












SQL Server的Replication技术已经变得非常成熟了,而且效果也很好,很多的公司在做读写分离时,都选择了这项技术;Replication现在包括事务、合并和快照三种,每项都有各自的应用优势,大家用得最多的无疑是事物复制了,这种技术能保证我们发布端的数据的变更能及时传输到订阅端,网络带宽和服务器配置。
如果不差的话,两台机器之间的数据延时是非常小的,这为我们的读写分离技术提供了有力的保障(很少出现用户刚刚新加的数据查不到的现象),不仅分散了读写的压力,而且在做机器维护时也游刃有余,并且用户体验也得到了比较好的提升,下面我们以事务复制为例,来介绍下创建复制链的技巧。
创建Replication有三种方法:
方法一:使用备份还原的技术
这个方法对数据量比较大,而且停机时间要求非常紧的数据库复制是很好的选择,实现方式很简单,就是在停站的情况下,把我们的发布端的数据库备份,
然后还原到订阅端,这样发布端和订阅端的数据是一致的;然后我们再将同步链建上即可。
不过,这个方法有个要求是,我们把数据还原到订阅端后,需要检查所有的表是否有自增列,如果有自增列,我们需要将自增列改为普通列,方式如下:
1.在订阅端还原的数据库上查找自增列:
--查找数据库自增列
SELECT
表名=D.NAME,
列名= A.NAME,
是否自增=CASEWHENCOLUMNPROPERTY( A.ID,A.NAME, 'ISIDENTITY ')=1THEN'√'ELSE''END,
主键=CASEWHENEXISTS(SELECT1FROMSYSOBJECTS WHEREXTYPE='PK 'AND PARENT_OBJ=A.ID ANDNAME IN (
SELECTNAME FROMSYSINDEXES WHEREINDID IN(
SELECTINDID FROMSYSINDEXKEYS WHEREID =A.ID AND COLID=A.COLID))) THEN'√'ELSE''END
FROM SYSCOLUMNS A
LEFTJOINSYSTYPES B ONA.XUSERTYPE=B.XUSERTYPE
INNERJOINSYSOBJECTS D ONA.ID=D.ID AND D.XTYPE='U'ANDD.NAME <>'DTPROPERTIES '
where COLUMNPROPERTY( A.ID,A.NAME, 'ISIDENTITY ')
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
#p#
结果如下:
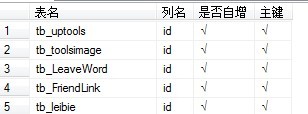
2. 将自增列修改成普通列:
方法是先重名了这些表,然后新建同名的表,表结构一样,但是去掉自增列属性,然后将重命名的表数据导入到新表中,完成后我们就得到了没有自增列的表,然后就可以创建同步链了。
方法二:BCP和TableDiff
BCP结合TableDiff在我们为已有的同步链添加新表,而且要求发布端必须保持在线,并对发布端业务影响最小时是非常好的方法,它的实现步骤如下:
1. 将需要新加到同步链的表结构新建到订阅端;
2. 在发布端准备好BCP导出导入脚本,并将要新加的表通过BCP导出到文件中;
3. 将新表加入到同步链中(可以通过脚本,也可以直接通过可视化界面操作),暂停这条链上同步数据的JOB;
4. 运行BCP导入脚本,将数据导入到订阅端;
5. 用TableDiff比较新表在订阅端和发布端的数据,并补齐差异数据(TableDiff 比较后会自动生成不起差异数据的脚本,在订阅端运行即可);
6. 开启暂停的同步链的JOB,这样就完成了。
整个过程对系统业务影响非常小。
方法三:直接初始化快照
这种方式是最简单的,但是对业务影响非常大,而且耗时也很长,基本不推荐(不过这个方法很多人在用,如果是很小的库还是可以考虑)。
【编辑推荐】











