CPU 的占用主要取决于什么样的资源正在 CPU 上面运行,比如拷贝一个文件通常占用较少 CPU,因为大部分工作是由 DMA(Direct Memory Access)完成,只是在完成拷贝以后给一个中断让 CPU 知道拷贝已经完成;科学计算通常占用较多的 CPU,大部分计算工作都需要在 CPU 上完成,内存、硬盘等子系统只做暂时的数据存储工作。要想监测和理解 CPU 的性能需要知道一些的操作系统的基本知识,比如:中断、进程调度、进程上下文切换、可运行队列等。这里 VPSee 用个例子来简单介绍一下这些概念和他们的关系,CPU 很无辜,是个任劳任怨的打工仔,每时每刻都有工作在做(进程、线程)并且自己有一张工作清单(可运行队列),由老板(进程调度)来决定他该干什么,他需要和老板沟通以便得到老板的想法并及时调整自己的工作(上下文切换),部分工作做完以后还需要及时向老板汇报(中断),所以打工仔(CPU)除了做自己该做的工作以外,还有大量时间和精力花在沟通和汇报上。
CPU 也是一种硬件资源,和任何其他硬件设备一样也需要驱动和管理程序才能使用,我们可以把内核的进程调度看作是 CPU 的管理程序,用来管理和分配 CPU 资源,合理安排进程抢占 CPU,并决定哪个进程该使用 CPU、哪个进程该等待。操作系统内核里的进程调度主要用来调度两类资源:进程(或线程)和中断,进程调度给不同的资源分配了不同的优先级,优先级最高的是硬件中断,其次是内核(系统)进程,最后是用户进程。每个 CPU 都维护着一个可运行队列,用来存放那些可运行的线程。线程要么在睡眠状态(blocked 正在等待 IO)要么在可运行状态,如果 CPU 当前负载太高而新的请求不断,就会出现进程调度暂时应付不过来的情况,这个时候就不得不把线程暂时放到可运行队列里。VPSee 在这里要讨论的是性能监测,上面谈了一堆都没提到性能,那么这些概念和性能监测有什么关系呢?关系重大。如果你是老板,你如何检查打工仔的效率(性能)呢?我们一般会通过以下这些信息来判断打工仔是否偷懒:
- 打工仔接受和完成多少任务并向老板汇报了(中断);
- 打工仔和老板沟通、协商每项工作的工作进度(上下文切换);
- 打工仔的工作列表是不是都有排满(可运行队列);
- 打工仔工作效率如何,是不是在偷懒(CPU 利用率)。
现在把打工仔换成 CPU,我们可以通过查看这些重要参数:中断、上下文切换、可运行队列、CPU 利用率来监测 CPU 的性能。
底线
上一篇 Linux 性能监测:介绍 提到了性能监测前需要知道底线,那么监测 CPU 性能的底线是什么呢?通常我们期望我们的系统能到达以下目标:
- CPU 利用率,如果 CPU 有 100% 利用率,那么应该到达这样一个平衡:65%-70% User Time,30%-35% System Time,0%-5% Idle Time;
- 上下文切换,上下文切换应该和 CPU 利用率联系起来看,如果能保持上面的 CPU 利用率平衡,大量的上下文切换是可以接受的;
- 可运行队列,每个可运行队列不应该有超过1-3个线程(每处理器),比如:双处理器系统的可运行队列里不应该超过6个线程。
vmstat
vmstat 是个查看系统整体性能的小工具,小巧、即使在很 heavy 的情况下也运行良好,并且可以用时间间隔采集得到连续的性能数据。
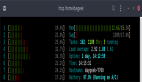
$ vmstat 1 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 2 1 140 2787980 336304 3531996 0 0 0 128 1166 5033 3 3 70 25 0 0 1 140 2788296 336304 3531996 0 0 0 0 1194 5605 3 3 69 25 0 0 1 140 2788436 336304 3531996 0 0 0 0 1249 8036 5 4 67 25 0 0 1 140 2782688 336304 3531996 0 0 0 0 1333 7792 6 6 64 25 0 3 1 140 2779292 336304 3531992 0 0 0 28 1323 7087 4 5 67 25 0
参数介绍:
- r,可运行队列的线程数,这些线程都是可运行状态,只不过 CPU 暂时不可用;
- b,被 blocked 的进程数,正在等待 IO 请求;
- in,被处理过的中断数
- cs,系统上正在做上下文切换的数目
- us,用户占用 CPU 的百分比
- sys,内核和中断占用 CPU 的百分比
- wa,所有可运行的线程被 blocked 以后都在等待 IO,这时候 CPU 空闲的百分比
- id,CPU 完全空闲的百分比
举两个现实中的例子来实际分析一下:
