继上一篇我们介绍了:SQL SERVER数据挖掘之理解聚类算法和顺序聚类算法,这一篇我们介绍SQL SERVER数据挖掘的***一部分内容,就是如何实现Web路径流挖掘。我们接下来就通过一个实例来分析这一过程。
Web路径流是让我们发现用户使用网站的习惯的一种表示方式,例如我们想知道用户是先到什么页面,然后再到什么页面,由此我们可以给用户分组,并且根据他们的习惯定制更好的页面导航设计。
按照数据挖掘的基本流程,我们一步一步来做:
1.定义问题:通过分析得到不同用户群使用网站的路径及其规律
2.准备数据:
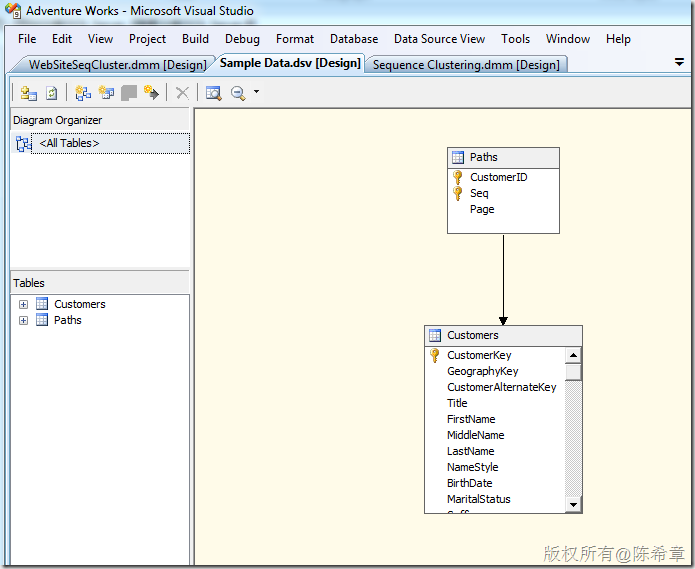
为此,我们准备两个表格,分别保存客户信息(如下)
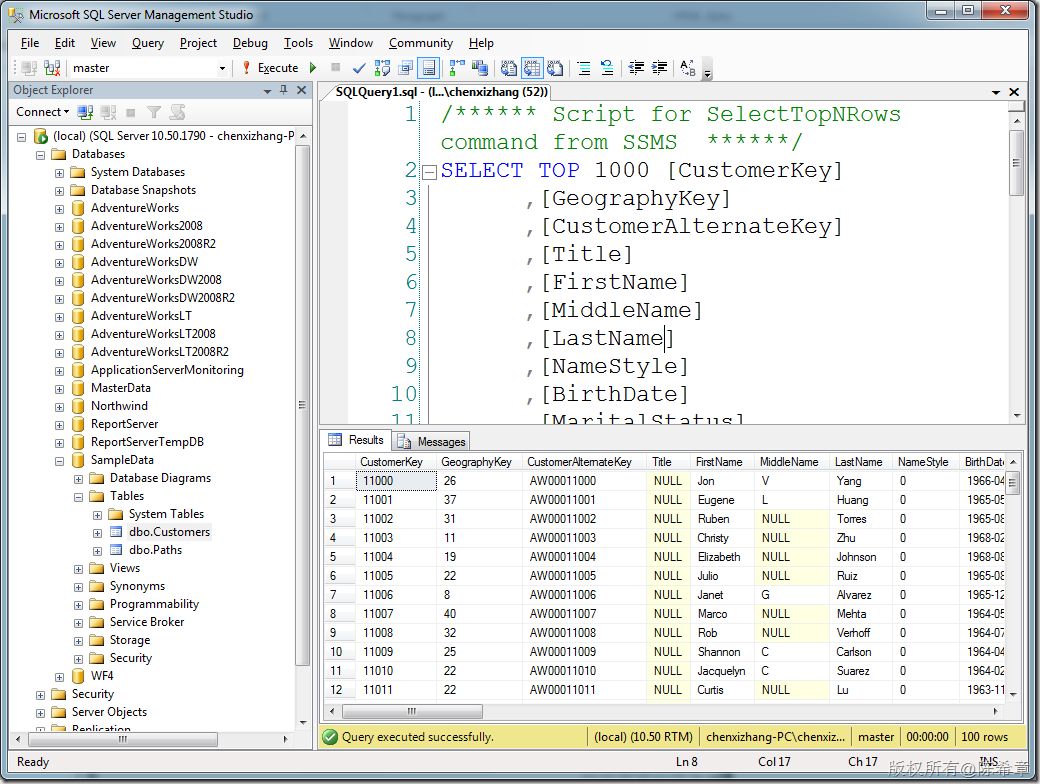
