本篇要评测的NoSQL产品是HBase,和其他简单的Key-Value结构不同,HBase主要面向处理海量数据的应用,可以认为是Google BigTable的一个开源版本。由于Facebook使用HBase来存储消息内容和大数据量的实时分析而使得这一产品备受关注。
一、HBase简介
HBase是用Java开发的,是一个开源的、分布式的、面向列的数据库,其存储的每个值都有一个时间戳,可以根据定义好的规则保存多个版本(默认是3个),这样就可以记录数据的变动情况。
HBase和Hadoop无缝集成,可以利用HDFS实现数据的底层分布式存储,保证冗余和可靠性,通过ZooKeeper来实现一致性和高可用性。
HBase有两种部署方式:一种是比较简单的单实例方式,它已经内置了0.20版本的Hadoop包和一个本地ZooKeeper,它们运行在同一个 JVM之下,可以用本地文件系统而不用HDFS。另外一种比较复杂的分布式部署,需要在每一个节点替换自带的Hadoop包以免有版本问题,而且必须有一个HDFS实例,同时需要独立的ZooKeeper集群,这也是处理海量数据时的推荐的部署方式。本文为测试方便,使用简单的单实例部署方式。
二、安装和使用
首先从镜像下载最新版的HBase,目前最新的版本是0.90.3:
- [root@localhost hbase]# wget http://mirror.bjtu.edu.cn/apache/hbase/stable/hbase-0.90.3.tar.gz
先检查下本地的JDK版本是否在1.6以上:
- [root@localhost hbase]# java -version
- java version "1.6.0_24"
解压并配置数据文件的路径:
- [root@localhost hbase]# tar zxvf hbase-0.90.3.tar.gz
- [root@localhost hbase]# cd hbase-0.90.3/conf
- [root@localhost conf]# vi hbase-site.xml
- </configuration>
- <configuration>
- <property>
- <name>hbase.rootdir</name>
- <value>/home/banping/hbase/data</value>
- </property>
启动Hbase进程:
- [root@localhost hbase-0.90.3]# bin/start-hbase.sh
- starting master, logging to /home/banping/hbase/hbase-0.90.3/bin/../logs/hbase-root-master-localhost.localdomain.out
可以通过自带的shell命令来进行基本的操作:
- [root@localhost hbase-0.90.3]# bin/hbase shell
- hbase(main):002:0> create 'test','cf'
- 0 row(s) in 0.9940 seconds
- hbase(main):019:0> list
- TABLE
- test
- 1 row(s) in 0.0290 seconds
- hbase(main):022:0> put 'test', 'row1', 'cf:a', 'value1'
- 0 row(s) in 0.2130 seconds
- hbase(main):023:0> put 'test', 'row2', 'cf:b', 'value2'
- 0 row(s) in 0.0120 seconds
- hbase(main):024:0> put 'test', 'row3', 'cf:c', 'value3'
- 0 row(s) in 0.0130 seconds
- hbase(main):025:0> scan 'test'
- ROW COLUMN+CELL
- row1 column=cf:a, timestamp=1310027460885, value=value1
- row2 column=cf:b, timestamp=1310027469458, value=value2
- row3 column=cf:c, timestamp=1310027476262, value=value3
- 3 row(s) in 0.0870 seconds
- hbase(main):026:0> get 'test', 'row1'
- COLUMN CELL
- cf:a timestamp=1310027460885, value=value1
- 1 row(s) in 0.0250 seconds
- hbase(main):027:0> disable 'test'
- 0 row(s) in 2.0920 seconds
- hbase(main):029:0> drop 'test'
- 0 row(s) in 1.1440 seconds
- hbase(main):030:0> exit
停止Hbase实例:
- [root@localhost hbase-0.90.3]# ./bin/stop-hbase.sh
- stopping hbase......
