












搜索引擎工作原理如下:
也许很多人会问,现在互联网发展到今时今日,已成为了区别于现实世界的另一个世界,也就是虚拟的世界,那么他的网页数量到目前究竟有多少呢?如果要具体说出一个确切的数据,肯定没有人能够回答的出来的,但是我敢肯定的说,目前的网页数量至少是以千亿来计算,因为这是一个随时变化的数据,而且数据非常庞大,没有人能精确算出来。这些网页,组成不同的网站,存储在世界各地不同的服务器上,并且分布在世界各地数据中心和机房里。
也许还有大部分人认为,当我们在搜索框里敲入搜索请求,搜索引擎就会实时地从世界各地的服务器上进行查询信息、收集整理,并把查询结果排序展示在用户面前。包括我之前还没有接触搜索引擎时,也是认为搜索引擎就是这样子工作的,但是今天我知道这是一个错误的认为,搜索引擎不是这样工作的。
全球这么多网页,搜搜引擎是不可能进行实时地全部抓取,并整理排序的,对全球网页进行全部抓取需要很大的储存空间和技术,目前没有哪一个搜索引擎能承受的起的。据统计,如果搜索引擎是进行实时工作的话,当你发出你的搜索请求到看到搜索结果,这个“实时”可能要等上好几年甚至更长。
那么面对如此庞大的数据库,搜索引擎又是如何去工作的呢?就此,漠阳子SEO博客给大家分析一下!
我们通俗地说,其实是这么一回事,搜索引擎尽***的能力,预先就去深入大量网站,把这些网页的部分认为是有价值的信息预先存储在自己的服务器上;然后,当用户搜索时,再从自己的服务器上把适合的信息展现出来。就好比如我们在互联网上找资料和在自己电脑上找资料的区别。
从搜索引擎的基本技术来讲,包括抓取、索引、排序三个方面。
***,抓取
相信大家对于搜索引擎里所说的“蜘蛛”、“机器人”不会很陌生,他就像是搜索引擎的一大猛将,根据一定的程序规则,这位“猛将”在互联网上进行扫描,以网站的链接为桥梁进行不断的爬行。从而所进过的新站、旧站,只要是它认为是有价值的信息,就进行抓取,并收入囊中。
第二,索引
每一个搜索引擎都会有自己的一套分析索引系统,对抓取回来的网页进行相关的提取,比如网页的URL、编码、页面内容、链接、生成时间、关键词等,通过一定的算法进行复杂的计算,并计算出网页的相关度(关键词、重要性),然后建立一个索引数据库。
第三。排序
排序,简单地说就是当用户输入关键词并发出搜索请求后,搜索引擎的系统就会根据你的关键词在网页索引数据库里进行查找,然后再显示在搜索结果上返回给用户。按照自然排名来说,这些索引数据库里的网页事先已经计算好相关度的了,越接近搜索请求的要求就越排在前面。这也是为什么我们要对网站进行优化的关键所在,想必每个网站都是想跻身在前面的。
***我们来看一幅搜索引擎工作原理的图,这样会更直观明了。
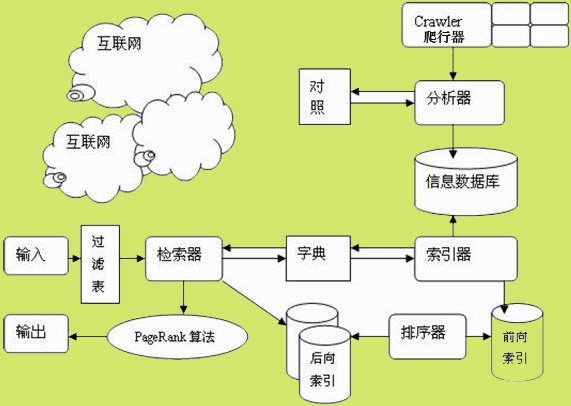
如果图片不清楚的话,大家可以点击查看大图的。希望本文能够给你带来帮助。
【编辑推荐】












