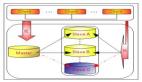
导读:数据库操作过程中有通用的分页存储过程,高效的分页存储过程。但是,这些并没有从根本上解决性能问题。我们知道对于相同的查询,如果你限制每页返回10条记录和每页返回20条记录比,虽然10条记录在网络和返回结果时会比20条记录要稍稍占一点优势。但是它要花比20条记录时2倍的访问次数,因此从总的资源消耗来看10条记录会占用更多的资源。但是用户的操作你永远是无法预测的,它可能只是看了第1页然后就退出了。我想一般用户也很少会去查看第20页之后的信息吧,除非他是钓鱼爱好者!因此,在确定每页多少条记录时没有标准。同时,一般的分页过程的查询条件都是动态的,用户可以任意的排序。因此,这样的查询你无法确定应该在哪些字段上创建索引合适。这样的查询一般来说都是很低效的。因为动态,所以你的分页过程可能每次都需要重新编译才能得到最优的执行计划。
那么是不是我们把每页返回的记录数调整的越大越好,或是一次把全部的结果返回给客户?我们知道SQLServer会把最终的结果保存到数据缓冲区中。你每次请求的SQL语句在执行之前会在服务端预先分配估计结果集大小的可用物理内存,除非你查询的结果集已经全部存在于缓存中了。如果迟迟不能预先分配能够保存最终结果的可用物理内存,则这个查询最终就会以超时而结束。同时,分页过程中一般都会对结果集进行排序。而排序、Hash联结、Hash聚合等操作都需要占用大量内存,这无疑是雪上加霜。如果你使用的是SQL2005,在SQLSERVER的安装目录下的LOG文件夹下会看到默认跟踪所创建的trc文件,如果你看到Sort Warning、Hash Warning,说明你排序的结果集太大了,排序操作正在等待分配可用的内存。或是hash操作时发生了递归哈希联接或哈希援助,详见联机文档。
在数据库的设置中有两个选项:最小查询内存和查询等待时间,我们一般都不需要去调整这两个选项。前者就是你的查询在排序、Hash等需要额外内存操作时,应该分配到的最小可用内存。后者是控制这个查询在没有分配到相关的资源时所等待的最长时间。如果是-1,则等待25倍于估计执行时间的时长。否则,超时退出。
有时候,你在测试机上运行的SQL语句是很高效的。但是,当正式服务器资源紧张时,你的这些高效SQL语句将会以一种不可思议的方式执行,因为SQL优化引擎所选择的最优执行计划是根据服务器当前负载而定的。归根结底,都是因为内存不足导致你的查询在事先分配可用内存时产生等待。而内存不足的原因很大程度上是因为有大量的表扫描所引起的。如果生产机同时为几个系统提供服务,如果有一个系统的SQL很糟糕。它就会把其它的系统都拖跨。面对这样的系统你也只能望洋兴叹了!
关于分页过程中top的使用,我在前面的总结中已经提到过。因为top操作是非关系操作,我们应该限制非关系操作的结果集大小。因此你应该先根据排序的字段,把排序字段所在表的主键值查找出来后,再去和其它的表关联查找相关信息。详见 对数据进行排序 的第二部分介绍。
基于上面介绍的页记录数和访问次数之间的矛盾,取一个折中的办法。我们能不能在用户第一次查询时把返回的结果保存到一个被持久化的表中呢?表的名称你可以用登录用户的名称加一些什么标志。也许你会担心向这些用户表中插入记录会影响到数据库的日志操作?我们一般都会使用SELECT INTO来创建这些用户表。如果数据库的恢复模式为FULL,频繁的写日志操作被排队,肯定会对性能造成负面影响。那么我们可不可以为这些用户表单独创建一个数据库,这个数据库的恢复模式simple。此时的SELECT INTO会按最小日志记录,因此不会受日志的太大影响。你的分页的存储过程中引用此数据库中的相关的表。
SELECT TOP 400 C1.*,ROW_NUMBER() OVER(ORDER BY C1.CompanyName) AS Line
INTO tom_fu FROM dbo.Customers C1
我之所以加了一个400是不想发生太多的I/O操作,就像上面说的用户一般不会查看第20页后的记录。但如果你要返回总的记录数用于计算总共的页数时,使用TOP n进行填充表时就不行了。你可能只有再运行一次查询count()的操作了,即便这样也不要带着order by来取count。如果用户不是特别关心记录的总数,最好就是忽略掉这一操作。或者你根据你查询返回的记录数多少,有计划的把TOP n省略掉,把全部的记录都填充至临时的用户表中。有了ROW_NUMBER()的编号,你就可以找到相应的页的记录。这时,你的过程里不但要传入每页的记录数、当前的页数还有查询的条件之外,还要另外传入一个是否创建这个用户表的标志。当用户改变了查询条件、排序规则时重新查询原始表用于创建这个临时用户表。如果排序规则的改变不会影响结果集,这时你也可以加一排序规则改变的标志,直接对已经查询出的结果进行一次排序。不管怎样,接下来的查询,将只对这个临时用户表进行查询,从而提高了查询速度。因为这个临时创建的用户表记录数并不多,表扫描这时和索引查找性能不相上下。同时,如果你要对这个临时表创建索引,也会增加额外的资源开销,因此我没有想在上面创建索引的想法。当查询不同的页时,直接对表进行扫描就可以了。然后,我们能不能把已经返回给客户的页面记录缓存起来?这时,当然不能用session,因为这要占用大量WEB服务器内存。你只能把返回的结果保存到客户的机器上,cookie看来是个不错的选择。通过编程的方式来记录这些记录所在的页面。这时,你首先在cookie中判断此页内容是否存在,如果是已经访问过的页面,不用再访问服务器。用户高兴,服务器也轻松!
上面是创建表相关的操作,那如何删除这些临时创建的用户表呢?可以在页面跳转时,可以在session过期时,可以在你确定用户不在需要这些临时用户表时发送一个删除此临时用户表的命令。但是,如果用户意外关闭时,可能这个临时的用户表就不可能被我们显示的删除了。因此,可能还需要一个类似.NET垃圾收集的机制来定期的删除这些不再使用的临时用户表。可以通过程序,也可以通过SQLServer的作业,我们知道你创建的表在sys.tables中都会得到它的create_date和modify_date,我们可以用来清除这些被物化的表。不管怎样,你都应该想办法确保尽早的删除这些临时用户表,以防止占用太多的磁盘空间。
这就是我要为大家介绍的数据库分页操作的全部内容,相信通过上文的学习,现在大家对数据库分页的操作已经有了很多的了解,希望大家都能够从中有所收获。
【编辑推荐】