对数据流来说按照需求将数据转换成需要的格式是数据操作中的一个关键的步骤。例如想要得到聚合排序后的运算结果,转换可以实现这种操作。和SQL Server 2000 DTS完全不同,这些操作不需要编写script,所有的运算都在内存中进行。添加一个数据转换之后,数据直接转换成想要的格式然后传递给下一个步骤,由于是在内存中完成运算操作的,不需要在数据库中建立对象来存储这些操作函数。但是当需要处理大批量的数据时,还是需要建立存储表或其他对象来处理的。
在data flow面板中拖放一个转换,鼠标点住然后拖放绿色连线到一个目的Destination,然后就可以双击并编辑这个转换。这部分将从最基本的功能开始讲解转换,下一部分将会做一些实验操作,并在实际盛传环境中来使用它。还有一些更高级的转换着这里不会讲解,把他们放在下一个随笔中讲解,这些高级的转换包括:
- 修改Dimension
- 透视和逆透视Pivot and Unpivot
- 行数
- 导入导出列
- 术语提取和查找
- 模糊分组和匹配
- 数据挖掘
- OLE DB命令
其中一些转换不是很复杂,只是在SSIS没有UI支持,要想使用它们需要使用Visual Studio中的高级编辑器。
聚合Aggregate
聚合转换可以像T-SQL中的函数GROUP BY, Average, Minimum, Maximum, 和 Count一样对数据进行聚合运算。在图4-13中可以看到数据以OrderDate,ProductLine分组,对LineTotal做求和操作。这样产生了三列新的数据,供其他操作。
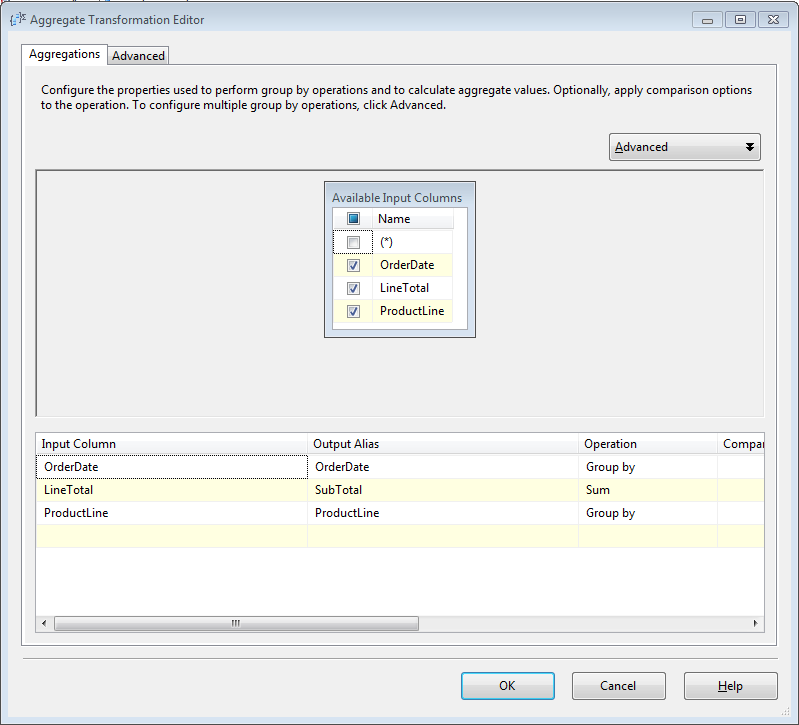
图4-16
在聚合操作编辑器Aggregate Transformation Editor,首先选择需要进行聚合操作的列,然后选中的列将会出现在下面的一个表里面在Output Alias列里面输入输出列的别名。例如如果想输出每个订单的总量,这里修改为SubTotal,这样可以更容易的识别出这一列的目的。最重要的以个设置是在Operation这一列选择聚合操作。它有一面一些选项。