以及客户点击页面的记录表(这里作为演示,我只填写了一些范例数据)
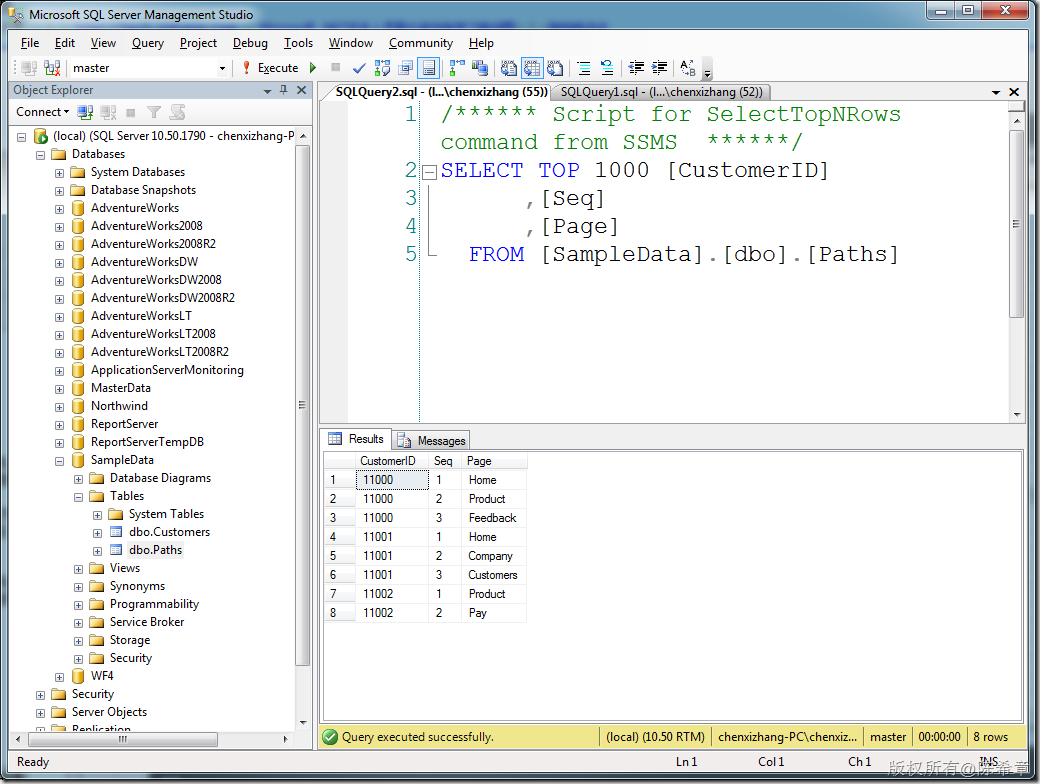
3.建立模型:
准备数据源和数据源视图
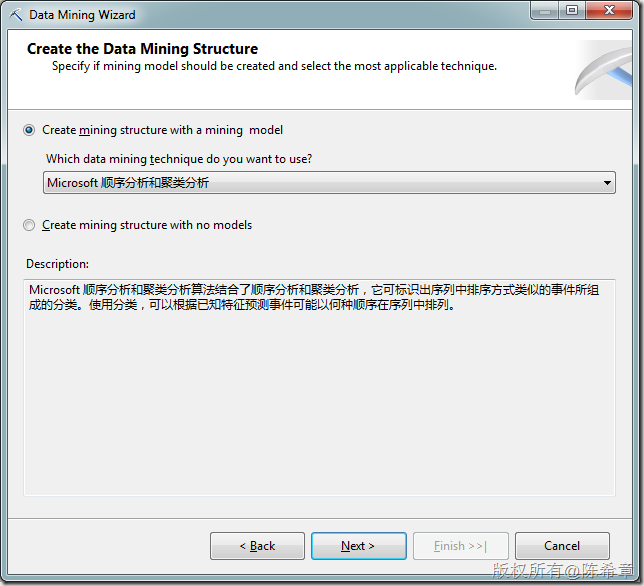
创建挖掘模型。这个业务场景,我们适合用“顺序分析和聚类分析”
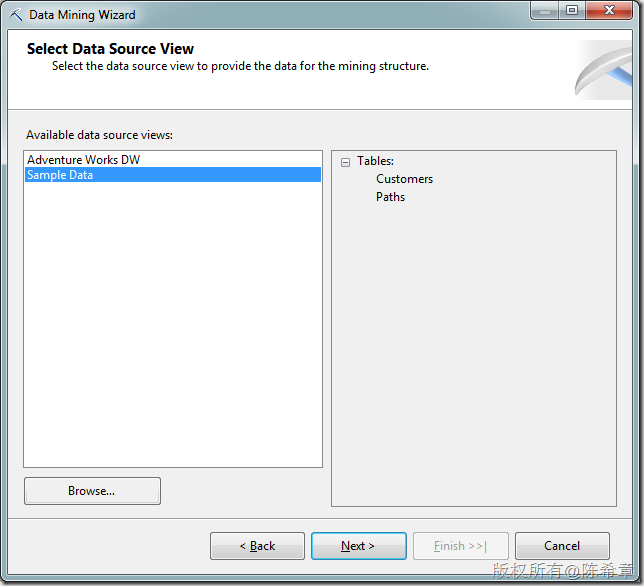
