假设有这样一个游戏,一个人来出加减乘除的题目给很多小朋友来做,对每一个小朋友,给他出一道题目,然后让他算好后给你报告答案,你再给他出一道题目,周而复始如此。如果有十个小朋友在算,还可以欣赏小朋友抓耳挠腮的样子;如果有一百个小朋友,每个人都在争着表现,叫嚷着让出题,这个人肯定不堪重负;如果有成千上万个小朋友呢?这个人疯了。
面对这样的场景,学生时的经验是不断地改进和优化算法;而工作以后的经验是再拽的算法也难以抵挡海量的数据或任务,主要还是增加资源,其次才是优化算法,两者可并行。小朋友越多,相应地增加出题人的数量,也可以缓解每个人的压力。
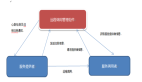
与这种场景类似,MapReduce框架也面临类似的问题。如下图:
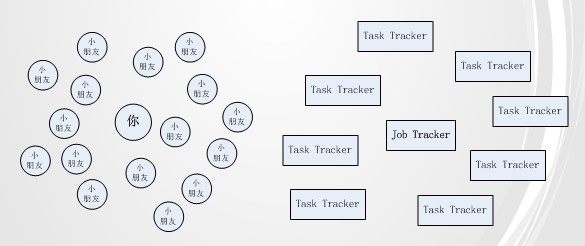
越来越多的task tracker会让job tracker很有压力,以至于task tracker有很多时,job tracker不能及时响应请求,很多task tracker就空闲着资源,等待job tracker的response。Job tracker的压力与task tracker的资源浪费问题导致整个集群难于扩展,对外提供服务的能力也相当下降很多。当前Yahoo也受此困扰,正酝酿重构MapReduce架构。我没从这个架构看出对现有问题的改善之处,所以自己来试着分析下解决方法。
回头来看模拟场景,如果把小朋友按班分,每个班都有一位老师。每位老师从出题人那里得到很多题目,然后让自己班的小朋友来做。这样,出题人的压力在于老师的数量,老师的压力在于班里小朋友的数量。以前小朋友数量增加带给出题人的压力,现在分摊到老师就会成倍地减少。与之前相比,不同处在于引入了老师这个角色。
如果以同样方式解决MapReduce问题,那“老师”的角色应该由谁来扮演呢?MapReduce的初衷之一是“尽量移动计算而不是数据”。假如数据存放于HDFS这样的文件系统上,移动数据的成本在于机器之间的带宽限制,由此HDFS网络拓扑结构表示机器之间数据移动的等级。MapReduce的map task会去访问HDFS的存储block,如果block在机器本地或是与task tracker 在同一rack内,对执行没有太大影响,否则集群带宽会严重影响task执行效率。
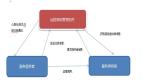
从上述描述来看,影响task执行的***网络拓扑范围是rack。一般来说,Rack间的网络带宽肯定要比rack内的带宽小。那我们就以rack来作为“老师”的角色。以此假设,我们在每个rack内将某台机器设为secondary job tracker,负责rack内task资源的调度与分发单位。结构图如下:
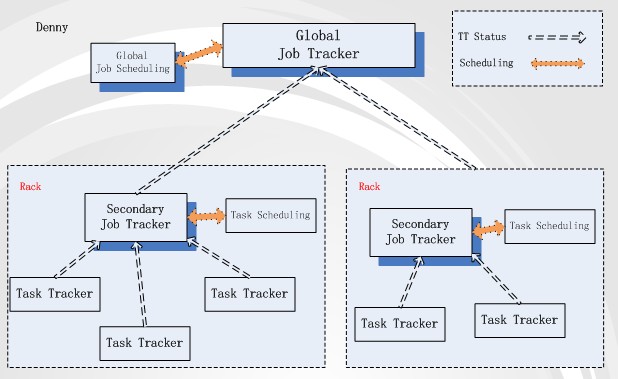
这个结构有两种job tracker:Global job tracker与Secondary job tracker。Global JT负责跨rack的task分发与调度。基本task分配策略是根据job输入数据的block存储情况,只分配block在当前rack内的map task到rack上,分配reduce task 到 map task多的rack上。Secondary JT与Global JT保持着心跳,它管理的map task操作数据要么是node-local,要么是rack-local cache 级别,不会再有map task跨rack取数据的场景,所以分发策略就很简单了。
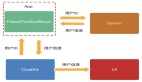
在这个结构下,client提交job的流程就变成:1. Client上传job相关的输入数据到HDFS上,HDFS会将block幅本存放与不同的data node上,这些data node有在同一个rack内,也有跨rack存在的。2. job提交到Global JT后,根据block存储情况(在哪些rack上存在block就往哪些rack的Secondary JT发送map task,且根据rack上map task的多少来分发reduce task)。3. Secondary JT向Global JT汇报当前rack内的资源情况,得到那些自己rack内的task。4. Secondary JT响应本rack内的TT 心跳,然后分配适合的task来执行。
以rack划分MapReduce架构,也是考虑到HDFS与网络带宽情况的结果。如果每个rack内有15到20台机器,10000台机器差不多可以分布到七八百rack内。Global JT与Secondary JT的并发压力都不大。这样的垂直扩展只是暂时解决了部分问题,但没有从根本上解决job分配程序的压力。
上述只是我的个人想法,希望得到各位的指正及建议,谢谢!
【编辑推荐】