题序:很多时候,我们专心研究一个东西的时候,往往忘记了我们最初的目的是什么。
曾经研究过那么久的Java集合框架,为了搞清里面的细节,甚至都跑去重新买了一本数据结构,终于知道了线性表,知道了树,知道了查找表。也自己动手实现了ArrayList,LinkedList,HashMap等。
今天在公交车上,突然想到“我们为什么要使用Java集合框架呢?”竟然一时语塞,半天想不起来,也说不出个所以然呢。顿时悲从中来啊。还是决定再次好好复习一把,现总结如下:
PS.还是那句老话,如果这些问题您都能轻松解答,没必要再浪费时间看下去了。
Question one:我们为什么要使用集合框架?
Question two:关于ArrayList 和Vector (HashMap和HashTable)PS
Question three:总体把握,集合框架的继承图
Question four:set 于map的关系(见李兴华书)
Question five:关于set(底层实现,关于TreeSet,关于排序,关于比较对象相等)
Question six: 已经存在了那么多的动态结构,为什么需要hash表?
Question seven:TreeMap 底层实现
Question One:我们为什么使用集合框架?
大家还记得我们为什么要使用数组嘛?
当我们需要保持一组一样(类型相同)的元素的时候,我们应该使用一个容器来保存,数组就是这样一个容器。
那么,数组的缺点是什么呢?
数组一旦定义,长度将不能再变化。
然而在我们的开发实践中,经常需要保存一些变长的数据集合,于是,我们需要一些能够动态增长长度的容器来保存我们的数据。
而我们需要对数据的保存的逻辑可能各种各样,于是就有了各种各样的数据结构。我们将数据结构在Java中实现,于是就有了我们的集合框架。
Question Two: List和Vector,HashMap和 HashTable 的区别在哪里呢?
前者都是在JDK1.2后推出的,在前者中,因为采用异步处理方式,性能更高。
(其实就是删掉了后者中操作数据{add ,remove等}时的线程同步锁,这样,效率更高了,但是却不再是线程安全的了,要线程安全,必须用户在程序中使用时自己控制。)
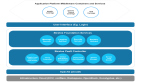
Question Three:集合框架继承图
本来想自己画个简图的,结果悲催的Rational Rose一直在抽风,也没时间去弄那个了。就网上Down了一个,暂且用着吧

从这个图中,我们可以发现:Collection 接口包括List和Set两个子接口(其实还有Queue和Sorted两个子接口)
另外,也验证了我们前面说的,Array和Collection都是用来保存数据的容器。
Question Four:Set 和 Map 有什么关系?
从Question Three的继承图中,我们很明显的发现:Map虽然不像Set那样属 于 Collection,但是Set和Map的继承图是如此的相似。那么,他们之间到底有什么样的 关系呢?
从逻辑上来说:首先,如果我们只考察Map中的key,那么显然,这个key的集合就是一 个set:不能重复,无序。(Map中有keyset()的方法,能直接得到key的set)另外一 个层面,如果我们 将Map中的key何value当做一个整体,那么,显然,这个时候 的Map其实就是一个Set(在Map的实现中,都是通过一个内部类来将key和value当做 一个整体entity),
从代码角度本身角度来看,无论是HashSet还是TreeSet其实使用的都是对应 的Tree来实现的,我们用一个默认的Object,这样就可以存了。
而事实上Set的底层实现中,我们也可以发现,都是用对应的Map来实现的,只是,在每次存key-value 对的时候,都默认给了一个Object 类作为Value的默认值,
Question five:关于set(底层实现,关于TreeSet,关于排序,关于比较对象相等)
我们知道,Set是无序的,同时又是不能重复的,那么,这种不能重复性,是如何保证的呢? 其实这个问题问的还是不到位,Question Four已经说了,底层是由Map实现的,那么都是由Map来实现的。
为了唯一性,重点是能识别相同的元素(如何判断相等)
在Java中,=号,表示内存地址相等,即是指向堆内存的同一引用,那么此时,显然两个元素是相等的。
当不是指向堆内存的同一引用时。我们就需要重写Object类的equals()方法了。在此,我们判断,如果我们需要比较的各个属性相等的话,那么则可认为这两个对象相等(关于属性相等的比较与此类似)
Question six: 已经存在了那么多的动态结构,为什么需要Hash表?
其实这个问题其实问的不恰当,应该是,有了诸如顺序表和有序表这样的静态表,诸如二叉排序树 平衡二叉树这样的动态表,为什么还需要Hash表呢?
因为记录在表中的位置和它的关键字之间不存在一个确定的关系。查找的过程为给定值依次和关键字集合中各个关键字进行比较。查找的效率取决于和给定值进行比较的关键字个数。
Question Seven: TreeMap 底层实现
TreeMap 底层由红黑树(Red-Black tree)实现。因为此部分内容包括算法分析,具体代码实现以及性能分析,内容比较多,所以本部分内容稍后专门用一个日志来推出。(形式类似HashMap那篇日志)
【编辑推荐】