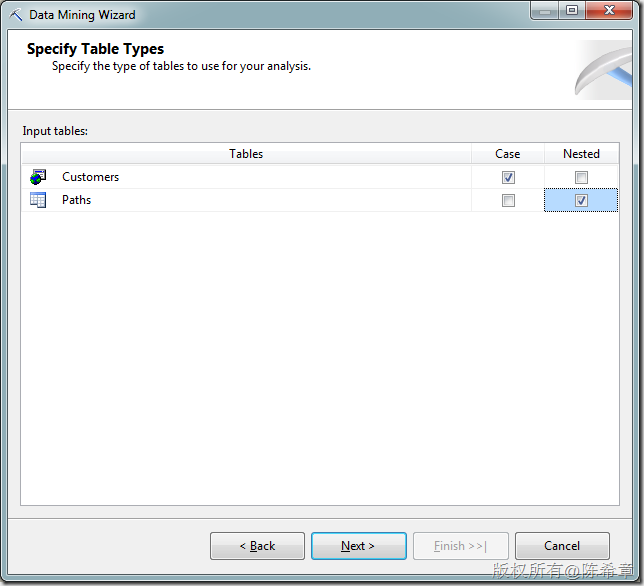
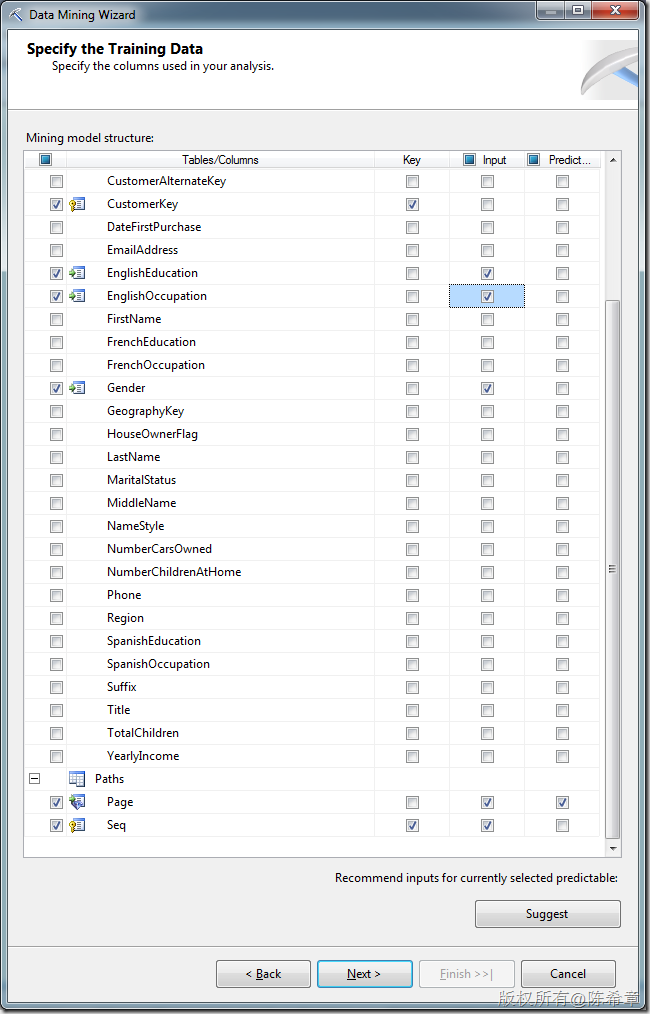
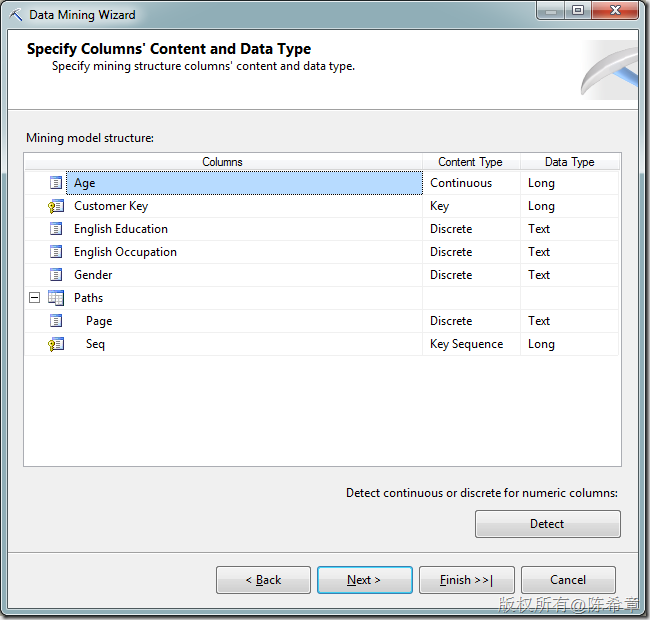
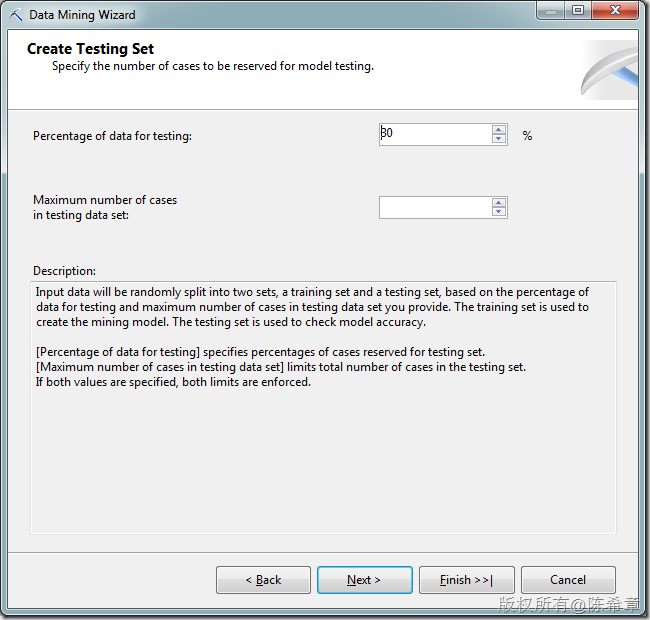
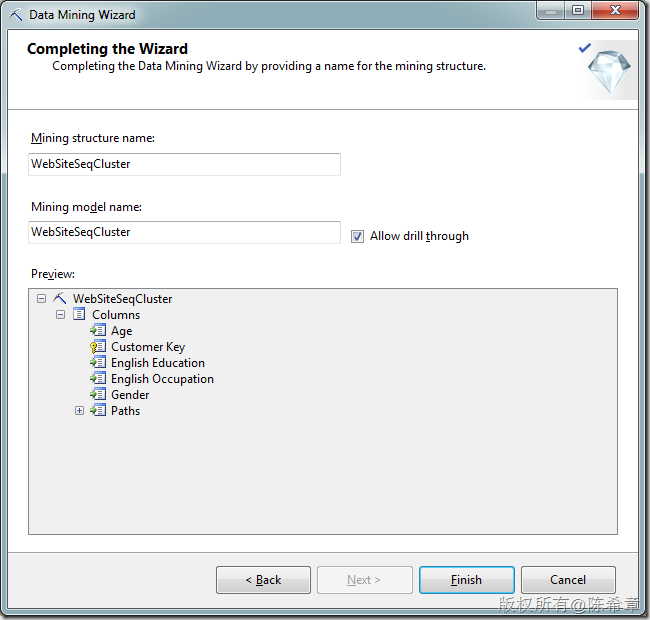
