NoSQLFan 简要翻译如下:
一、Digg提供的服务
一个社会化的新闻网站
对个人来说它又是一个私人社会化新闻发布平台
一个广告平台
一个开放API的平台
博客及文档系统
二、Digg 的核心功能
文章提交功能 – 提交你认为有价值的新闻。
文章列表功能 – 将用户提交的新闻做各种不同纬度的列表(个人新闻,最近发布等)。
对文章的操作 – 用户可以对文章进行各种操作,包括阅读、点击、digg、评论、为评论评分等等。
置顶文章功能 – Digg会定时将一些热门的文章置顶到Digg首页,从页让更多人能够看到。
三、Digg功能的背后的实现
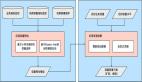
首先我们看一个流程图,描述了普通用户在使用Digg其间Digg的具体模块运作:

其实这中间的操作包括了两部分:同步和异步
对用户进行即时响应的同步操作:同步操作主要表示对用户请求(包括API请求)的即时快速响应,包括一些在页面中通过AJAX方式进行的异步请求。这些操作通常要求最长一两秒的时间内就能完成。
离线批量进行的异步计算:除了实时响应的请求外,有时候还需要进行一些批量的计算任务,这些任务可能是间接的被用户启动的,但用户不会等待这些任务的完成。这些异步计算通常可能会花费数秒,数分钟甚至几小时。
这两部分在Digg中的应用方式可以用下面这张图描述:

上面是总体概述,下面一部分我们会深入Digg的各个功能部件进行深入研究。
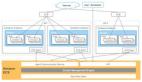
1. 在线Web系统
提供Web页面服务及API服务的部分组成如下:PHP作前端语言构建的CMS系统,Python构建的API服务器,它们运行在 Tornado 上。它们通过 Thrift 协议 与主存储层进行交互,很多数据会被如Memcached 和Redis 这样的内存缓存系统缓存。
2. 消息系统
Digg 使用 RabbitMQ 作队列系统,将不用同步响应的操作放到队列异步地进行。
3. 批量异步处理系统
上面的消息系统是指队列,而这个指的是具体从队列取出任务执行的部分。此系统将任务从队列中取出,进行一定的计算后再对主存储进行操作,对主存储的操作在实时系统和异步批量系统中都是一样的。
4. 数据存储层
数据存储层Digg使用了多个产品来完成各种不同的任务,具体列表如下:
Cassandra:对诸如文章、用户、Digg操作记录等“Object-like”的信息,都是使用Cassandra来存储的。我们使用的是Cassandra0.6版本,由于0.6版本并没有劫持二级索引,于是我们将数据通过应用层处理后再用它进行存储。比如我们的用户数据层提供通过用户名及Email地址来查询用户信息的接口。
HDFS:主要用到日志信息存储及分析计算,利用 Hive 操作 Hadoop,进行MapReduce计算。
MogileFS:是一个分布式文件存储系统,用以存储二进制的文件,比如用户头像,截屏图片等。当然,文件存储的上层还有统一的CDN。
MySQL:目前我们的文章置顶功能上使用了MySQL存储一些数据,因为这一功能需要大量的JOIN操作。与此同时 HBase 好像也是个不错的考虑。
Redis:由于 Redis 的高性能及其灵活的数据结构,我们用它来提供对 Digg Streaming API 的存储,同时我们还用Redis 来构建实时浏览和点击计数器。
SOLR:用来构建全文索引系统。以提供对文章内容、话题等的全文检索。
Scribe:日志收集系统,比syslog-ng更强大更简单。用它收集的日志会被放到HDFS进行分析计算。
5. 操作系统及配置
Digg runs on Debian stable based GNU/Linux servers which we configure with Clusto, Puppetand using a configuration system over Zookeeper.
原文链接:http://blog.nosqlfan.com/html/1575.html
【编辑推荐】