索引是一个单独的、物理的数据库结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序。数据库使用索引的方式与您使用书籍中的索引的方式很相似:它搜索索引以找到特定值,然后顺指针找到包含该值的行。
要了解索引访问方法,首先要知道索引的结构。
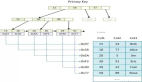
1.表和索引的结构
页
页是sql server存储数据的基本单位,大小为8kb,可以存储表数据、索引数据、执行计划数据、分配位图、可用空间信息。页是sql server可以读写的最小I/O单位。即便是读取一行数据,它也要把整个页加载到缓存并从缓存中读取数据。
区
区是由8个连续页组成的分配单元。
堆
堆是指不含聚集索引的表,它的数据不按任何顺序进行存储。
联系一个堆中的数据的唯一结构是被称为索引分配映射(IAM)的一个位图页,当扫描对象时,SQl server使用IAM页来遍历该对象的数据。
聚集索引:
它的叶级表中维护所有数据,按照索引键列的顺序存储在索引的叶级。在索引页级别的上层,索引还维护着其他级别,每个级别都概况了它下面的级别,非叶级索引上的每一行指向它下一级别的整个页。
堆上的非聚集索引:
与聚集索引的唯一区别是非聚集索引的叶级页只包含索引键列和指向特定数据行的行定位符,称为RID。当通过索引查找到特定的数据行后,Sqlserver必须在seek操作之后执行RID lookup操作,该操作用于读取包含数据行的页。
聚集表上的非聚集索引:
指向特定数据行的行定位符是聚集键的值,不是RID。
2.索引访问方法
表扫描/无序聚集索引扫描
当表中没有索引时,连续的扫描表中的所有数据页。SQl server将根据该表的IAM页指示磁盘取数臂按物理顺序扫描属于该表的区。
当表包含聚集索引时,所采取的方法将是无序聚集索引扫描。
示例sql:
- select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders
索引:
- CREATE CLUSTERED INDEX idx_cl_od ON dbo.Orders(orderdate);
表Orders结构:
- orderid,custid,empid,shipperid,orderdate,filler
覆盖非聚集索引扫描
Sql server 只访问索引数据就可以找到满足查询所需的全部数据,不需要访问完整的数据行。
示例sql:
- select orderid from dbo.Orders
索引:
- ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [PK_Orders] PRIMARY KEY NONCLUSTERED
- (
- [orderid] ASC
- )
有序聚集索引扫描
按照链接列表对聚集索引叶级执行的完整扫描 操作。
示例sql:
- select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders order by orderdate
索引:
- CREATE CLUSTERED INDEX idx_cl_od ON dbo.Orders(orderdate);
不同于无序索引扫描,有序扫描的性能取决于索引的碎片级别。
有序覆盖非聚集索引扫描
与有序聚集索引扫描类似,但是覆盖非聚集索引扫描时,因为它涉及更少的页,它的成本肯定比聚集索引索引扫描要低。
示例sql:
- select orderid, orderdate from dbo.Orders order by orderid
非聚集索引索引查找+有序局部扫描+lookups
通常用于小范围查询,且用到的非聚集索引没有覆盖该查询。
示例sql:
- select orderid,custid,empid,shipperid,orderdate,filler
- from dbo.Orders where orderid between 101 and 200
无序非聚集索引扫描 + lookups
通常符合以下情况时,优化器会选择此种访问方法:
- 该查询的选择性足够高
- 最适合某查询的索引并不覆盖该查询
- 索引没有按顺序维护被查找键
示例sql:
- select orderid,custid,empid,shipperid,orderdate,filler
- from dbo.Orders where custid = ‘’
聚集索引查找+有序局部扫描
对于按聚集索引的***个键列进行筛选的范围查询,优化器通常使用这种方法。
示例sql:
- select orderid,custid,empid,shipperid,orderdate,filler
- from dbo.Orders where orderdate = ‘20060212’
这种方法的好处是不涉及lookups.
覆盖非聚集索引查找+有序局部扫描
访问方法与上一个类似,唯一的区别是非聚集索引。相对于上一个访问方法,这个方法的好处在于非聚集索引的的叶级页比聚集索引的叶级页能够容纳更多的行。
示例sql:
- select shipperid,orderdate, custid from dbo.Orders
- Where shipperid='C' and orderdate >='20060101' and orderdate <'20070101'
- CREATE NONCLUSTERED INDEX idx_nc_sid_od_cid
- ON dbo.Orders(shipperid, orderdate, custid);
3.索引优化等级
需要优化的sql:select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders where orderid > 999001
1.这个表没有任何索引:该计划将使用表扫描
2.接下来优化,创建一个非聚集覆盖索引,且不把筛选列(orderid)作为***个筛选列:
- CREATE INDEX idx_nc_od_i_oid_cid_eid_sid
- ON performance.dbo.Orders(orderdate)
- include(orderid,custid,empid,shipperid);
优化器将采用覆盖非聚集索引扫描
3.下一步优化:创建一个不覆盖该查询的非聚集索引
- CREATE NONCLUSTERED INDEX idx_nc_od_i_oid
- ON dbo.Orders(orderdate)
- INCLUDE(orderid);
优化器将采用非聚集索引扫描+lookup,这个查询依赖于选择性。选择性越高,性能越高。
4.继续优化:在orderid上创建非聚集非覆盖索引,
- CREATE UNIQUE NONCLUSTERED INDEX idx_unc_oid
- ON dbo.Orders(orderid);
优化器将采用非聚集索引查找+lookup
5.继续优化:在orderid上创建聚集索引
- CREATE UNIQUE CLUSTERED INDEX idx_cl_oid ON dbo.Orders(orderid);
这个计划主要不涉及lookup,
6.继续优化:
***优化应该是把orderid作为键列,并把其他列定义为包含性非键列的非聚集覆盖索引。
- CREATE UNIQUE NONCLUSTERED INDEX idx_unc_oid_i_od_cid_eid_sid
- ON dbo.Orders(orderid)
- INCLUDE(orderdate, custid, empid, shipperid);
这个计划的逻辑与上一个类似,只是非聚集覆盖索引有序局部扫描读取的页更少。
【编辑推荐】