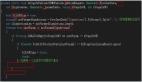
本文主要介绍sqlite数据库遇到的一些问题以及解决的思路,接下来我们一一介绍。
rowid和Integer主键及自增属性
大多数情况下,sqlite3的表都有一个rowid(也叫oid,_rowid_),这是一个64位的整数,并作为sqlite存储结构B树的主键。因此使用rowid查询会比以其他设定的主键查询,速度会非常快。
在做插入操作的时候,对于rowid的值通常情况下不要去指定,让系统自己去决定该去何值。因为sqlite会通过SQLITE_SEQUENCE来追踪表的rowid取值情况。而且sqlite定义了rowid的取值算法:在未超出rowid的范围内,待插入记录的rowid总是表中存在过的的rowid***值+1。比如依次插入5条记录,此时***一条记录的rowid是5,如果把这条记录删除再插入新记录,此时新纪录的rowid是6。而当rowid达到所能表达的***值时,这时如果有新纪录要插入,系统就会随机从之前的没有使用过的正整数中随机取一个作为rowid(就是之前删除过的)。若没有未使用的正整数并且你没有在插入的时候制定rowid为某一个负数的话,系统就会抛出SQLITE_FULL的错误。
如果在创建表的时候设置了主键,并且设置主键的那列是integer(不是int,short integer等等),并且主键没有设定降序时,这时的主键是rowid的别名,换言之,主键和rowid没有区别。如果我们再设定主键autoincrement属性时。和rowid又有什么区别呢?区别只是在于此时主键的取值是一个未使用过的rowid值,而这个rowid值系统会保证其是单调增长的,通常情况下就是表中存在过的rowid***值+1。这里所说的通常情况下是因为有这样一种情况:当插入操作由于表约束而失败的时候,本来要赋值的rowid,有可能不会在下次插入操作中使用,此时主键的取值就是表中存在过的rowid***值+2。
因此对于用户id是整数的表,是单独设主键去维护还是直接使用rowid作为主键,就取决于各自的业务逻辑关系了。在这种情况下,通常不使用rowid的主键特性。
Union All
今天遇到个问题, boss对app有了新的要求,具体到业务上就是:
假设有两张表:
create table A (username varchar(50), created datetime);
create table B (nickname varchar(50), userID integer, added datetime);
- 1.
- 2.
- 3.
表A和表B之间没有任何关系,唯一有联系的就是有一列属性都是datetime。而boss就需要将A和B的所有值取出并按时间排序。
乍一看不知道咋解决,因为两张表刚好没有关系啊.后来才意识到可以用union,比如:
select Null as col1, username as col2,created as col3 from A
union all
select nickname as col1, userid as col2,added as col3 from B
order by col3;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
然后根据某一列值是否为空来生成不同的对象。
思考:
1.遇到这个问题后,首先想到的是join,但表又是没有关系的,所以陷入了死胡同,跳出这个思维,从sql本身出发,问题解决。
2.从软件开发的角度,对于已经进行了一半的开发,如果有新的需求,对于已有的软件架构,数据库结构都会是一个挑战。但这样的变化往往是不可避免,尤其是在小公司,用scrum开发的环境下。遇到这样的问题只能希望架构师依靠自己的检验,设计出易于扩展的架构。
取出某一段数据
sqlite取出某一段数据是用limit,比如要取出第6-20条记录,只需:
select * from TableName limit 5,15.
- 1.
关于sqlite的问题总结就先介绍到这里,我们还会在以后的文章中接着介绍,感兴趣的朋友可以继续关注。
【编辑推荐】