一份来自Novell公司Ponemon研究所针对对美国94个大型企业的调查显示,平均每个公司每年花在非结构化数据处理上的成本为210万美元;而一些受到严格监管的行业,比如金融、制药、通讯和医疗行业的成本最高,每年将达到250万美元;另一个来自Unisphere Research的调查则显示,62%的受访者表示非结构化信息的产生是不可避免的,在未来十年内将超过传统数据。此外有35%的人表示,在未来的36个月里,非结构化的信息量将超过传统的关系数据。
据IDC的预测,现在全球数据量每18个月就要翻一番,每年全球产生的数据量已经高达40EB(1EB=1000PB)。而这些疯狂增长的数据主要来自非结构化数据。
事实上,结构化数据成为主流早有征兆,2008年,基于文件的存储系统容量出货量就以微弱的优势首次超过了基于块的存储系统容量的出货量,而近几年,这一差距正在逐渐拉大,据Gartner预计,到2012年,基于文件的存储系统容量将占到总容量的70%。而IDC也同时预测,鉴于基于文件类型的非结构化数据的增速极快,到2012年,全球存储市场的总出货量中将有80%的容量被文件级数据所覆盖。
显然,对于拥有非结构化数据处理需求的企业而言,需要正视它所带来的麻烦了。
什么是非结构化数据?
非结构化数据是相对于结构化数据而言,结构化数据主要是指那些数字的或能用统一的结构来表示的数据,如存储在数据库中的数据,这些数据基本上是以块(Block)的形式呈现。而非结构化数据是指那些无法用数字或统一的结构来表示的数据,像文本、图像、视频、音频、报表、网页等都是非结构化数据,它们大多以文件(File)的形式保存。
实际上,造成非结构化数据激增的原因主要有两个:一是云时代的到来使得数据创造的主题由企业逐渐转向用户个体,而个体所产生的绝大部分数据均为图片、文档、视频等非结构化数据;另一方面,信息化技术的普及使得企业更多的办公流程通过网络得以实现,以往纸质的表单、票据等现在都实现了数字化存档,而这方面产生的数据也以非结构化数据为主。
比如Web页面,其通常被认为是一个典型的非结构化数据,尽管基本上所有的网页都是由HTML语言组成,具备丰富的结构定义。但是Web页面还包含链接和引用外部的内容,而这些内容往往是非结构化的内容,如图像、XML文件、动画等。
此外,非结构化数据也是在客户关系管理(CRM)系统中普遍存在,特别是客户服务代表和呼叫中心的工作人员的笔记记录。
面对由非结构化数据+传统结构化数据组成的“Big Data”,我们该如何应对呢?
显然,集成所有这些数据将需要推陈出新。40年前的数据管理系统需要更高级的程序能够管理所有数据类型,包括结构化和非结构化,并可满足分布式数据部署在全球网络任何地方的需求。
非结构化数据
在传统的解决方案中,结构化数据的访问是小数据大密集的方式,一次数据库的写入读出产生的数据量只有几Byte或者是几KB,但是它需要非常密集的访问,对于一个大型企业的数据库而言,其每秒的调用次数一般会达到几十数百次,因此对于数据库存储设备的考量指标是IOps,也就是一秒能够完成的I/O数量。
因此为了最求更快的查询速度,企业开始部署拥有更大I/O吞吐能力的SSD硬盘。但是新的问题开始出现,随着SSD制成的提升(72nm->50nm->32nm->25nm),单点可擦写次数是在下降的,对于MLC,50nm的单点擦写10000次,32nm就只有5000次左右,而最新的25nm单点3000次不到。
性能提升的同时也就意味着可靠性的下降,这实在是一个两难的选择。
虽然能够通过软件能力提升擦写和磨损均衡算法,但这几代SSD产品的寿命提升并不明显。不过制程提升,容量也大幅度提升,用户可以通过冗余更多空间来换取寿命,但这也并非是解决非结构化数据的最好办法。
阿里巴巴运维部高级DBA张瑞表示,如果一套系统,虽然设计了RAID,但是坏盘后,重建需要十多个小时,而且整个系统的性能降级非常明显,用户是根本无法接受的,所以在考虑系统架构上不要总是从最好的方面考虑,而是应该从最差的情况考虑。
他表示,从某种意义上而言,重新设计新的系统,很重要的考虑因素需要考虑坏盘、坏节点、坏路径对系统的影响,而且还要考虑损坏后,如何快速恢复。