如果使用PHP操作Hbase,可以使用Facebook开源出来的thrift,官网是:http://thrift.apache.org/ ,它是一个类似ice的中间件,用于不同系统语言间信息交换。首先下载最新的版本0.6.1:
- [root@localhost hbase]# wget http://mirror.bjtu.edu.cn/apache//thrift/0.6.1/thrift-0.6.1.tar.gz
安装需要的依赖包:
- [root@localhost thrift-0.6.1]# sudo yum install automake libtool flex bison pkgconfig gcc-c++ boost-devel libevent-devel zlib-devel python-devel ruby-devel
编译安装:
- [root@localhost thrift-0.6.1]# ./configure --prefix=/home/banping/hbase/thrift --with-php-config=/usr/local/php/bin/
- [root@localhost thrift-0.6.1]# make
- [root@localhost thrift-0.6.1]# make install
生成php和hbase的接口文件:
- [root@localhost hbase]# thrift/bin/thrift --gen php /home/banping/hbase/hbase-0.90.3/src/main/resources/org/apache/hadoop/hbase/thrift/Hbase.thrift
- [root@localhost hbase]# cd gen-php/Hbase
- [root@localhost Hbase]# ll
- total 320
- -rw-r--r-- 1 root root 285433 Jul 7 19:22 Hbase.php
- -rw-r--r-- 1 root root 27426 Jul 7 19:22 Hbase_types.php
把PHP客户端需要的包及刚才生成的接口文件复制出来供php程序调用:
- [root@localhost Hbase]# cp -a /home/banping/hbase/thrift-0.6.1/lib/php /home/webtest/thrift/
- [root@localhost Hbase]# cd /home/webtest/thrift/
- [root@localhost thrift]# mkdir packages
- [root@localhost thrift]# cp -a /home/banping/hbase/gen-php/Hbase /home/webtest/thrift/packages
启动hbase和thrift进程:
- [root@localhost hbase-0.90.3]# ./bin/start-hbase.sh