- Group By:将数据按照某列分组
- Average:对数据列求和操作
- Count Distinct:对一组数据中非空行计算行数
- Count Distinct:对一组数据中的非空行计算非重复的行数
- Minimum:对一组数据中的数字列求最小值
- Maximum:对一组数据中的数字列求最大值
- Sum:对一组数据中的数字列求和
点击Advanced标签界面,在这个界面可以编辑转换输出。在Advanced界面可以输入聚合计算的名字,产生一个新的列。在Advanced标签界面,最关键的选择项是设置转换时的缓存,使它在一个合适的水平。例如较低水平设置为500000条,中等水平设置为5000000条,较高水平设置为25000000条。也可以使用Number of Keys属性设置具体数值。Auto Extend Factor属性设置转换可以使用的内存量,默认的值是25%,也可以设置其他选项保证RAM占用量。Warn On Division by Zero单选框用来处理求平均值时被除数是0,如果没有选择,转换失败将不会给出任何提示。
审核转换
审核转换允许对数据流添加审核审核数据,以往使用HIPPA和Sarbanes-Oxley (SOX)时,必须跟踪谁在什么时插入数据,审核转换可以实现这种功能。例如要跟踪那一个task向表里插入数据,可以在审核转换中添加相应的列。在Output Column Name列中输入想要审核的列,在Audit Type内选择审核类型如图4-17,可以选择的类型有:
- Execution Instance GUID:GUID标示是那一个package执行的插入操作
- PackageID:package的唯一标示
- PackageName:package的名字
- VersionID:package的GUID的版本