点击“Finish”之后,检查模型的设计
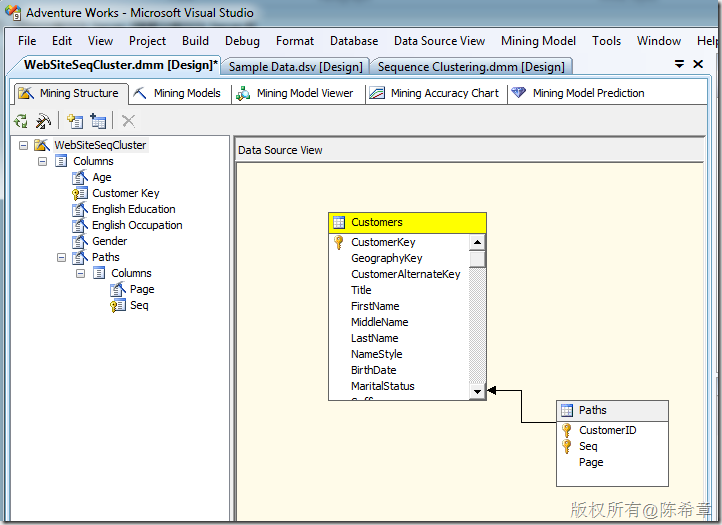
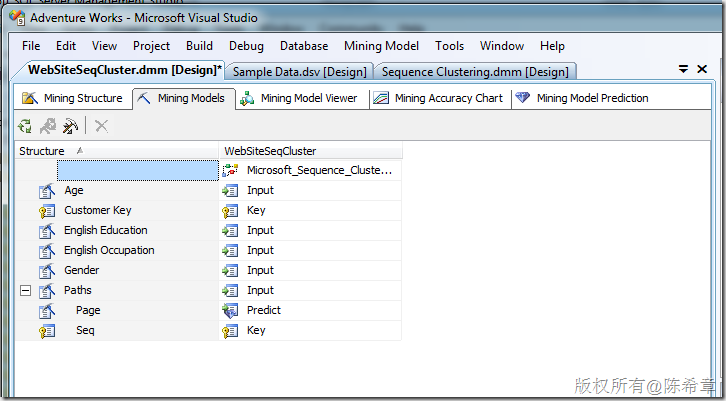
4.部署和处理
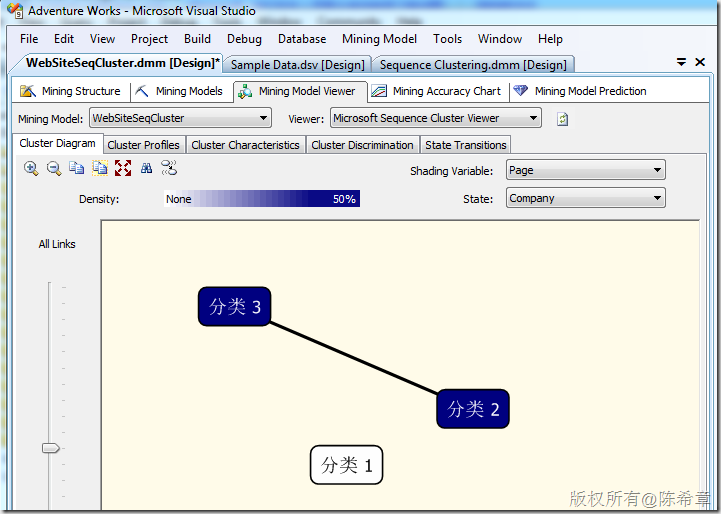
