












Perst 是McObject 公司发布的一款非常袖珍的开源嵌入式数据库, 是一个简单, 快速, 便捷, 面向对象, 适合java 与.NET 的数据库。Perst 不需要专门的编译器与预处理器, 支持ACID 事务。官方站点:http://www.mcobject.com/perst
Perst 可以免费自由下载,并免费在非商业用途使用。
McObject 主要销售技术支持,同时销售商业license。
在 Perst得dual license下,用户可以修改源代码并使用于非商业用途。
Perst 是一个开源嵌入式数据库软件, 能够有效的处理移动设备上的大量数据。对于在资源受限的移动设备( 如手机, PDA 等)上存储大量数据和对数据进行频繁的IO 操作往往要消耗很多的设备资源。由于移动设备内存小, 性能较差, 如果采用关系数据库( 如SQLServer2000, Oracle) 管理数据, 仅靠其有限的内存资源是不能运行这些数据库管理系统的, 这样就有必要采用一些特殊的数据库系统。Perst 数据库正是为这类设备研究开发的, 它们的作用是在资源受限的设备上完成大量数据的访问操作。其实这些设备系统资源主要消耗在从磁盘上读取数据的IO 操作。如何提供一种有效的文件存储策略来降低对磁盘的IO 操作是嵌入式数据库软件设计的主要任务。
像其他嵌入式数据库一样,Perst没有管理上的代价,但不同的是Perst直接将对象以Java或者C#对象的形式进行存储。因此不需要在对象的内部表现形式和Java/C#表现形式之间转换。这个数据库引擎非常精悍,只有约5000行代码,McObject对此感到骄傲。根据访问模式不同,运行时需要30K到300K的内存
其他特性列举如下:
● 垃圾收集
● 对挂起的引用的探测
● 自动的schema更新(evolution)
● XML的导入/导出功能
● 支持主-从复制
● 可以过滤任何集合元素的一个SQL子集 ● 与AspectJ和JAssist AOP工具集成
Perst 支持 .Net 下的 Linq。
下面将着重介绍Perst 嵌入式数据库的文件存储策略和B+ 树索引结构
一、Perst 基本概念介绍
1. 页Page
Perst 对数据库文件的基本操作都是以页为单位进行的。这些基本操作包括: 内存分配、从数据库文件中读取数据、将内存中的数据写入文件等。Perst 一页默认的大小是4K。
2. 对象标识符OID
Perst 创建的每个对象都是可以持久化的, 即它可以被保存在数据库文件中。每个持久化的对象都会用对象标识符( OID) 引用, 通过对象标识符, 程序可以从数据库文件中找到该对象在文件中实际存放位置。
3. Root Object
Perst 的每个数据库文件都必须有且只能有一个称作RootObject 的类。在这个类中定义了数据库文件中的所有索引结构。通过这个类, 程序可以定位到数据库文件中的所有记录对象。
二、数据库Header 信息的存储格式
Perst 数据库文件开始的***页中, 前139 个字节存放Perst 数据库使用情况和数据库当前状态等Header 信息。它在文件中的数据结构如图1 所示。表1 到表4 对图1 中Header 信息中的每个数据做了详细分析。数据意义如表所示。



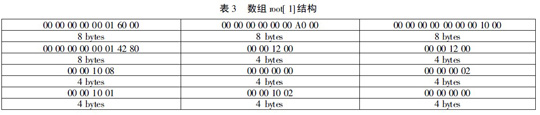
数组root[ 1] 是root[ 0] 的备份, 每个元素对应的意义相同
![]()
数据库文件的***页( 4K) 存放了整个数据库文件的Header 信息。程序从数据库文件的Header 信息中分离出数据库文件的使用
情况和索引结构的存储位置, 这样可以很快的定位数据库中的记录数据。
三、Perst 的Object Index 存储结构
Perst 专门开辟了一段空间, 称Object Index 区, 存放持久化对象在文件中的实际存储位置。一般这个区在文件的第2- 10 页, 第11- 19 页存放这个区的备份。第2- 9 页的数据被标识为空闲文件区, 第10 页存放实际Object Index。在Object Index 区中, 每个元素称为Object Handle, 每Object Handle 用8 个字节表示, 存放对应对象在文件中的实际存储位置, 即对象的OID。对于4K 的页, 可以存放512 个Object Handles。Object Index 区的结构如图2 所示。

在图2 的0x00012000h 位置以前都是空闲区, 之后的才是真正存放Object Handle 的Object Index 区。如果Perst 数据库文件中的持久化对象的OID 个数超过512 个, Perst 会在数据库文件的另一个区开辟更大的存储空间充当Object Index区, 以存放更多的Object Handle。
四、Perst 记录数据及类的存储结构
Perst 中记录数据存放位置是根据当前数据库的使用情况来为记录数据分配存储空间。Perst 中每个记录数据的存放格式都是统一的, 每个记录数据的开头占用8 个字节存放记录数据的基本信息。前4 个字节存放这条记录占用的字节个数, 后4 个字节存放构建这个记录对象的类的OID, 通过这个OID 就可以动态的加载该类的对象。以类Test. User 的记录为例, 该记录包含一个int 类型的数据和一个变量名为 name 的String 类型, 其存储结构如表5 所示

