












有大量的日志文章论述了jQuery选择器及它们的性能影响。正如你所知,可以通过ID, TagName或ClassName选择元素。依赖于不同的选择器,jQuery会使用浏览器本地方法,如通过ID或标签来选择元素,或者在使用类名选择时须手工从DOM中遍历获得元素(因为在IE中不存在相应的 getElementsByClssName)。
分析我的页面时间中这2秒
在onLoad处理器中对页面中某些特定的元素使用jQuery设置为隐藏,显示或改变样式表。这里是一个代码片断:

onLoad中的jQuery脚本样例
onLoad中的jQuery脚本样例
在onLoad事件处理器中充满着这样的调用。通过使用免费的dynaTrace AJAX Edition, 你会看到被解析为选择器的$调用,并跟随着那些方法调用,选择器至少都能获取到一个对象。下面通过PurePath对onLoad事件处理器的观察,不仅给我们展示了每次选择器调用所耗费的时间,还包括在不只一个对象时实际找到的对象数(下面还没有哪个方法调用是连一个对象都找不到的)。
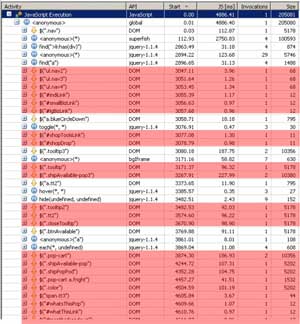
非必要的jQuery选择器调用导致无谓的开销
所有红色标记的调用都未返回一个元素,因为不存在直接基于查询条件的DOM元素。JavaScript列显示了每一次单独方法调用的执行时间–范围在 1ms 到大于 100 ms。Size列告诉了我们每次单独的调用产生了多少次的JavaScript/DOM的方法调用(译者注:指浏览器本地的调用)。这里我们也能明白,为什么某些 $ 调用花费了那么长时间,是因为它们实际进行了许多的调用来完成请求。Invocation 列告诉了我们该方法被它的父级所调用的频度。这里我们可看出一些对象实际被解析了多次,比如: “.pop-cart”。***的做法应该是只解析一次得到对象并缓存起来。
这里我们学到的***课是上面多数调用是非必要的,只会产生过量的消耗。如果你明确知道你需要解析出哪些页面元素,那就不要试图去解析其他的对象。我知道,用全局的脚本文件来处理不同页面中的不同内容会导致出现这样的情况–但是–你是否真愿意在这种无谓的开销中生活呢?
分析jQuery选择器的差异
在分析页面上的***个问题是致使了太多的非必要$调用。继而带来的另一个疑问就是为何某些$方法响应很快(几微秒),而有些却用了相当长的时间(超过100ms)。回到我的页面中来,它向我提示了如下的结论:
ID选择器,也就是使用了getElementById,是最快的
下图展示了一个使用ID的选择器。它使用了getElementById,因此很快就返回了。
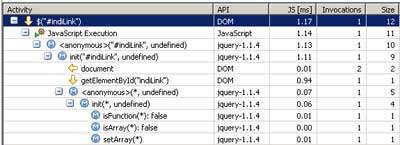
jQuery ID选择器
TagName选择器使用的是getElementsByTagName
下面的例子是通过TagName搭配ClassName 来选择元素。jQuery首先使用本地实现getElementsByTagName来获得所有指定标签的元素。接着遍历它们针对ClssName进行过滤。
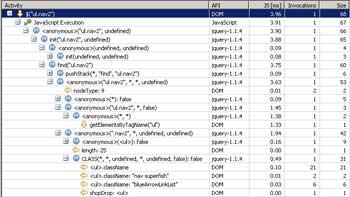
ClassName选择器需要遍历所有的DOM元素
如果你只用ClassName选择器 - jQuery需要遍历DOM中的每一个元素,因为在Internet Explorer(对于FireFox是另一番情景)中没有对应于 getElementsByClassName的本地实现。下图显示了在一直有着3460个DOM元素的页面中选择器使用开销的情况。
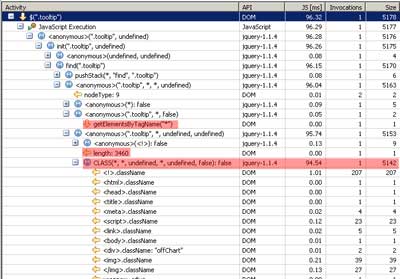
jQuery ClassName选择器
小结
依赖于你的Web站点的大小(指DOM元素的数量), 你需要考虑每个单独的选择器方法的开销。相比于通过ClassName来选择,你应该优先考虑用TagName 搭配ClassName来选择,或是在你的页面只有少量对象时用唯一性的ID来选择。而且- 确保缓存了已解析获得的对象,以避免再次解析调用时的开始。还有 – ***也是应该予以重视的一点 – 避免不必要的调用。如前面页面我所分析的 – 2 秒中有超过1.5秒是可以规避那些调用来省去的。
译文链接:http://www.blogjava.net/Unmi/archive/2009/11/24/303477.html
原文链接:http://blog.dynatrace.com/2009/11/09/101-on-jquery-selector-performance/
【编辑推荐】















