要解锁(防止这个时候停电或其它原因,导致未缓存中的数据丢失)。
- >use admin
- >db.$cmd.sys.unlock.findOne()
- >db.currentOp() 如果currentOp 只返回{"inprog":[]}结果,说明解锁成功。
解锁后,缓存中的数据会写入数据库文件中,我们去查询foo结果。
上面是冷备的方式,我们可以在不停止服务的情况下,使用MongoDB提供的两个工具来实现备份和恢复。这个两个工具在MongoDB的bin目录下可以看到:mongodump.exe/mongorestor.exe
mongodump.exe备份的原理是通过一次查询获取当前服务器快照,并将快照写入磁盘中,因此这种方式保存的也不是实时的,因为在获取快照后,服务器还会有数据写入,为了保证备份的安全,同样我们还是可以利用fsync锁使服务器数据暂时写入缓存中。
备份命令:
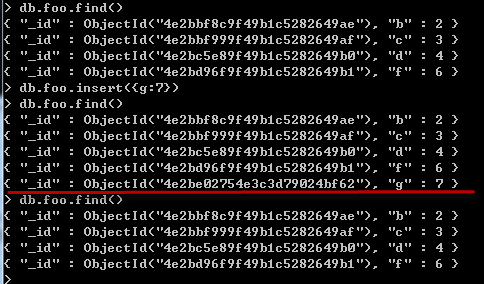
- ......bin>mongodump -d test -o backup //( backup是备份目录,默认创建到bin目录)
恢复命令: (可以在恢复前往foo表插入一条记录 g:7)
- .....bin>mongorestore -d test --drop backup/test/
看一下运行结果:
以上就是mongodb的备份和恢复过程。当数据库文件出现问题或者损坏时,MongoDB还提供了修复数据文件的命令。
在启动mongod服务时通过--repair 修改:
- ....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\master" --repair
另外我们也可以在mongo shell 中修复正在运行的数据库存
- >use test
- >db.repairDataBase()
#p#
接下来我们在来看一下另外二种读扩展式的备份机制。
Master-Slave
主从复制模式:即一台主写入服务器,多台从备份服务器。从服务器可以实现备份,和读扩展,分担主服务器读密集时压力,充当查询服务器。但是主服务器故障时,我们只能手动去切换备份服务器接替主服务器工作。这种灵活的方式,使扩展多如备份或查询服务器相对比较容易,当然查询服务器也不是无限扩展的,因为这些从服务器定期在轮询读取主服务器的更新,当从服务器过多时反而会对主服务器造成过载。
我们以之前创建的端口为27017做为主服务器,再创建个端口为27018从服务器
重新启动27017为主服务器 --master 主服务器
- ....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\master" --master
创建27018为从服务器 --slave 从服务器 --source 指定主服务器
- ....bin>mongod --port 27018 --dbpath "C:\Program Files\mongodb\data\dbs\slave27018" --slave --source localhost:27017
主服务器可以通过自己local库的slave集合查看从服务器列表
从服务器可以通过自己local库的source集合查看主服务器信息或维护多个主服务器。 (一个slave服务器可以服务多个master服务器)
或者我们可以通过http console查看状态
Replica Sets
副本集模式:具有Master-Slave模式所有特点,但是副本集没有固定的主服务器,当初始化的时候会通过多个服务器投票选举出一个主服务器。当主服务器故障时会再次通过投票选举出新的主服务器,而原先的主服务器恢复后则转为从服务器。Replica Sets的在故障发生时自动切换的机制可以极时保证写入操作。
创建多个副本集节点 --replSet (注意要区分大小写,官方建议命名空间使用IP地址)
