Quora网站由Facebook前雇员查理·切沃(Charlie Cheever)和亚当·安捷罗(Adam D' Angelo)于 2008年创办,是一款问答SNS 产品,目前拥有11名雇员,共融资超过1100万美元,产品还未上线,就被估值8000万美元。文中阐述了Quora的技术架构,记录一些值得关注的信息。
文章内容如下:
使用云计算服务
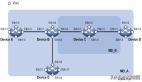
Quora大量使用Amazon EC2 与 S3服务;操作系统部署的是Ubuntu Linux,易于部署和管理;静态内容用Cloudfront.服务分发,图片先传到EC2服务器,使用Pyhon S3 API 处理后后传到S3。
从开始就使用云计算服务的的好处是节省了大量人工维护硬件服务器的成本,当然这个做法在咱这片土地上不太可行。

(refer:Copyright)
Web层与CMS
HAProxy作为前端负载均衡服务器,反向代理服务器是Nginx,Nginx后面则是Pylons(Pylons + Paste),承担动态Web请求。
Webnode2与LiveNode这两个内部系统承担创建、管理内容的重任,Webnode2生成HTML、CSS与JavaScript,并且与LiveNode轻度耦合。LiveNode的作用用以显示Web页面内容。用Python、C++与JavaScript写的。特别提到用到了jQuery与Cython。LiveNode有可能开源。
为什么用Python?
前面已经提到了一些Python相关的技术组件。有意思的是从Facebook出来的团队居然用Python作为主要开发语言。Quora对此有所解释:Facebook选择PHP也并非是最佳选择,而是有历史原因。Quora技术团队在考察了多个语言之后选择的Python,当然理由有一大堆,总体看来,并非很激进。
通信处理
后端通信使用的是Facebook开源出来的Thrift,除了开发接口简单之外,可能更为熟悉也是一个因素吧:)Comet服务器使用的是Tornado,用以处理Long polling以及Push 更新(不知道知乎用的什么?),Tornado是前FriendFeed技术团队开源的产品。
实时搜索
因为Sphinx不能满足实时性方面的要求,Quora启用了自己开发的搜索引擎,只使用了Thrift与Python Unicode库,此外没有用别的。Quora的搜索比较特别,因为要对输入内容做关联并且要做有效提示,所以需要提供更好的前缀索引(Prefix indexing)功能。
Quora搜索的实现还是挺有技术含量的,对后端的查询请求压力也不小(或许当前的并发请求量还没那么大)。对这个场景,做相关开发的朋友不妨仔细研究一下。如果大体框架类似,那么决定最后生出的因素很可能是那些细节。
数据持久层
大量使用MySQL作为存储方案,Memcached作Cache层。没有使用当前比较火爆的NoSQL相关产品。Quora这样做有自己的理由,用户量级没有达到百万的SNS站点完全没必要用NoSQL的东西。或许以后Quora也会启用。
创始人查理·奇弗(Charlie Cheever)与亚当·德安杰洛(Adam D'Angelo)之前都在Facebook,所以,Quora的技术还真有不少Facebook的基因。Quora的团队规模并不大,做技术的估计十余人而已,这么紧凑的团队利用了这么多的技术与产品,可见很多人都是多面手了。这是国内技术团队需要向国外同行学习的地方。
EOF
这只是一篇概要性的描述,如果要知道一些更为细节的东西,请看Quora上的相关评论,上文中已经给出相关链接。
【编辑推荐】