- ExecutionStartTime:package开始执行的时间
- MachineName:package所在的机器名
- UserName:启动package的用户
- TaskName:数据流中task的名字
- TaskID:包含转换task的Data Flow Task的名字
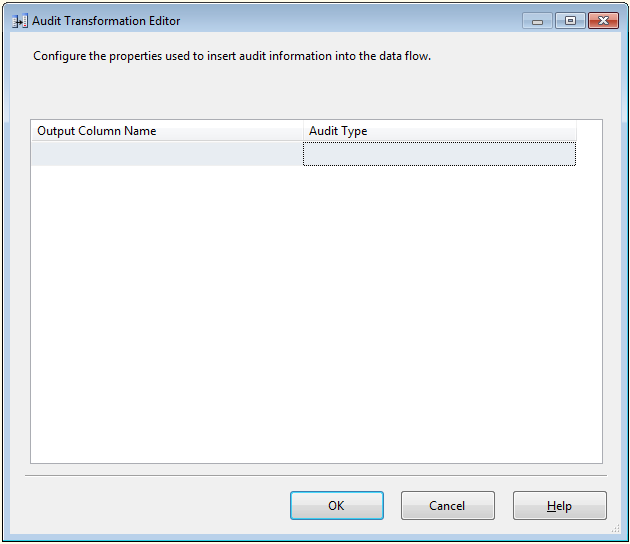
图4-17
#p#
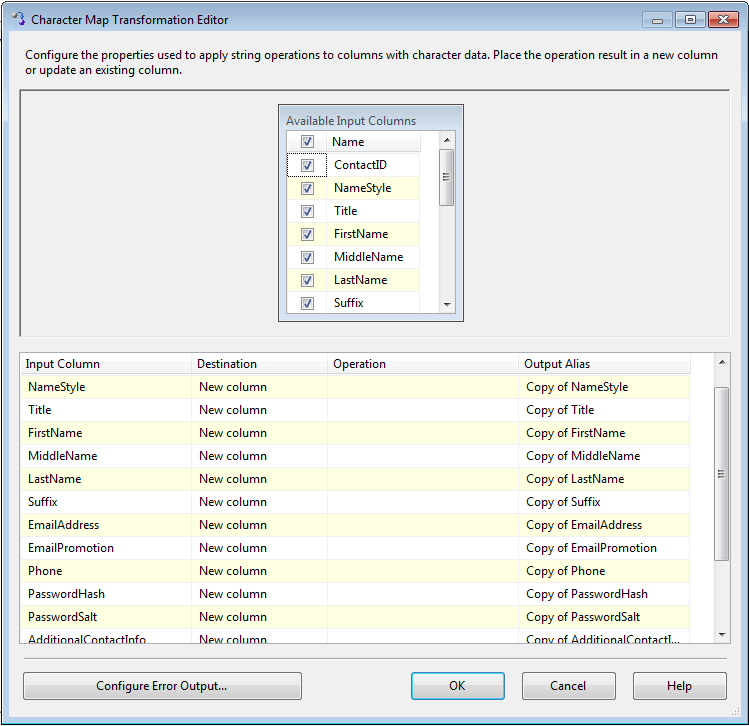
字符映射
特征映射转换如图4-18展示数据流中列的特征,它的编辑界面很简单,只有一个标签界面,点击要进行映射的列,可以选择需要添加新列或需要更新的列。可以在Output Alias列中给原来的列一个别名,选择要进行的操作,可以进行的操作类型有:
- Byte Reversal:逆转数字位的顺序,例如数据0x1234 0x9876的逆转结果是0x4321 0x6789,这种操作和LCMapString,LCMAP_BYTEREV选项有相同的操作结果
- Full Width:将半长字符转换成全长
- Half Width:将全长字符转换成半长
- Hiragana:将日语中的片假名转换成平假名
- Katakana:将日语中的平假名转换成片假名
- Linguistic Casing:使用区域语言规则
- Lowercase:转换成小写字符
- Traditional Chinese:将简体中文转换成繁体中文
- Simplified Chinese:将繁体中文转换成简体中文
- Uppercase:将字符转换成大写
条件分割
根据条件分割数据是一个在数据流中添加复杂逻辑的方法,它允许根据条件将数据输出到其他不同的路径中。例如,可以将产品中总数量超过500的输出到一个路径,少于500的输出到另一个路径。如图4-19。可以从上面的属性结构中拖放一个列或者代码段,然后根据逻辑重命名而不是使用默认值Case1,还可以编辑输出列的名字。