显然,处理结构化数据最好的选择依然是RAID,毕竟RAID技术因更大容量硬盘、更便宜的稳定性硬盘深受用户喜爱。但是对于非结构化数据而言,当存储服务器里面的磁盘越来越多,容量越来越大后,目前的RAID卡技术也许真的不太适合了,一个好的非结构化数据存储架构将能够提供非常大的I/O吞吐量,也就是传输带宽。必然的趋势是,非结构化数据处理使用分布式计算的方式将会越来越多。
RAID不会以任何方式消亡,但是对新一代磁盘和新一代的存储不断增长的需求正在开放新的扩展磁盘保护的新方法去超越RAID。RAID或许仍然是数据保护一个重要的部分,但是它将可能会是其他技术的补充。
未来的商业智能——混合数据的需求
对一个企业而言,非结构化数据用于BI(商业智能)的目的不仅仅是分析数据,更多的的企业希望的是将结构化与非结构化数据相结合进行分析,企业希望能够分析各种各样的数据流:比如混合数据。
从传统的数据仓库来看,他们对非结构化数据的支持非常好。因此,数据仓库新兴的架构体系观点是:将非结构化数据存储在像Hadoop这样的分布式架构中,并对这些数据做基本的分析工作。最后创建摘要信息传递到正在使用的数据仓库做进一步分析,企业还可以通过直接合并两个不同的环境或通过例如Hadoop中联合查询的方式实现。
但现实的问题是传统的BI工具不支持在同一查询中分析查找结构化和非结构化数据。相反,你必须使用MapReduce或其他一些基于SQL的工具。
然而这并不意味着不存在合适的可同时处理结构化和非结构数据的工具。例如Endeca Latitude和CXAIR都支持结构化和非结构化数据的混合查询功能。
这两种产品实现的方法不同,但基本理念相同。就是从非结构化数据中提取结构,然后直接结合结构化数据。这两款产品都非常容易使用。而且允许用户集中浏览数据,而不仅仅是产生报告。
目前来看,这两家厂商在自己的市场方针上还是不同的。具体来说Latitude主要开发分析应用程序,支持混合数据的浏览。而CXAIR则更倾向于传统BI市场。
但似乎两个厂商都没有一个完美的解决方案可应对所有混合数据所带来的问题。
共同点是,他们都明确选择仓库存储体系结构。毫无疑问,内置Endeca和Connexica技术并具有处理非结构化数据功能是BI领导厂商所必需具备的。
分布式架构将是最终的选择
对于大型组织而言,处理非结构化数据的能力的确是有必要的,但对于较小规模的公司,潜在的问题是这一解决方案成本过高。
云数据库能否克服多年来一直困扰传统数据库的扩展性和性能的问题。照目前的情况来看,为了获取云数据库的数据,需要求数据管理技术在一个集中的位置存储数据库中的所有数据。除此之外,还有一个严重的限制,就是传统数据管理技术在管理非结构化数据带来的问题。
一种替代方法是将数据存储在数据仓库,例如Teradata的Aster Data或EMC的Greenplum,他们支持原生MapReduce提供的所有功能。但是如果尝试这样做的话会遇到扩展性的问题。
而分布式计算则完美地解决了扩展性的问题,因此目前几乎所有的数据仓库、数据分析厂商都开始宣布支持以Hadoop或Mapreduce为代表的分布式技术,这也是必然之选(但是所有的商业化的数据仓库软件都是价格不菲)。
当然,对企业而言,另一个挑战在于作出重大改变来应对新的挑战,而这些改变包括新架构部署的费用,提高监管能力和日益复杂的IT基础设施。
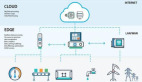
在云计算的架构里,服务器或存储设备将不可避免的比现在更加分散,这带来数据管理,分布式设计和性能的挑战。例如,一个数据库管理系统,可以查询分布在跨越多个地理位置上的数据中心的分布式数据,这是云计算普及中企业会遇到的一个新问题。
传统的数据库管理系统不能满足云数据库管理系统的需求。集中式的架构大部分是40年前设计的。这阻碍了他们被有效的分布式的存储在数据中心之中。为了满足云数据库管理系统的最关键的特性,需要一个分布式的对等架构。
企业需要数据管理的技术,可有效的获取任何格式的数据,并分布在全球网络的任何地方。无需上传或下载大量的数据在互联网上,这将是未来对云计算网络的基本要求。