在MySQL数据库中,表的不同部分在不同的位置被存储为单独的表。分区主要就是用来解决表在不同的位置存储的问题。在其他数据库中,也会存在这种情况。他们将这种类型的数据表称之为分区表。分区的管理,对于MySQL数据库来说至关重要。其直接跟数据库的性能与安全性息息相关。对于分区的管理,笔者只有两个字:细节。
细节一:确定所使用的版本是否支持分区
在MySQL中,并不是所有的数据库版本都支持分区管理。为此数据库管理员首先要做的就是,确认自己所采用的版本是否支持这个功能。如果支持的话,则可以在后续设计与维护时利用分区的特性来提升系统性能、提高数据安全。反之,则不行。要判断所使用的版本是否支持分区功能,可以通过系统命令来实现。如下图所示:
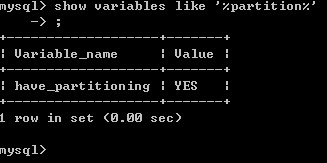
如果上面这个变量,其显示的值是YES,那么很庆幸的告诉你,你说是用的版本支持分区管理。如果这个变量的值是空白的,则表示所使用的版本不支持分区管理。笔者建议对现有的数据库版本进行升级。
对于分区管理,笔者需要强调一点,即MySQL数据库与其他数据库在分区实现上的差异。对于MySQL数据库来说,主要是通过分区函数来实现分区的控制。如这可能是一个HASH函数、或者一个数值列表。虽然数据库管理员并不需要非常了解其内部的实现机制。但是需要明确的是,采用不同的分区类型,就选择了不同的分区函数。反过来说,分区函数的特征就确定了所选择分区的特性。从这个角度来讲,掌握函数的一些基本特征,可以帮助我们更好的理解不同类型分区之间的差异。从而有利于数据库管理员根据企业的实际情况来设计合理的分区。
细节二:存储引擎与分区之间的关系
存储引擎主要用来实现对数据库数据的存储。显然这个存储引擎与分区之间有着紧密的联系。这个联系主要体现在如下这个方面。
通常情况下,对于创建了分区的数据表,数据库管理员可以使用数据库服务器所支持的任何存储引擎。也就是说,对于数据引擎来说,分区是透明的。这主要是因为在MySQL数据库中,分区引擎是在一个单独的层中运行的。并且可以和任何这样的层进行相互沟通。不过如果再深挖下去的话,这里仍然有一个细节问题需要考虑,即需要注意一个限制的规则。对于同一个分区表的所有分区都必须使用同一个存储引擎。举一个简单的例子。现在有一个数据表,其有两个数据分区,分别为A与B。此时如果数据库管理员对于分区A采用了MYISAM;那么对于分区B也只能够使用MYISAM,而不能够使用其它的,如INNODB。
这段话看起来好像有点互相矛盾的地方。其实我们可以将其总结为一句话。即不同的分区表,可以采用任何数据库所支持的数据引擎。但是对于同一个数据表的不同分区,则只能够使用同一个存储引擎。
最后需要说明的是,从存储引擎的相关信息中,并不能够看出其服务的数据表是否支持分区的功能。也就是说,不能够通过命令show engines来判断数据库是否支持分区。数据库管理员只能够通过上面的第一个命令来判断数据库分区的相关信息。
细节三:分区是一个整体,不能够进行分割
一个数据表可以根据实际情况分为多个分区。但是分割后的分区仍然是一个整体。这是什么意思呢?笔者举一个例子,各位就可以理解了。现在有一个数据表,表中有记录和索引。在进行分区设计时,不能够只对数据分区而不对索引分区,也不能够对索引分区而不对数据分区。这就好像是分蛋糕一样。蛋糕会有上下两层。在分蛋糕时,是上下两层一起分。而不会只分上面一层奶油。为此需要切记,分区时是对数据表中的所有内容进行同时分区,而不能够对部分进行分区。
另外需要注意的是,如果要对某个表进行分区,那么就需要对整个表进行分区管理。而不能够对部分进行分区。如对某个表的上半部分不执行分区,而只对下半部分进行分区管理,这是不允许的。
细节四:分区如何提高查询效率
采用分区管理,可以很好的提高查询的效率。笔者这里举一个零售企业的案例。如现在有一家超市,使用的是MySQL数据库。一家超市,每年的销售记录会有几千万条。几年累积下来,数据量非常的大。现在如果用户需要查询,去年一年某个产品的销售情况,那就像大海捞针一样,速度会非常的慢。
此时如果采用分区管理的话,会明显的提高查询的效率。在数据库设计的时候,可以根据时间来划分分区。如为每一年的数据单独设置一个分区。此时再查询2010年某个产品的销售情况时,由于指定了Where条件语句,则系统只会从2010年这个数据分区中去查找相关的内容,而会忽略其他无关的分区,从而改善数据查询效率。
在实际工作中,笔者还经常将某个表分为多个分区,然后将不同的分区放置在不同的磁盘上。此时可以通过多个硬盘来分散数据查询,来获得更大的查询吞吐量。如果企业数据库服务器中,已经使用了磁盘阵列5的话,采取这个措施就是多此一举。如果服务器中只有一块硬盘、或者虽然有多快硬盘但是没有实现磁盘阵列的话,笔者将多个分区存放在多快硬盘上的做法,还是蛮值得推荐的。如还是以零售企业为例。如果企业一年的销售记录有上亿条。此时要对这上亿条的数据进行统计分析,对于硬盘的吞吐量是一个极大的考验。此时我们可以对这个数据表进行分区。如可以根据季度将其分为四个区A、B、C、D。然后将AC两个分区放在硬盘甲上,将剩余的BD两个分区放在硬盘乙上。此时系统在读取整年的数据时,会同时从两块硬盘上读取数据。这么设计的话,硬盘的吞吐量就可以提高一倍(假设不考虑管理开销)。通过这种方式,也可以提高查询的效率。其与磁盘阵列5有异曲同工之妙。只是其实现的级别不同。
可见采用分区之后,一些查询能够得到很大的优化。这主要是因为用户可以借助于满足一个给定的Where语句的数据可以只保存在某个特定的分区内(如2010年的交易数据)。如此在查询时就不用再查找其他剩余的分区。虽然说分区可以在创建了分区表之后再进行修改。即使刚开始没有考虑到这个内容,也可以在以后有需要的时候重新组织数据,对数据表进行分区。但是笔者并不赞成这么做。因为对数据进行重新组织,就好像是重新剪贴、复制了一遍数据。在记录比较多时,这个作业会大量的消耗服务器的资源。为此笔者还是建议,在数据库设计时,管理员就需要对未来的数据量能够进行预测。如果有必要采用分区管理的,那么要提早做。
当然分区并不是对所有的企业都适用。如果企业的数据量比较少,又或者说大部分是一次性使用的数据,此时采用分区的话,不会给企业带来价值。反而会增加管理上的开销。
原文链接:http://tech.it168.com/a2011/0301/1161/000001161632.shtml
【编辑推荐】