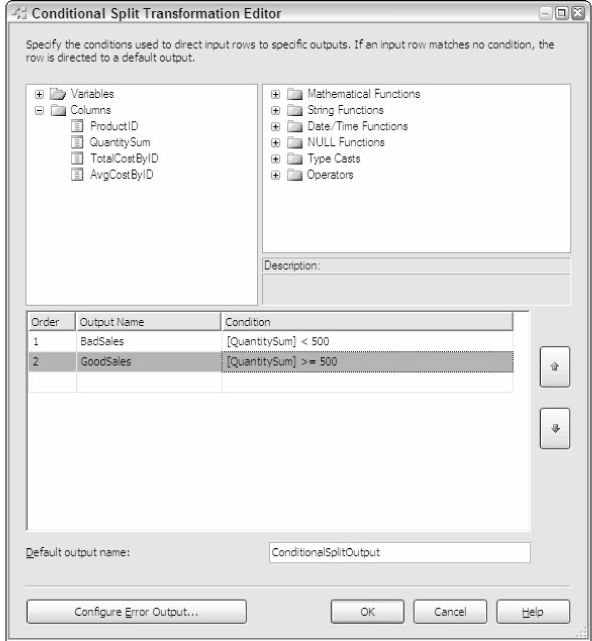
图4-19
可以使用表达式来读取字符数据,设置判断条件,例如下面表达式判断城市名字的第一个字符是F,SUBSTRING(City,1,1) == "F"。将这个转换连接到下一个其他转换的时候会弹出一个对话框提示选择数据输出路径,如图4-20.在这个图中,可以看到有两个选择,GoodSales输出到一个路径,其他输出到另一个路径。还可以新建其他的路径以供选择。
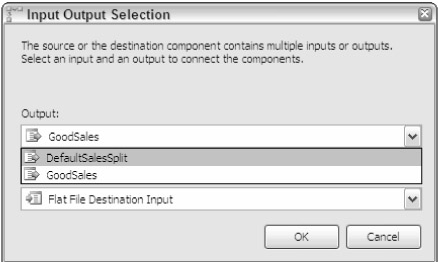
图4-20
如果有两个选择,一个默认选择适用于其他情况,路径如图4-21
图4-21
#p#
复制行
复制行转换时一种很简单的转换,它将某一列的数据复制一份克隆。这种操作在执行某些精确的转换之前先创建一份拷贝时非常有用。然后将可以对照拷贝数据修正源数据。双击打开编辑界面,选择要拷贝的列,并重新命名。注意:有些转换允许将一列数据复制到内在列里。
数据转换
数据转换执行类似于T-SQL中的函数CONVERT或CAST的功能。数据转换的编辑界面如图4-22,选择需要转换的列,在DataType下拉列表中选择需要的数据类型。Output Alias栏内设置输出时使用的别名。
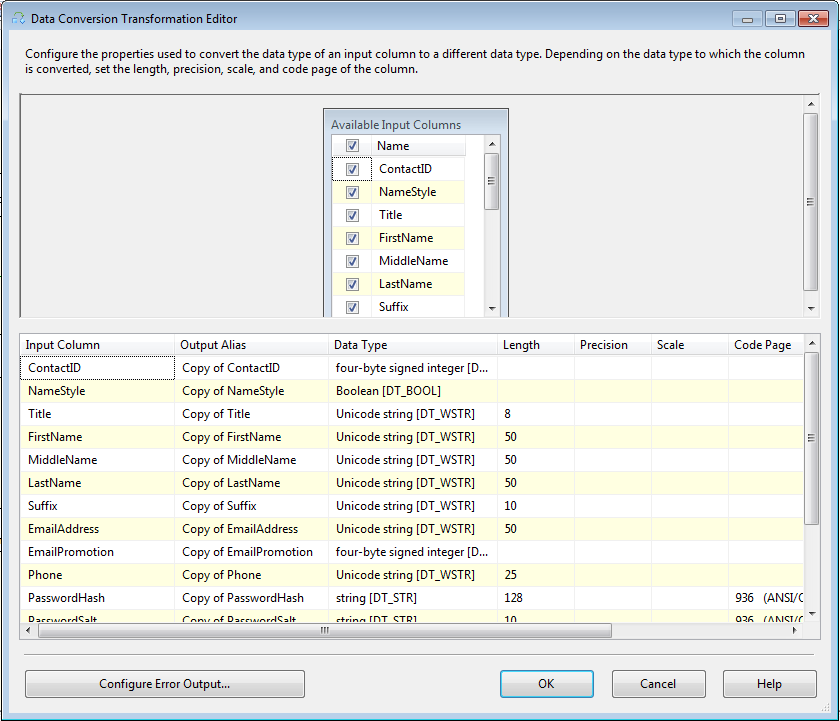
图4-22
#p#
数据挖掘请求
数据挖掘请求运行数据挖掘请求,并将结果输出到数据流。它还可以添加一些预测新列,一些应用场合如下列举:
- 根据已知的一些列,例如子女个数,家庭收入,配偶收入预测产生一个新列:这个人是否拥有住房
- 根据客户购物卡预测客户的购买意向
- 可以填充用户的调查问卷上没有填写的空白栏
派生列
导出列任务可以从从另一个输出中创建一个新的列。例如,是订单数量和订单价格相乘导出一个新的列订单总价格,如图4-23也可以使用ISNULL函数填充当前时间或者某一天的空白数据。这是五个可以代替T-SQL代码编程的task之一。
