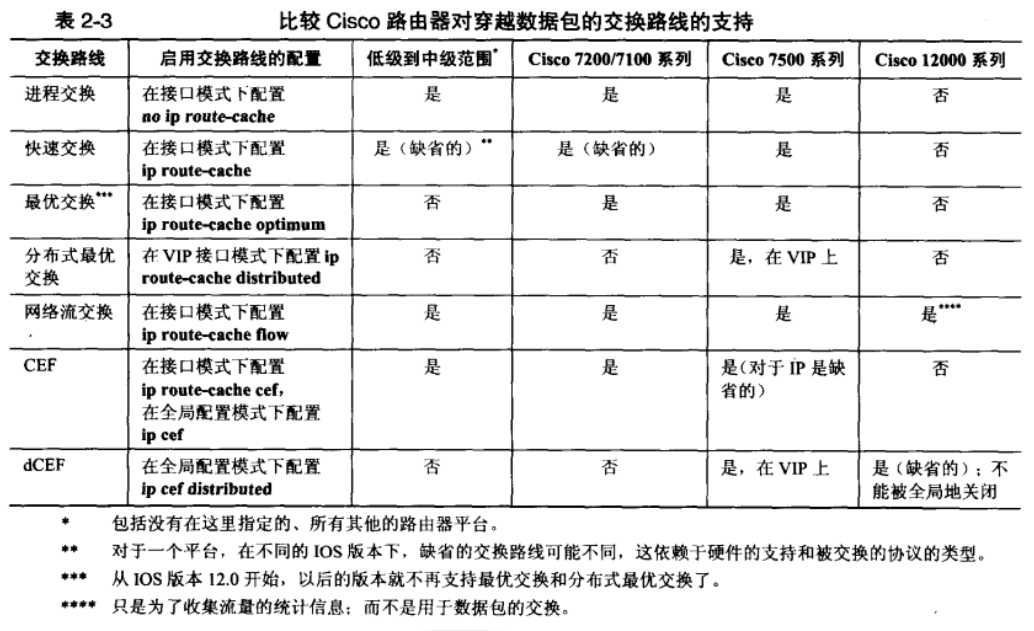
一、进程交换技术(process switching):每一个数据包过来都要查找一次路由表,数据包进入顺序就是数据包出来顺序,按照进程的先后进行。降低系统性能,大量占用系统资源,并且不可以中断IOS进程,需要排队。
二、基于缓存的交换(cache-based switching):一种更有效率的交换机制,它利用了从***个被交换的数据包所获得的信息优势,***个数据包进行进程交换。基于缓存的交换,当前运行于处理器上的IOS进程可以被中断,来进行数据包的交换。
处理器在进程级别上交换***个数据包,并在路由缓存中创建一个表项,以便后续、具有相同目的地址的数据包能够基于缓存表项被交换。
几种基于缓存交换的交换方式:
1、快速交换(fast switching):使用二叉树来存储转发信息和MAC头改写字符串,以便快速查找和参考。
2、***交换(optimum switching):在256-way(8-8-8-8,使用4个八位组的IPv4地址映射到4个8bit的结构中)。的基数树中存储转发信息和MAC头改写信息。只有基于路由交换处理器(RSP)的平台才支持***交换。
3、分布式***交换:将路由选择决策转移到接口处理器上,来减少主CPU进行包交换功能的负担。在路由选择平台的每个接口上都有一个专门的CPU即可。
注:***交换和分布式***交换从cisco IOS 12.0开始就不再被支持了。
4、网络流交换(netflow switching),通过一种标准的交换机制,处理了流的***个数据包,然后就创建了网路流缓存。
设计网络流交换的目的是,提供一种高效率的机制,来处理扩展或复杂的访问列表时,不必像其他的交换方式一样丧失同样多的系统性能。在网络流交换方式下,能够为每一个流收集详细的记账信息,对于新发布的IOS软件来说,网络流交换被专门用来实现该目的,而不再用来交换数据包了。
在同时启用CEF和网络流交换的情况下,CEF为IP数据包提供交换路线,并生成流缓存,而网络流交换被用来向流收集器输出统计信息。这些流信息包括基于每个用户、每种协议、每个端口以及每种类型的服务统计信息。这些信息被广泛用于各种目的,例如:网络分析和规划、记账以及计费。
基于缓存交换的缺点:
1、是流量驱动的,依赖于***个数据包的接收以生成缓存,这个数据包是在慢速交换路线中被交换的,导致了低性能和高CPU消耗。
2、缓存是基于IP地址的,条目众多,消耗大量内存。
3、由于路由抖动导致了无效缓存,促使网络不稳定。
三、CEF(cisco express forwarding,cisco快速交换)
