前言:单点问题是单点故障(Single Point of Failure)造成系统失效的通俗说法。对于单点问题,我们解决的方案一般是采用冗余设备或者热备,因为硬件的错误或者人为的原因,总是有可能造成单个或多个节点的失效,有时我们做节点的维护或者升级,也需要暂时停止某些节点,所以一个可靠的系统必须能承受单个或多个节点的停止。
我原本的架构是由DRBD和MooseFS所组成,DRBD实现了基于网络的raid 1,HA和Pacemaker实现基于策略的故障转移;而MooseFS由于设计了meta server,到目前为止还没有做系统级冗余的计划。但是,meta server并不能实时自动切换,所以,只有我们自己来设计了。这篇就是介绍如何设计实施故障的自动切换,以及故障排除后的自动恢复。
名词定义
单点故障(Single Point of Failure)(引用来源)
引起产品故障的,且没有冗余或替代的工作程序作为补救的局部故障。(GJB451-90)
单点失效是导致一项产品完成任务的性能不可逆转地降低到合同规定水平以下的单一硬件失效或软件差错(产品发生单点失效的方式就是产品的单点失效模式)。(MIL-STD-1543B-88)
某产品的失效将导致系统的失效,且不能由贮备或代替的工作程序来补偿。(MIL-STD-721C-81)
高可用
高可用(HA)有两种不同的含义,在广义环境中,是指整个系统的高可用(High Availability)性,在狭义方面,一般指主机的冗余接管,如主机HA,如果不特殊说明,本书中的HA都指广义的高可用性。在高可用的解释方面,可以分为如下一些方面:
(1)系统失败或崩溃(System faults and crashes)
(2)应用层或者中间层错误(Application and middleware failures)
(3)网络失败(Network failures)
(4)介质失败,一般指存放数据的媒体介质故障(Media failures)
(5)人为失误(Human Error)
(6)分级与容灾(Disasters and extended outages)
(7)计划宕机与维护(Planned downtime, maintenance and management tasks)
以下为具体描述与实现步骤。
用途:
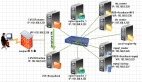
解决mfs master的单点问题,同样可以作为其他需要高可用环境的标准配置方法
规划:
使用drbd实现主备机的灾容,Heartbeat做心跳监测,Pacemaker实现服务(资源)的切换及控制等
描述:
drbd双主模式对网络和配置要求比较高,在此结构下不采用;
drbd需要清空一个分区,并且不能格式化
可单独由heartbeat实现服务的切换及failover;
需要ha项目中的其他组件,如GLUE和ResourceAgent。
软件:
DRBD下载地址:http://oss.linbit.com/drbd/
DRBD 8.3.9: drbd-8.3.9.tar.gz
HA下载地址:http://www.linux-ha.org/wiki/Downloads
Heartbeat 3.0.4: Heartbeat-3-0-STABLE-3.0.4.tar.bz2
Cluster Glue 1.0.7: glue-1.0.7.tar.bz2
Resource Agents 1.0.3: agents-1.0.3.tar.bz2
Pacemaker 1.0.5: Pacemaker-1.0.5.tar.bz2
mfs下载:http://www.moosefs.org/index.php/download.html
moosefs 1.6.20: mfs-1.6.20-2.tar.gz
环境:
mfsmaster:192.168.1.1 mfsbackup:192.168.1.2 VIP:192.168.1.10
安装:
设置hosts:
# vi /etc/hosts 192.168.1.1 mfs.master 192.168.1.2 mfs.backup
DRBD:
# wget http://oss.linbit.com/drbd/8.3/drbd-8.3.9.tar.gz # tar zxvf drbd-8.3.9.tar.gz # cd drbd-8.3.9 # ./configure --prefix=/usr/local/drbd --with-km # make && make install # vi /usr/local/drbd/etc/drbd.d/ global_common.conf syncer { # rate after al-extents use-rle cpu-mask verify-alg csums-alg rate 100M; } # vi /usr/local/drbd/etc/drbd.d/ mfs.res resource mfs { device /dev/drbd0; disk /dev/lvm/mfsdata; meta-disk internal; on mfs.master { address 192.168.1.1:7789; } on mfs.backup { address 192.168.1.2:7789; } } # cp /usr/local/drbd/etc/rc.d/init. d/drbd /etc/init.d/ # insmod /lib/modules/2.6.18-8.el5/ kernel/drivers/block/drbd.ko # modprobe drbd # chkconfig --add drbd # chkconfig --level 35 drbd on # service drbd start # drbdadm create-md all # mkfs.ext3 /dev/drbd0 # vi /etc/fstab /dev/drbd0 /mfsmeta ext3 defaults,noatime,nodiratime 0 0
以上主备机同样的配置,查看同步状态:
# cat /proc/drbd GIT-hash: 1c3b2f71137171c1236b497969734da43b5bec90 build by root@mfs.master, 2010-12-20 19:19:37 0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r----- ns:89190240 nr:613604 dw:89803844 dr:620461 al:45275 bm:5 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
在主机上执行:
# drbdsetup /dev/drbd0 primary -o # mount /mfsmeta
至此drbd安装完成,可以根据文档,做一些测试。
MFS:
# wget http://pro.hit.gemius.pl/
设置临时hosts,测试mfs启动:
# vi /etc/hosts 192.168.1.1 mfsmaster # /usr/local/mfs/sbin/mfsmaster start
mfs master安装完成,
HA:
配置:
# export PREFIX=/usr # export LCRSODIR=$PREFIX/libexec/lcrso # export CLUSTER_USER=hacluster # export CLUSTER_GROUP=haclient # getent group ${CLUSTER_GROUP} >/dev/null || groupadd -r ${CLUSTER_GROUP} # getent passwd ${CLUSTER_USER} >/dev/null || useradd -r -g ${CLUSTER_GROUP} -d /var/lib/heartbeat/cores/hacluster -s /sbin/nologin -c "cluster user" ${CLUSTER_USER}
GLUE:
# wget -O cluster-glue.tar.bz2 http://hg.linux-ha.org/glue/archive/tip. tar.bz2 # tar jxvf cluster-glue.tar.bz2 # cd Reusable-Cluster-Components-* # ./autogen.sh && ./configure --prefix=$PREFIX --with-daemon-user=${CLUSTER_ USER} --with-daemon-group=${CLUSTER_ GROUP} # make # make install
Resource Agent:
# wget -O resource-agents.tar.bz2 http://hg.linux-ha.org/agents/ archive/tip.tar.bz2 # tar jxvf resource-agents.tar.bz2 # cd Cluster-Resource-Agents-* # ./autogen.sh && ./configure --prefix=$PREFIX # make # make install
Heartbeat:
# wget -O heartbeat.tar.bz2 http://hg.linux-ha.org/dev/archive/tip. tar.bz2 # tar jxvf heartbeat.tar.bz2 # cd Heartbeat-* # ./bootstrap && ./configure --prefix=$PREFIX # make # make install # cp doc/ha.cf $PREFIX/etc/ha.d/ # cp doc/authkeys $PREFIX/etc/ha.d/ # chmod 0600 $PREFIX/etc/ha.d/authkeys
配置heartbeat:
# vi $PREFIX/etc/ha.d/ha.cf debugfile /opt/logs/heartbeat/ha-debug logfile /opt/logs/heartbeat/ha-log logfacility local0 keepalive 2 deadtime 30 warntime 10 initdead 120 udpport 694 ucast eth0 192.168.1.2 auto_failback on ping 192.168.1.254 respawn hacluster /usr/lib64/heartbeat/ipfail crm on # service heartbeat start
具体配置说明请参考文档。
Pacemaker:
# wget -O pacemaker.tar.bz2 http://hg.clusterlabs.org/pacemaker/ stable-1.0/archive/tip.tar.bz2 # tar jxvf pacemaker.tar.bz2 # cd Pacemaker-1-0-* # ./autogen.sh && ./configure --prefix=$PREFIX --with-lcrso-dir=$LCRSODIR # make # make install # ldconfig -v # crm crm(live)# configure node mfs.master crm(live)# configure node mfs.backup crm(live)# configure primitive mfsmaster_drbd ocf:linbit:drbd params drbd_resource="mfs" drbdconf="/usr/local/drbd/etc/ drbd.conf" meta migration-threshold="10"
crm(live)# configure monitor mfsmaster_drbd 30s:20s
crm(live)# configure primitive mfsmaster_fs ocf:heartbeat:Filesystem params device="/dev/drbd0" directory="/mfsmeta" fstype="ext3"
crm(live)# configure primitive mfsmaster_vip ocf:heartbeat:IPaddr2 params ip="192.168.1.10" nic="eth0:0"
crm(live)# configure primitive mfsmaster lsb:mfsmaster
crm(live)# configure monitor mfsmaster 30s:30s
crm(live)# configure group mfsmaster_group mfsmaster_vip mfsmaster_fs mfsmaster
crm(live)# configure ms mfsmaster_drbd_ms mfsmaster_drbd meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true"
crm(live)# configure colocation mfsmaster_colo inf: mfsmaster_group mfsmaster_drbd_ms:Master
crm(live)# configure order mfsmaster_order inf: mfsmaster_drbd_ms:promote mfsmaster_group:start
crm(live)# configure property $id="cib-bootstrap-options" expected-quorum-votes="2" stonith-enabled="false" no-quorum-policy="ignore" start-failure-is-fatal="false"
crm(live)# configure commit
crm(live)# quit
设置VIP为mfsmaster:
# vi /etc/hosts 192.168.1.10 mfsmaster
可以使用crm_mon查看资源状态,如果正常应该是类似:
# crm_mon ============ Last updated: Sun Jan 23 14:01:53 2011 Stack: Heartbeat Current DC: mfs.backup (985860ea-ae2b-4490-b7e9-19f902321358) - partition with quorum Version: 1.0.10- b0266dd5ffa9c51377c68b1f29d6bc 84367f51dd 2 Nodes configured, 2 expected votes 2 Resources configured. ============ Online: [ mfs.master mfs.backup ] Resource Group: mfsmaster_group mfsmaster_vip (ocf::heartbeat:IPaddr2): Started mfs.master mfsmaster_fs (ocf::heartbeat:Filesystem): Started mfs.master mfsmaster (lsb:mfsmaster): Started mfs.master Master/Slave Set: mfsmaster_drbd_ms Masters: [ mfs.master ] Slaves: [ mfs.backup ]
至此,mfs的高可用环境搭建完成,可以使用crm node stndby和crm node online进行资源测试。
原文:http://hi.baidu.com/leolance/blog/item/7ac035205870f020c9955905.html
【编辑推荐】