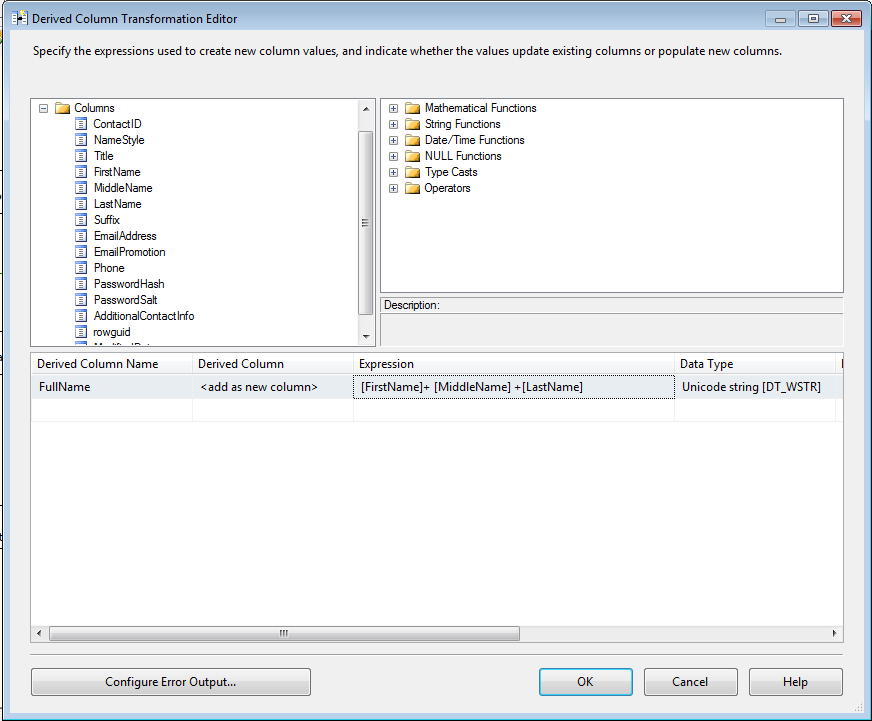
图4-23
#p#
输出列
输出列任务可以冲数据流中输出一副图片或者一个文件。和其他的转换task不同这种转换不需要一个Destination。如图4-24打开编辑界面,选择一个包含文件的列,再选择一个文件输出路径。
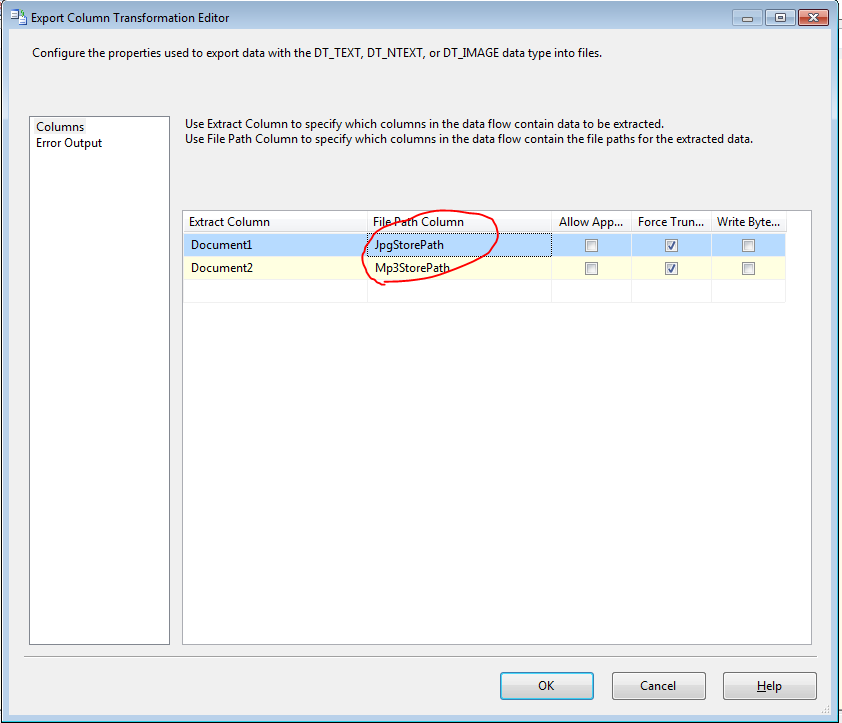
图4-24
另外一个选项这只再次执行task的时候文件被删除或覆盖,Allow Append选项输出是否累加到一个已经存在的文件中。如果选择Force Truncate选项,会覆盖掉已经存在的文件。Write BOM选项设置如果数据类型是DT_NTEXT是否写入字符顺序符号。如果没有设置Append和Truncate选项,task将执行错误,错误信息类似于下面:
Error: 0xC02090A6 at Data Flow Task, Export Column [61]: Opening the file
"wheel_small.gif" for writing failed. The file exists and cannot be overwritten. If
the AllowAppend property is FALSE and the ForceTruncate property is set to FALSE,
the existence of the file will cause this failure.
输入列
输入列和输出列是一个正好相反的task,他可以将图片和文本文件输入到一个数据行中,他们的编辑设置也是类似的。
先到这里,剩下的转换任务下次随笔在接着再说。
原文链接: http://www.cnblogs.com/tylerdonet/archive/2011/04/11/2012899.html
【编辑推荐】