- ....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\replset27017" --port 27017 --replSet replset/127.0.0.1:27018
- ....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\replset27018" --port 27018 --replSet replset/127.0.0.1:27017
- ....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\replset27019" --port 27019 --replSet replset/127.0.0.1:27017
首先建立3个是为了投票不会冲突,当服务器为偶数时可能会导致无法正常选举出主服务器。
其次上面3个replset 节点没有全部串联起来,是因为replset 有自检测功可以自动搜索连接其它服务器。
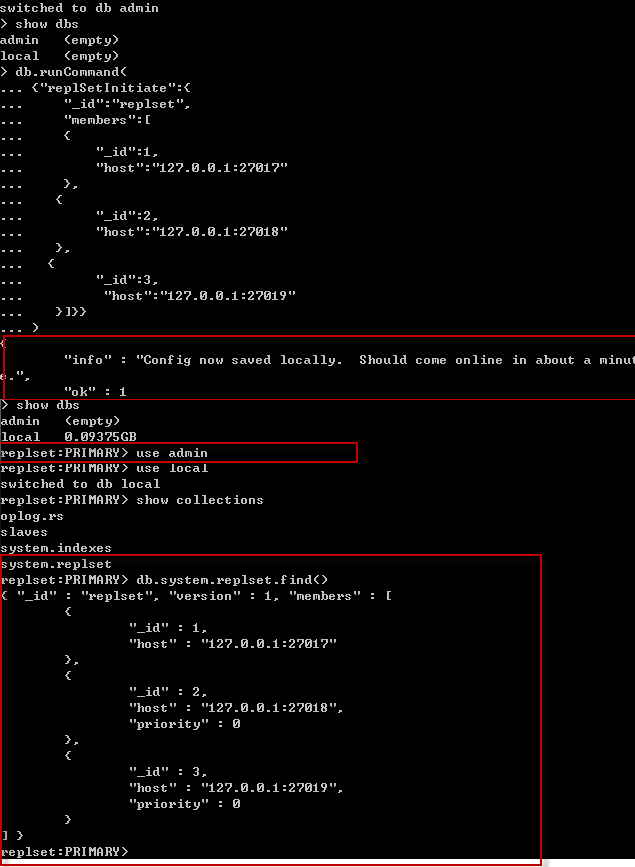
完成上面的工作后,要初始化副本集,随便连接一台服务器执行以下命令 (priority 0~1,被选为主服务器的优先级)
- >use admin
- >db.runCommand(
- {"replSetInitiate":{
- "_id":"replset",
- "members":[
- {
- "_id":1,
- "host":"127.0.0.1:27017",
- "priority":1
- },
- {
- "_id":2,
- "host":"127.0.0.1:27018",
- "priority":1
- },
- {
- "_id":3,
- "host":"127.0.0.1:27019",
- "priority":1
- }]}}
- )
查看结果,可以看出127.0.0.1:27017 被自动选为replSet:Primary>
在增加一个从服务器节点
- ....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\replset27020" --port 27020 --replSet replset/127.0.0.1:27017
通过rs.add命令往system.replset添加新的从服务器成员
- rs.add("127.0.0.1:27020"); 或者rs.add({"_id":4,"host":"127.0.0.1:27020"})
这里在简单的介绍一下Master Slave/ Replica Sets 备份机制,这两种模式都是基于主服务器的oplog 来实现所有从服务器的同步。
oplog记录了增删改操作的记录信息(不包含查询的操作),但是oplog有大小限制,当超过指定大小,oplog会清空之前的记录,重新开始记录。
Master Slave方式主服备器会产生 oplog.$main 的日志集合。
Replica Sets 方式 所有服务器都会产生oplog.rs 日志集合。
两种机制下,所有从服务器都会去轮询主服务器oplog日志,若主服务器的日志较新,就会同步这些新的操作记录。但是这里有个很重要的问题,从服务器由于网络阻塞,死机等原因无法极时同步主服务器oplog记录:一种情况 主服务器oplog不断刷新,这样从服务器永远无法追上主服务器。另外一种情况,刚好主服务器oplog超出大小,清空了之前的oplog,这样从服务器就与主服务器数据就可能会不一致了,这第二种情况,我是推断的,没有证实。
另外要说明一下Replica Sets 备份的缺点,当主服务器发生故障时,一台从服务器被投票选为了主服务器,但是这台从服务的oplog 如果晚于之前的主服务器oplog的话,那之前的主服务器恢复后,会回滚自己的oplog操作和新的主服务器oplog保持一致。由于这个过程是自动切换的,所以在无形之中就导致了部分数据丢失。
关于MongoDB备份与恢复的知识就介绍到这里了,希望能够带给您收获。
【编辑推荐】