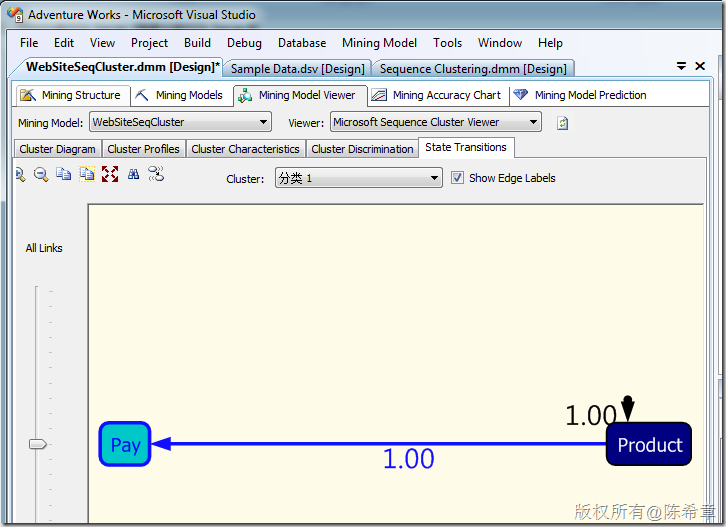
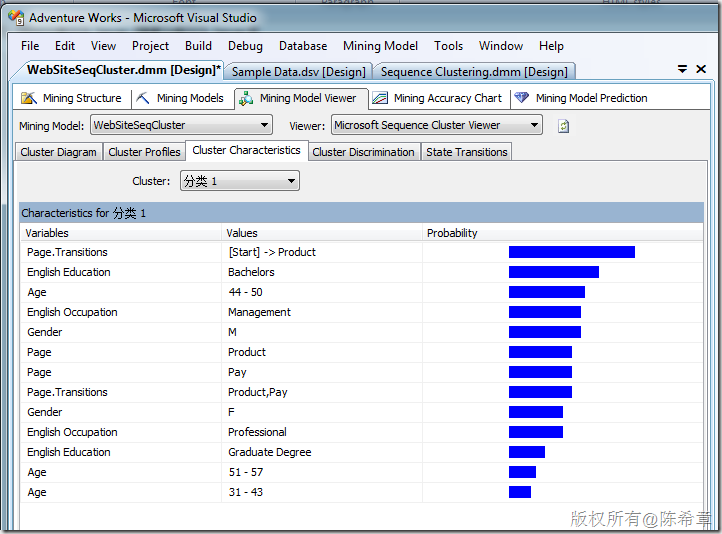
【备注】因为数据不多,所以看到的结果比较简单。有兴趣的朋友可以实际准备一些数据进行分析。
关于SQL SERVER数据挖掘的问题我们就介绍到这里了,希望通过这几次的介绍,能让您有所收获,因为您的收获就是对我们工作***的肯定,谢谢!
【编辑推荐】