进程交换和基于缓存的交换都是数据驱动(data-driven),CEF是拓扑驱动(topology-driven),并与路由选择表紧密相关。
优点:
1、可扩展性(Scalability):当激活了分布式CEF(Distributed CEF)模式时,CEF在每一块线卡(line card)上也提供了全部的交换能力。
2、增强了性能:CEF使用CPU率较低,更多的CPU处理能力可以专注于第3层的服务,比如动态路由协议的运行。
3、弹性(Resilience):在大型动态网络中,CEF提供了更好的一致性和稳定性。
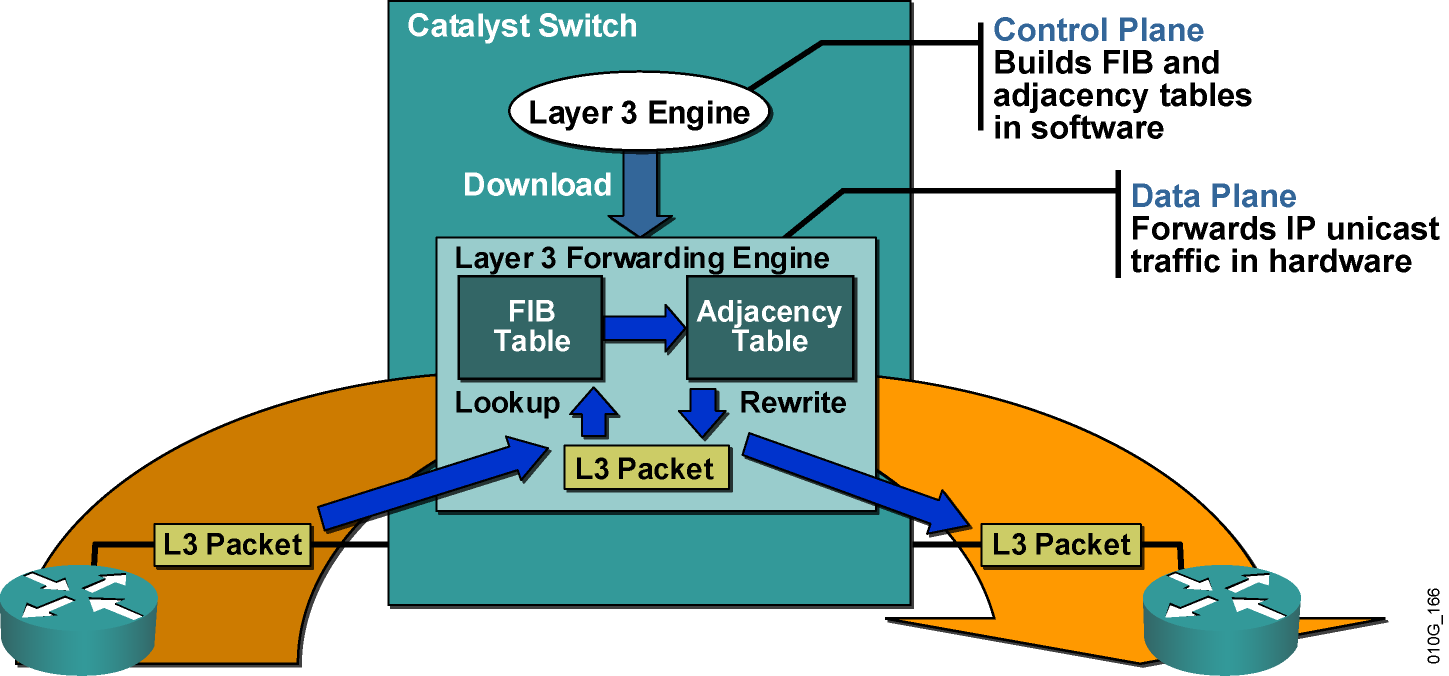
CEF 是由新的cisco设备使用的提供线速路由选择的技术。CEF让分组交换完全绕过路由处理器,通过专门的数据结构来完成,该数据结构通过路由处理器和交换处理器之间的一个通信过程来动态更新。通常,CEF被认为是“没有路由,一直交换”
基于CEF的机制针对所有的分组,包括给定流中的***个分组都用硬件处理的。路由选择表仍然由路由器的CPU维护,但是创建了两张额外的表:
1、转发信息库(FIB,Forwarding Information Base)表:该表是从路由选择表中拷贝过来的转发信息,不包括任何路由选择协议信息。路由表有任何增删变化,FIB表均会随之变化
2、邻接表:维护一个邻近结点(如果两个节点能通过第2层一跳到达彼此则被认为是邻接)以及他们相关的第2层MAC重写或下一条信息的数据库。
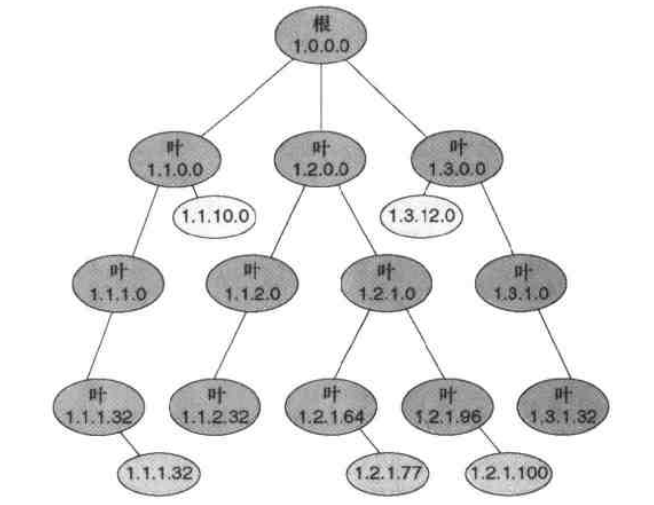
FIB表由一棵四层的树组成,是按照IPv4所使用的点分十进制来分层的,CEF依赖最长匹配转发算法,这意味着按照降序搜索整棵树知道“最长匹配”。
 #p#
#p#
cisco路由器通常才使用两种类型的mtrie结构:
1、8-8-8-8:这种格式也被称为256-way mtrie,因为4个八位组的IPv4地址被映射到4个8bit的结构中,例如上图。这种格式用在大多数cisco路由器中。
2、16-8-8:这是一个3级的mtrie,它的根级有65536个表项。因此,一条前最的***查找次数是3次,换句话说,***次查找解析了前面的两个八位组,接着最多在需要两次查找就可以确定。这种格式只用于cisco 12000系列路由器。
FIB和邻接表都被优化提供进行转发决定所需的信息,而没有更多的其他信息,如果FIB表已满,后续表项将和现有表项比较,并以牺牲不详细表项的代价来保存更详细的表项。
FIB表的好处:
1、可以被硬件ASIC调用
2、解决递归路由问题,直接找到下一跳
3、扩展性,应用于MPLS
FIB内容可通过show ip cef 命令来查看:
列举出一下几种FIB表项:
1、附接的(attached):这种前缀被配置为可以通过借口直接到达,不需要由IP下一跳来创建林接管,这种前缀是指路由器本地接口所属的网络。
2、连接的(connected):由IP address address mask 配置命令来配置的
3、收到(receive):这种前缀是一个32位掩码的主机地址。每个接口通常有3种这样的地址:实际的接口地址、主机位全0的网络地址和全1的广播地址
4、递归的(recursive):当前缀的输出接口不能通过路由选择协议或静态配置指定时,它就被标记为递归的。
邻接表是由ARP实现的,将第2层地址映射到相应的第3层地址上。路由器能从路由选择更新中发现下一跳路由器,并相应的在临街表中增加表项。这个处理让路由器构建了第3层分组转发所需的下一跳重写信息。
仅有路由器上的CEF转发机制才可以关闭基于CEF的转发。CEF默认启用,在路由器初始化时,会根据路由器中的路由选择协议构建一张路由选择表,构建完成后,CPU自动创建 FIB表和邻接表。与基于流的流缓存转发不同,CEF表是基于网络拓扑。当一个分组进入交换机时,交换机的第3层转发引擎ASIC根据目的网络和最详细的网络掩码进行最长匹配查找。
MSFC:多层交换功能卡
基于CEF的Catalyst交换机,支持下面两种3层硬件交换方法:
1、集中式交换:在一个专用的ASIC上作出转发决策,该ASIC是第3层交换机中所有接口的枢纽。所有需要路由或交换的数据包都必须经过总线或交换矩阵进入中央引擎。使用该交换方式,硬件交换性能取决于中央交换引擎和交换机矩阵/总线体系结构。用于catalyst 6500和catalyst4000系列
2、分布式交换:第3层交换机的接口或线路模块独立地做出转发决策。采用分布式交换的交换机将CEF FIB和邻接表的副本放在线路模块或接口中,供其路由选择和转发数据帧。系统性能为所有转发引擎之和。用于catalyst 3550 和catalyst带DFC(分布转发卡)的6500
基于CEF的多层交换:
 #p#
#p#
CEF的两种负载均衡方式:
1、基于每个会话的负载均衡(per-session load sharing)
基于每个会话的负载均衡允许路由器使用多条路径分发流量。对于一个给定的源—目的主机对,即使有多条路径可用,路由器也会保证该会话的数据包走相同的路径。不同的会话采用不同的路径,使用负载均衡,基于每个会话的负载均衡再激活CEF的时候缺省的也被激活。由于基于每个会话的负载均衡依赖于流量的统计分发,因而在会话数增加的情况下更有效率。
基于每个会话的负载均衡能够确保导向给定的源—目的对的数据包按序到达,因为导向相同主机对的所有数据包都被路由到相同的链路上。
2、 基于每个数据包的负载均衡