$ vmstat 1 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 4 0 140 2915476 341288 3951700 0 0 0 0 1057 523 19 81 0 0 0 4 0 140 2915724 341296 3951700 0 0 0 0 1048 546 19 81 0 0 0 4 0 140 2915848 341296 3951700 0 0 0 0 1044 514 18 82 0 0 0 4 0 140 2915848 341296 3951700 0 0 0 24 1044 564 20 80 0 0 0 4 0 140 2915848 341296 3951700 0 0 0 0 1060 546 18 82 0 0 0
从上面的数据可以看出几点:
- interrupts(in)非常高,context switch(cs)比较低,说明这个 CPU 一直在不停的请求资源;
- user time(us)一直保持在 80% 以上,而且上下文切换较低(cs),说明某个进程可能一直霸占着 CPU;
- run queue(r)刚好在4个。
$ vmstat 1 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 14 0 140 2904316 341912 3952308 0 0 0 460 1106 9593 36 64 1 0 0 17 0 140 2903492 341912 3951780 0 0 0 0 1037 9614 35 65 1 0 0 20 0 140 2902016 341912 3952000 0 0 0 0 1046 9739 35 64 1 0 0 17 0 140 2903904 341912 3951888 0 0 0 76 1044 9879 37 63 0 0 0 16 0 140 2904580 341912 3952108 0 0 0 0 1055 9808 34 65 1 0 0
从上面的数据可以看出几点:
- context switch(cs)比 interrupts(in)要高得多,说明内核不得不来回切换进程;
- 进一步观察发现 system time(sy)很高而 user time(us)很低,而且加上高频度的上下文切换(cs),说明正在运行的应用程序调用了大量的系统调用(system call);
- run queue(r)在14个线程以上,按照这个测试机器的硬件配置(四核),应该保持在12个以内。
mpstat
mpstat 和 vmstat 类似,不同的是 mpstat 可以输出多个处理器的数据,下面的输出显示 CPU1 和 CPU2 基本上没有派上用场,系统有足够的能力处理更多的任务。
$ mpstat -P ALL 1 Linux 2.6.18-164.el5 (vpsee) 11/13/2009 02:24:33 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s 02:24:34 PM all 5.26 0.00 4.01 25.06 0.00 0.00 0.00 65.66 1446.00 02:24:34 PM 0 7.00 0.00 8.00 0.00 0.00 0.00 0.00 85.00 1001.00 02:24:34 PM 1 13.00 0.00 8.00 0.00 0.00 0.00 0.00 79.00 444.00 02:24:34 PM 2 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00 0.00 02:24:34 PM 3 0.99 0.00 0.99 0.00 0.00 0.00 0.00 98.02 0.00
ps
如何查看某个程序、进程占用了多少 CPU 资源呢?下面是 Firefox 在 VPSee 的一台 Sunray 服务器上的运行情况,当前只有2个用户在使用 Firefox:
$ while :; do ps -eo pid,ni,pri,pcpu,psr,comm | grep 'firefox'; sleep 1; done PID NI PRI %CPU PSR COMMAND 7252 0 24 3.2 3 firefox 9846 0 24 8.8 0 firefox 7252 0 24 3.2 2 firefox 9846 0 24 8.8 0 firefox 7252 0 24 3.2 2 firefox
原文:http://www.vpsee.com/2009/11/linux-system-performance-monitoring-cpu/
系列导航:
- Linux性能监测:监测目的与工具介绍
- Linux性能监测:CPU篇
- Linux性能监测:内存篇
- Linux性能监测:磁盘IO篇
- Linux性能监测:网络篇