- [root@localhost hbase-0.90.3]# ./bin/hbase-daemon.sh start thrift
- starting thrift, logging to /home/banping/hbase/hbase-0.90.3/bin/../logs/hbase-root-thrift-localhost.localdomain.out
thrift服务默认监听的端口是9090。至此测试环境搭建完毕。
#p#
三、测试说明
1、测试环境
HBase部署在一台PC 服务器上,配置如下:
CPU为Xeon 2.80GHz *4
内存为4G
硬盘为一块400G SATA盘
操作系统为64位CentOS 5.3版本
2、测试方法
采用PHP客户端进行测试,在安装过程中我们已经获取了PHP客户端访问HBase需要的包含文件。
为了不对测试服务器产生额外的影响,测试客户端部署在另外一台独立的服务器上,运行的PHP的版本是5.3.5,web server是Nginx 0.8.54,通过fastcgi的方式调用PHP服务。使用apache ab工具实现多个请求和并发操作。
测试过程首先是进行写操作,通过500个请求,每个请求写入10000条记录,并发度为1来共写入500万条数据,每个行(row)定义为数字1到 5000000,列(column)标记为id:对应的行id,列value为100个字节大小的数据,版本默认为记录3个。然后是读操作,发起5000 个请求,每个请求随机根据row id值读出1000条记录,并发度为10共读出500万条记录,评测的重点是写入和读出数据的时间,以及在此过程中服务器的资源使用情况。
四、测试结果
1、写操作
成功写入500万条记录,共耗时5418秒,平均每秒写入数据923笔。磁盘上的数据文件大小620M。写入过程中,服务器内存、CPU和磁盘等资源使用情况如下图所示:
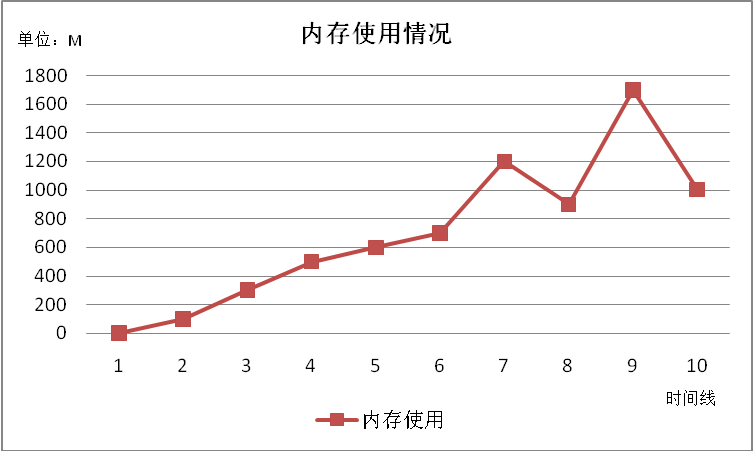
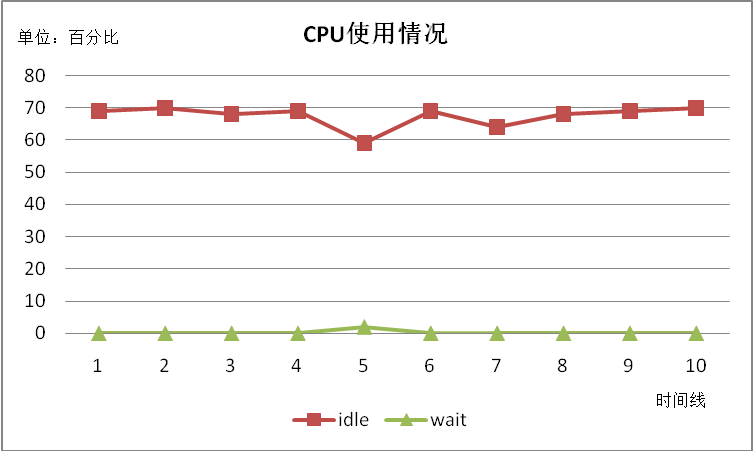
可见,内存使用平稳上升,最后占用1G左右,主要用来缓存数据,中间有偶尔的内存使用高峰,猜测是JAVA 的垃圾回收后会释放内存。CPU使用非常平稳,idle稳定在79左右,几乎没有wait发生。磁盘IO非常低,但是写入速度较慢。总体来说占用资源很少,表现也很平稳。
2、读操作
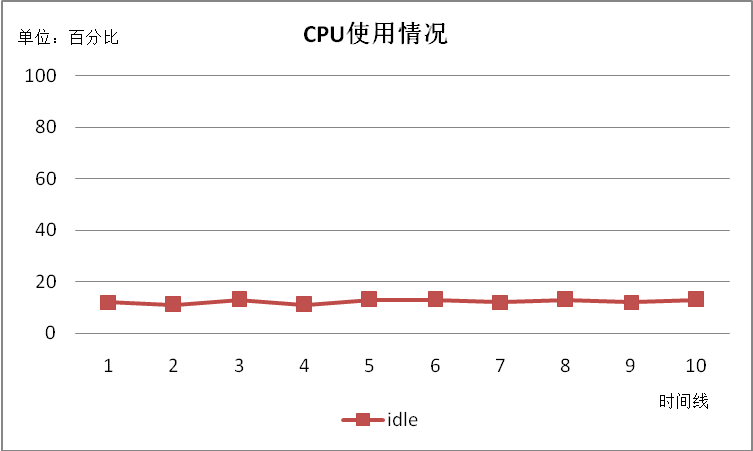
成功读出500万条记录,共耗时8521秒,平均每秒读出数据587笔。
读数据过程中磁盘IO很低,几乎没有波动。CPU消耗较多,Idle值稳定在13左右,等待CPU资源的进程一直有3到14个。内存表现平稳没有波动。
五、总结
通过以上测试结果可以看出,HBase读写效率并不高,因为它是针对海量数据处理来设计的,侧重的是海量存储下的性能而非Key-Value存储的效率,因此这也是正常的,另外由于写入速度慢,因此磁盘IO占用非常低,这和其他几款NoSQL有明显的区别。随着淘宝等国内互联网巨头不断加大使用 HBase的规模,相信在国内会有越来越多的成功案例。
【编辑推荐】