“内存是新的硬盘,硬盘是新的磁带”此话出自图灵奖得主Jim Gray。
一、前言
我理解这句话的意思是,我们应该把随机IO都放到内存中去,而把像磁带一样的顺序IO留给硬盘(这里不包括SSD)。
如果应用没有达到一定的级别,可能我们看上面两句话都会觉得太geek,然而在应用数据量日益庞大,动态内容比例日益增大的今天,再忽视这个基本准则将会是一个灾难。
今天我们谈一下这一理论在NoSQL产品中的展现。
二、实现
问题一:宕机数据丢失
我们先看一下几个杰出的NoSQL代表,Cassandra,MongoDB,Redis。他们几乎都使用了同一种存储模式,就是将写操作在内存中进行,定时或按某一条件将内存中的数据直接写到磁盘上。这样做的好处是我们可以充分利用内存在随机IO上的优势,而避免了直接写磁盘带来的随机IO瓶颈:磁盘寻道时间。当然,坏处就是如果遭遇宕机等问题时,可能会丢失一些数据。
解决宕机丢数据的问题有两个方法:
1.实时记录操作日志
这时通常的做法是当一个写操作到达,系统首先会往日志文件里追加一条写记录,成功后再操作内存进行写数据操作。而由于日志文件是不断追加的,因此也就保证了不会有大量的随机IO产生。
2.Quorum NRW
这一理论是基于集群式存储的,其原理是如果集群有N个结点,那么如果我们每次写操作需要至少同步到W个结点才算成功,而每次读操作只要从R个结点读数据就一定能保证其得到正确结果(如果某一结点有此数据,既成功,如果所有R个结点都无数据,则说明无此数据)。而NRW之间的关系必须满足N < R + W 。其实这一理论并不难理解,我们可以将这个不等式做一下移项:R > N – W ,我们有N个结点,写的时候最少写W个才算成功,也就是W个结点有这份数据,那么N-W就是说可能没有某一份数据的最大结点数。最多可能有N-W个结点没有某一数据,那如果我们进行数据读取操作时,读到大于N-W个结点,那么必然有一个以上的结点是有这份数据的。所以要求R > N-W。
所以可能你已经想明白了,为了防止数据丢失,我们采用的实际是简单的冗余备份的方法。数据写到多台机器会比写单台机器的磁盘快吗?对。相对于直接的磁盘操作,跨网络进行内存操作可以更快。其最简单的例子就是改进的一致性hash:
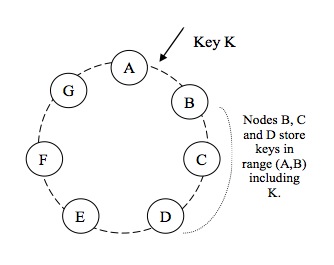
上图摘自Amazon的Dynamo文档,key的hash值位于A,B结点间的数据,并不是只存在B结点上,而是顺着环的方向分别在C和D结点进行备份。当然这样做的好处并不完全在于上面说的冗余备份。
当然,很多时候是上面两种解决方法同时使用以保证数据的高可用性。
问题二:内存容量的限制
当我们将内存当作硬盘来用的时候,我们必然会面临容量问题。这也是我们上面说到的数据会定时flush到磁盘的原因,当内存中的数据已经超出可用内存的大小,那么我们就需要将其进行落地操作,对swap的过度使用是不符合我们初衷的,也是达不到高效随机IO的效果的。这里也有两种解决方案:
1.应用层swap
采用这种方法的有TokyoCabinet和Redis两个产品。TokyoCabinet主要是通过mmap提高IO效率,而其mmap到的只有数据文件头部的一部分内容。一旦数据文件大于其设置的最大mmap长度(由参数xmsize控制),那剩下的部分就是纯粹的低效磁盘操作了。于是它提供了一种类似于Memcached的缓存机制,通过参数rcnum配置,将一些通过LRU机制筛选出来的热数据进行key—value式的缓存,这一部分内存是和mmap占用的内存完全独立的。同样的,Redis在2.0版本之后增加了对磁盘存储的支持,其机制与TokyoCabinet类似,也是通过数据操作来判断数据的热度,并将热数据尽量放到内存中。
2.多版本的数据合并
什么叫多版本的数据合并呢?我们上面讲Bigtable,或其开源版本Cassandra,都是通过定时将内存中的数据块flush到磁盘中,那么我们会想,如果这次是一个update操作,比如keyA的值从ValueA变成了ValueB,那么我们在flush到磁盘的时候就得执行对老数据ValueA的清除工作了。而这样,是否就达不到我们希望进行顺序的磁盘IO的目的呢?没错,这样是达不到的,所以Bigtable类型的系统确实也并不是这样做的,在flush磁盘的时候,并不会执行合并操作,而是直接将内存数据写入磁盘。这样写是方便很多,那读的时候可能会存在一个值有多个版本的情况,这时就需要我们来进行多版本合并了。所以第二种方法就是将一段时间的写操作写成一个块(可能并非一个文件),保证内存的使用不会无限膨胀。在读取时通过读多个文件块进行数据版本合并来完成。
那如果存储在磁盘的数据量是内存容量的很多倍,我们可能会产生许多个数据块,那么我们在获取数据版本时,是否需要全部遍历所有数据块呢?当然不用,如果你看过BigTable论文,相信你还记得它其中用到了bloom-filter算法。bloom-filter算法最广泛的应用是在搜索引擎爬虫中,它用于判断一个URL是否存在于已抓取集合中,这一算法并不百分之百精准(可能将不在集合中的数据误判为在集合中,但不会出现相反的误差),但其在时间复杂度上仅是几次hash计算,而空间复杂度也非常低。Bigtable实现中也用到了bloom-filter算法,用它来判断一个值是否在某一个集合中。而由于bloom-filter算法的特点,我们只会多读(几率很小),不会少读数据块。于是我们就实现对远远大于物理内存容量的数据的存储。
三、结尾
好了,就写到这里,关于NoSQL中对此原理的应用还有更多理解和认识的同学,欢迎交流。
原文链接:http://lgone.com/html/y2010/801.html
【编辑推荐】