在Perst 中数据都是保存在对象中的, 首先要将对象的每个成员转换成字节数组的形式, 然后在此字节数组前面加上8 个字节的记录数据基本信息, 然后将该对象的整个字节数组保存在文件的相应位置。
实际上Perst 在保存记录数据之前都要将记录数据的类信息保存在数据库文件中, 主要目的是实现类对象的动态加载。以类Test. User 为例说明类的存储结构, 它的两个成员int 类型( Id) 和String 类型( Name) 。Perst 先保存类的成员变量Id 和Name 的信息, 然后保存类信息。图2 是Test. User. Id 的存储结构,Test.User. Name 的存储结构和表6 类似。

类Test.User 的存储结构如表7 所示:

以上是Perst 保存记录对象类相关信息的存储结构, 这样Perst 可以动态的加载类对象。
五、B+ 树的存储结构
Perst 之所以能够应用在移动设备上, 最主要的原因是它采用了存取方式效率高的B+ 树结构。Perst 定义的B+ 树节点大, 使得构建出的B+ 树宽度大而深度小, 这样设备进行检索的时候, 减少了对磁盘IO 操作的次数, 从而降低了设备的资源消耗。
1. B+ 树的节点及其构成
Perst 的B+ 树节点用一个页来表示( 4K) , 每个节点中包含4 个字节的节点信息和多个< key, value> , 节点信息中前2 个节点表示节点中< key , value> 对的个数, 后2 个字节表示索引值占用的总字节数。< key, value> 中value 表示索引值, key 表示对子节点或者是记录数据对象的OID。索引值的类型不同, Perst 节点的结构也不同。
( 1) 索引值的类型是类
当索引是用类创建的时候, 在节点的< key, value> 对中,索引值就是该记录对象的OID, key 是该记录对象的OID 或者是子节点页对象的OID。以< OID1, OID3> , < OID2, OID4> 为例, 其中OID1 和OID2 是key, OID3 和OID4 是索引值, 且OID3< OID4 其结构如下图3 所示:图3

( 2) 索引值的类型是数值类型( 如int, long, short 等)
当创建索引的类型是数值类型时, 节点< key, value> 中,索引值就是该数值, key 是子节点的OID 或者是和索引值相关的记录对象的OID。以< OID1, 100> , < OID2, 125> 为例说明其存储结构, 其中索引值的类型是int, 存储结构如图4所示:

对于这种类型的索引值, value 占用多大的空间, 是根据数值类型实际占用的空间进行分配的。
( 3) 索引值的类型是字符串或字节数组类型
对于这种类型的索引结构, 在保存索引值的时候并不只是保存字符串或字节数组, 还会保存字符串的一些信息, 如字符串的字符个数, 字符串在该节点中存放的相对位置。以< OID1, teacher > 为例, 其存储结构如下图所示:
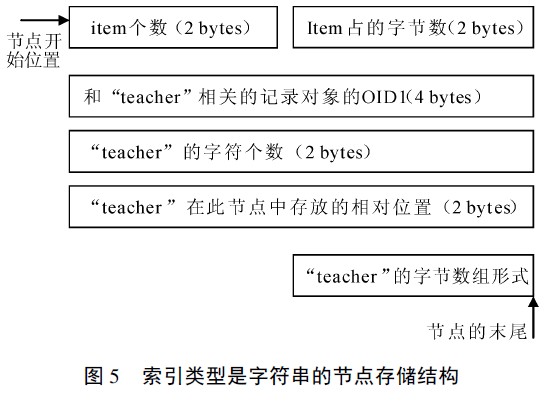
从以上三种不同类型的节点存储结构, 可以看出B+ 树节点存储结构的共同点。( 1) 节点的前4 个字节保存该节点的基本信息;
( 2) < key, value> 的存放:一个从节点页的开头按照其插入的顺序存放( 从前向后) , 另一个则是从节点页的末尾开始存放( 从后向前) 。这样处理的好处是可以很快地从节点中取出< key,value> , 不用经过很复杂的计算过程, 节省了设备资源的使用。
2. B+ 树在内存中的重建
Perst 将整个B+ 树的结构保存在数据库文件中, 当程序对数据操作的时候如何将整个B+ 树装入内存呢?Perst 中有一个可以引用所有记录对象的Root Object 的类, 通过这个类Perst 除了可以动态的加载B+ 树类对象, 而且可以很快的从数据库文件中定位B+ 树根节点的文件存储位置。
Perst 找到相应的B+ 树根节点的时候, 会一次性的从数据库文件中读取一个节点大小( 4K) 的数据到内存中。由于在节点构建的时候索引值是顺序存放的, 因此程序可以用二分查找的算法在节点中查找符合条件的索引值, 如果找到就可以定位到此节点的子节点或者是和索引值对应的记录对象。如果节点是叶节点, 程序就可以从这个节点中找出和索引值对应的对象的OID, 通过OID,Perst 就可以从文件中读取到整个记录的字节数组形式, 通过类对象的动态加载机制可以把字节数组还原为记录对象的形式。
如果是内部节点, 根据内部节点的OID, Perst 会将内部节点的数据读取到内存中。这些被加载到内存中的数据会临时的存放在一个对象缓冲区, 当需要的时候就可以直接从对象索引区读取数据,而不用重复的进行IO 操作。只有对象缓冲区满时, Perst 采用LRU 置换机制把内存中的数据写入数据库文件中。
参考文献《Perst 嵌入式数据库存储结构分析与研究 》
原文链接:http://www.cnblogs.com/linzheng/archive/2011/03/06/1972282.html
【编辑推荐】












