












首先从博客园的Jerome Wong网友说起
他提出了一个这样的问题
本人写了好几年SQL语句了,从来没注意到这件事情。
例如:
数据表如下:
ID EMPNO NAME AGE
1 26929 Jerome 28
2 28394 Quince 27
3 20983 Green 30
4 27189 Mike 30
5 23167 Arishy 30
6 26371 Yager 29
我写了SQL语句想取得第3、4笔数据,测试分页玩的。
- select top 2 * from (select top 4 * from Member ) m
- order by m.RowID desc
我执行中间那一段子查询:select top 4 * from Member
取得的是:
1 26929 Jerome 28
2 28394 Quince 27
3 20983 Green 30
4 27189 Mike 30
但是整个SQL语句的结果却是:
5 23167 Arishy 30
6 26371 Yager 29
真的不知道到底怎么会出现这种情况,请高手指教。
其实不管你是新手还是高手在写程序当中经常会碰到类似这样的细节问题
下面我就对Jerome Wong网友所提出的问题针对select top做出一系列的分析(在这里要感谢Jerome Wong网友提出的这个问题)
准备工作
- if object_id('zhuisuo')is not null
- drop table zhuisuo
- go
- create table zhuisuo
- (
- id int null,name varchar(20) null
- )
- insert into zhuisuo values(1,'追索1')
- insert into zhuisuo values(2,'追索2')
- insert into zhuisuo values(3,'追索3')
- insert into zhuisuo values(4,'追索4')
- insert into zhuisuo values(5,'追索5')
- insert into zhuisuo values(6,'追索6')
- insert into zhuisuo values(7,'追索7')
- insert into zhuisuo values(8,'追索8')
- insert into zhuisuo values(9,'追索9')
- insert into zhuisuo values(10,'追索10')
- go
下面我们来简单写两句Select语句
- select top 2 * from (select top 4 * from zhuisuo) m order by m.id desc
- select top 2 * from (select top 4 * from zhuisuo order by id asc) m order by m.id desc
执行结果大家会发现

平常很多人会认为这两条语句执行的结果会一样
怎么会这样呢?
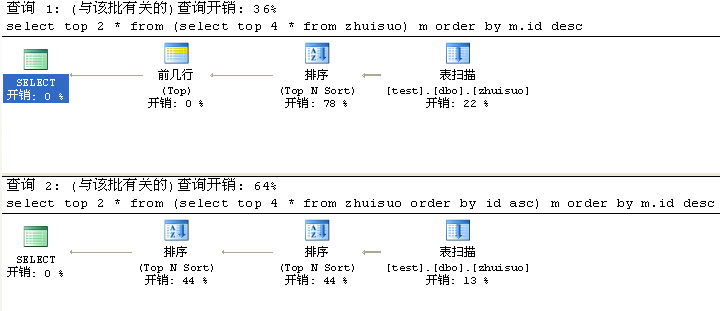
从这个查询计划中大家可以清楚的看到
***种扫描完zhuisuo表后先降序(top N Sort)然后在4行范围中取前2行
第二种扫描完zhuisuo表后先升序取4行(top N Sort)然后再把这4行降序取2行(top N Sort)
在这里就不得不简单的说说SQL语句中出现的表子查询了
表子查询,而出现在from子句中的表我们称为派生表
派生表是虚拟的,未被物理具体化,也就是说当编译的时候
如(select top 2 * from (select top 4 * from zhuisuo) m order by m.id desc )
外部查询和内部查询会被合并,并生成一个计划
这时再看看上面的执行计划就一目了然了
(注意事项:在派生表里面一般不允许使用order by除非指定了top
也就是说select top 2 * from (select * from zhuisuo order by id asc) m order by m.id desc这句语句是不能执行的)
派生表是个拟表要被外部引用,而order by返回的不是表而是游标.所以只用order by的话是被限制的
然而为什么使用top加order by又可以了
是因为top可以从order by返回的游标里选择指定数量生成一个表并返回
接下来我再举例关于top需要注意的细节
1、使用top返回随机行,很多人会想到用RAND函数从而得到这样一个语句
- select top 4 id,name from zhuisuo order by rand();
经过多次查询后,你会失望的发现它没有返回随机行
这是因为每个查询只调用它一次而不是每行调用它一次
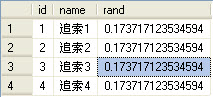
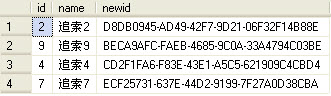
这时我们可以把RAND改为Newid
- select top 4 id,name from zhuisuo order by newid();
这时就会得到你想要的结果了,在这里我们可以意识到NEWID具有更好的分布特性
2、注意insert中使用top
- insert top (4) into zhuisuo
- select * from zhuisuo order by id desc
很多网友会解释为把zhuisuo表中***4条插入表
但执行完毕后又会让你失望了,插入的是最前面的4条
正确的倒叙插入top方法应该是
- insert into zhuisuo
- select top (4) * from zhuisuo order by id desc
这两条语句又有什么区别
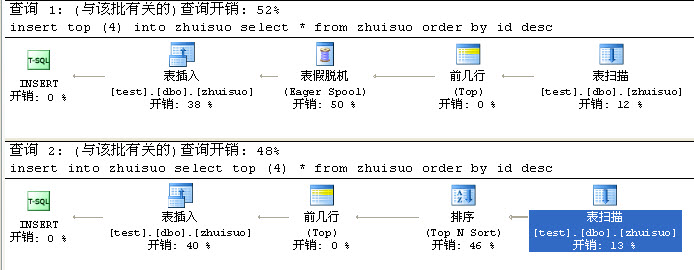
其实第上面那条语句更本就没有排序(Top N Sort)
3、有时我想删除数据表里面时间最近的5条数据怎么办
delete 和update使用top的时候不能使用order by
现在我们可以这样来解决
- delete zhuisuo
- where id in (select top(5) id from zhuisuo order by id desc)
- update zhuisuo
- set name='追索'+namewhere id in (select top(5) id from zhuisuo order by id desc)
这是变相实现Top N sort更新或删除数据 但这不是***的方法因为这还要根具id去匹配
这时我们可以使用这种方法
- with cte_del as(select top(5) *
- from zhuisuo order by id desc)
- delete from cte_del
- with cte_del as
- (select top(5) * from zhuisuo order by id desc)
- update cte_del set name='追索'+name
4、top除了这些还有更多的用处,就比如之前我使用Top N sort 加 apply回答过一个网友的问题
如何查询某用户近一个月内正确率大于60%的阅读记录,每天只显示符合条件正确率***的那个

在这里我只稍微提一下关于apply 也有很多有意思的细节 今后有时间我会用随笔形式写出来
***附上一张关于我用序号表示逻辑查询处理的步骤

原文链接:http://www.cnblogs.com/zhuisuo/archive/2010/12/23/1914790.html
【编辑推荐】










