












继上次我们介绍了:SQL SERVER 数据挖掘之理解内容类型,这次我们介绍SQL SERVER数据挖掘之理解列的用法。
这是一个小的细节问题,我们在定义挖掘模型的时候,会指定不同的列的用法,基本上有如下几种:
- Ignore(忽略)
- Input(输入)
- Predict(预测)
- PredictOnly(仅预测)
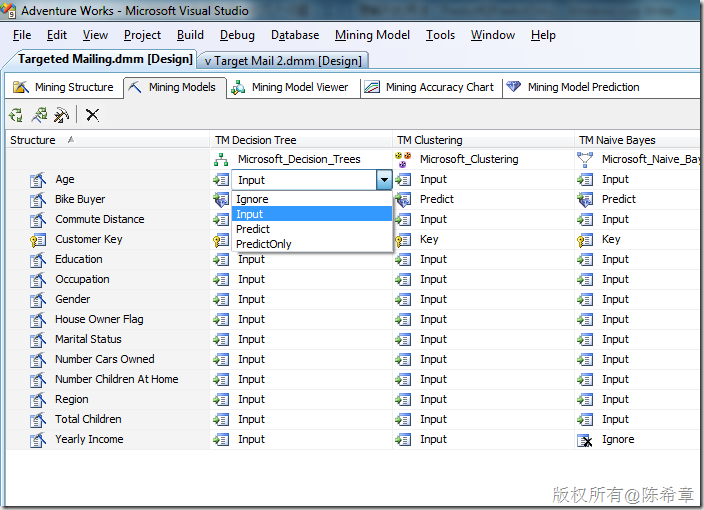
前面两个很容易理解,“忽略”就是说这个列不在当前算法中使用,例如某些列在某些算法里面不受支持。而“输入”则是最常见的一种用法,就是说这个列作为算法作为预测分析的输入数据。
关键在于如何理解“预测”与“仅预测”。
预测:这种列的意思是,该列既作为输入列(输入的数据),也作为输出列(预测的结果)。
仅预测:该列只作为输出列,不能作为输入列。也就是说它不会作为对其他因素做分析或者预测的因素。
这里面有两个主要层面的意思:
如果是选择“预测”这种用法,那么这种列可以作为“输入”的性质,对其他列(尤其是其他预测列)产生影响。而“仅预测”这种则是说自己只是仅仅作为预测的目的存在,它本身不能作为预测其他列的前提。
所以,如果有多个预测列(这在有的时候也是可能的),那么对于某些列,设置为“预测”而不是“仅预测”应该是很有必要的;而对于在模型中只有***的预测目标列时,可以设置为“仅预测”来提高模型的准确性和效率。
在对新数据做预测的时候,我们也可以看到这样的意思:
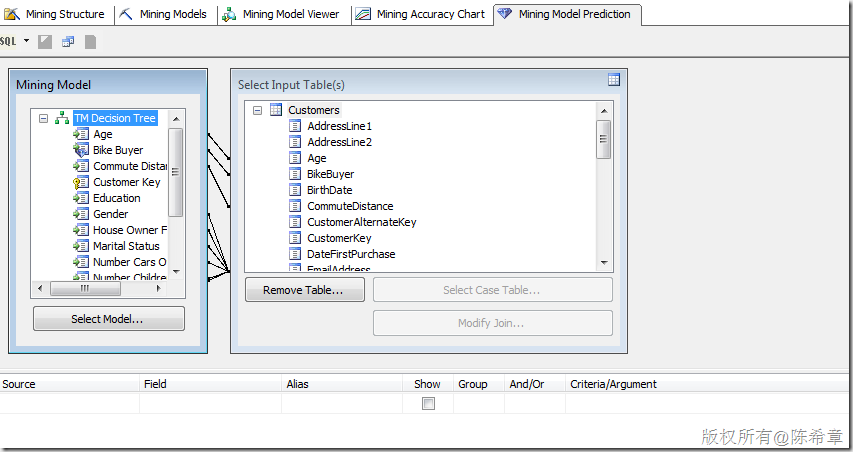
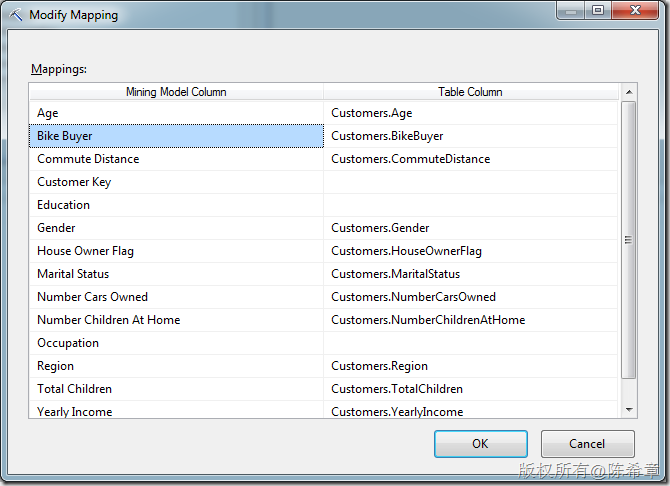
在这种情况下,Bike Buyer这个列,也可以作为输入进行映射。
关于SQL SERVER数据挖掘之列的用法就介绍到这里,下一篇我们介绍:SQL SERVER数据挖掘之理解聚类算法和顺序聚类算法。
【编辑推荐】











