













在本系列之前的一篇文章,和大家提到过,其实业界已经出现很多NoSQL产品,那么笔者为什么在这些产品的基础上,研发新的NoSQL数据库呢? 因为在研发YunEngine的时候,笔者发现在业界还缺乏一款在架构上非常简洁,并同时可以适应各种云计算场景的NoSQL数据库,所以在那时本人就开始进行YunTable的开发工作。
YunTable的目标并不是做一个像BigTable那样大而全的数据库,而是主要做一个精简版的分布式Key-Value数据库,上层的云计算应用将会根据其自身的需求去利用YunTable或者做修改,从而使YunTable能适应云计算各种场景,并且非常易用。YunTable已经在10月初正式开源,并发布其0.8版,官方地址是http://code.google.com/p/yuntable/。下面将对YunTable进行分析和介绍,包括它的设计、架构和如何适应不同的云计算环境。
YunTable的设计
谈到一个NoSQL数据库的设计时,肯定离不开数据模型、分布式架构和数据存储这三方面。
在数据模型上,YunTable是Key-Value的,虽然Key-value这种数据模型在结构方面和传统的关系型相比较简单,有点类似常见的HashTable,一个Key对应一个Value,但是其能提供非常快的查询速度、大的数据存放量和高并发地操作,并非常适合通过主键(Key)来对数据进行查询和修改等操作,虽然不支持复杂的操作,但是可以通过上层的开发来弥补这个缺陷。
在分布式架构方面,YunTable选择了Single Master模式来管理整个集群,虽然这个模式存在单点失败的隐患,但是不论是在实现,还是在语义方面都非常简单,而且为了避免Master出现单点失败的情况,YunTable将会在今后版本中引入Shadow-Master这种机制。
在数据存储方面,YunTable选择了SSTable这种文件格式。简单而言,SSTable是一个用于存储已排序Key-Value对的文件格式,并且是不可变动的(Immutable),也就是写了之后,只能将其更新附加在其之后,而不能直接进行修改,这样是为了让系统能执行Disk所擅长的顺序访问,而不是随机访问。在内部格式方面,SSTable文件主要有Index和Data Block这两部分组成。在实际运行时,系统常会把Index载入内存,以确保查询的效率。
YunTable的架构
在架构方面,主要可分为Region、Master和Client这三个模块,而且这三个模块都是独立的,并负责各自的业务逻辑。
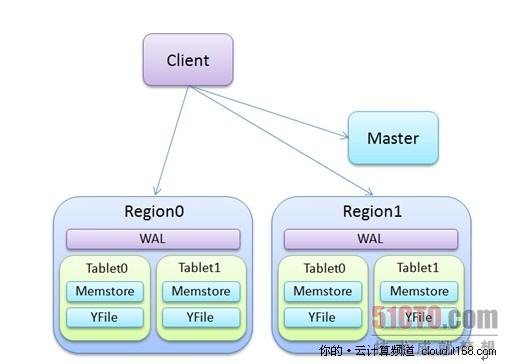
▲图1. YunTable的架构
首先,介绍一下Master节点,Master节点在功能上面属于比较“轻”调,主要负责维护Table和Region节点之间的对应关系,实际数据的查询和输入则都通过Region节点和Client端之间的交互完成,和Master节点无关,这样能有效地减轻Master节点的负担,使得其能支撑百台服务器以上的集群。举个例子,比如,当一个Client端需要处理某个Table的时候,它只需在***次处理时候,向Master请求和这个Table相关的Region节点的地址,当之后再次处理到这个Table的时候,Client端无需再和Master节点进行沟通,而是直接和相关的Region节点进行交互即可。
其次,谈谈Region节点,其作用是负责处理来自Client端的请求,并存储和管理大量的数据,Region节点非常类似BigTable论文中所提到的Tablet服务器。每个Region服务器管理多个Tablet,每个Tablet对应一个Table,并负责存储属于这个Table的数据。除了管理多个Tablet之外,Region服务器还自带WAL日志,全称为“Write-Ahead Log”,主要用于暂存那些***的数据更新请求,以避免当Tablet中的Memstore被意外关闭时所造成的数据丢失,而当Memstore完成对数据的写入之后,WAL也会清空那些对应的数据。用于存储数据的Tablet主要有两大部分组成:其一是Memstore:其是缓存在内存中的数据文件,主要存储***添加的数据,当Memstore存储的数据接近限定值时,在Memstore上缓存的数据都将会被冲刷(Flush)到YFile中;其二是YFile,它是主要用于存储数据的持久化文件,它是基于上面提到的SSTable格式,YFile只会在当Memstore被触发冲刷时创建,平时常被顺序读,这样能有效地利用硬盘顺序读性能好的特性,文件的位置在其所属Tablet的目录中。
现在Client端主要以名为“YunCli”的命令行为主,主要用于让用户输入与数据处理相关的命令,并与后端的Master节点和Region节点进行交互,但随着时间的发展,在形式上,Client端有可能是类似JDBC的驱动等。
如何适应不同的云计算环境
云计算主要常见的有两类场景:需要低延迟和高并发的读写能力,数据量虽大,但称不上海量,估计最多在TB级别,大部分现在使用RDBMS的Web应用基本上都属于这一类,有点类似传统的OLTP(联机事务处理);海量数据的存储和操作,比如PB级别的,这方面的例子有传统的数据仓库、Google海量的Web页面和图片存储等,有点类似传统的OLAP(联机分析处理)。
那么YunTable是如何适应这两种环境?首先,坚持Key-Value、Single-Master和SSTable这样经典和通用的设计。其次,在数据存储方面,加入Hotness这个机制,主要是通过设置Hotness值来决定之前为了完成查询而读取到内存中的Data Block的生存时间,假设如果是低延迟的情况,那么将Hotness值设置长一点,如果是海量数据,则相反。
***,YunTable作为新一代的PaaS平台YunEngine的后端数据库已经投入实际运行中,而且即将发布其0.9版,在这个版本中,YunTable的单点性能和稳定性将会走上一个新的台阶。还有,下一篇将继续给大家关注NoSQL。
作者简介
吴朱华,之前在IBM中国研究院参与过多个云计算产品的开发工作,现在专注于YunTable(http://code.google.com/p/yuntable/)和YunEngine(http://yunengine.com/)的研发,并即将发表《剖析云计算》一书,敬请期待。
【编辑推荐】
- 云计算背后的秘密(3)-BigTable
- 云计算背后的秘密(2)-GFS
- 云计算背后的秘密(1)-MapReduce
- 云计算背后的秘密(4)-Chubby
- 云计算背后的秘密(6)-NoSQL数据库综述