基于每个数据包的负载均衡使得路由器可以把连续的数据包发送到不同的路径上,而不必关心个别的主机或用户会话,使用轮转的方法来确定每一个数据包选择哪条路径到达目的地。
当大量数据通过单个会话的多条并行链路时,基于每个数据包的负载均衡显得更加有效。在这种情况下,基于每个会话的负载均衡将会过载其中一条链路,而其他链路几乎没有什么流量。
但基于每个数据包的负载均衡会导致针对某一个会话来说,数据包可能走不同的路径,这会引起数据包的重新排序,对于某些数据流量类型来说是不合适的,必须对于IP语音流量来说。
当启用基于数据包的负载均衡功能时,必须先禁用基于目的地的负载均衡功能。为了禁用基于目的地的负载均衡功能,可以在接口配置模式下,
- no ip load-sharing per-destination
使用基于数据包的负载均衡,路由器可以在路径上连续发送数据包,而不用考虑具体的主机或用户情况。这种负载均衡机制采用轮转办法来确定每个数据包采用哪条路径到达目的地。基于数据包的负载均衡可以保证在多条链路上进行负载均衡。要启用基于数据包的负载均衡功能,可以在接口配置模式下
- ip load-sharing per-packet
#p#为CEF配置网络记账功能
启用收集被快速转发到某个目的地的数据包个数和字节数
- ip cef accounting per-prefix
启用收集通过某个目的地被快速转发的数据包的个数
- ip cef accounting non-recursive
在全局配置模式中为CEF启用网络记账功能后,相应的路由处理器会收集记账信息。当用户为dCEF启用网络记账功能后,线路卡上会收集记帐信息。
查看网络记帐信息
- show ip cef
为CEF配置跨隧道的交换
CEF支持跨隧道的交换,例如GRE隧道。当你启用CEF或者dCEF模式时,跨隧道的交换会被自动启用,所以您无需再执行任何附加操作来启用跨隧道的交换。有时候,在某个接口配置了一项功能,而CEF或dCEF并不支持该功能,这时您就可能需要在这个特定的接口上禁止CEF或dCEF。例如,策略路由和CEF就不能一起使用。您可能想让一个接口支持策略路由,而让其他的接口支持 CEF。在这种情况下,可以按全局模式启用CEF,而在那个打算配置策略路由的接口上禁用CEF。这样,除了那一个接口外,在其他所有接口上都启用了快速转发。在某个接口上禁用CEF 或dCEF,可以在接口配置模式
- no ip route-cache cef
尔后又想重新启用CEF,在接口配置模式下,可以使用:
- ip route-cache cef
在Cisco12000 系列路由器上,您不可以在某个接口上禁用dCEF模式。
本文出自 “孤剑” 博客,请务必保留此出处http://gujian139.blog.51cto.com/1166106/399320