












编者按:本文详细介绍了RHEL 5.5+DRBD+heartbeat+Oracle10R2双机安装实例。DRBD+Heartbeat是目前运维实现双机安装的主要方式,由于配置繁琐,而针对不同服务的配置也有所不同。本文专门针对CentOS 5.5上的Oracle 10 R2的双机安装。
1、操作系统版本:Red Hat Enterprise Linux Server release 5.5 (Tikanga)
2、Drbd、Heartbeat 文件版本及文件名列表(本人已经将以下文件打包为Heartbeat3.0.3.tar.bz2 ):
Cluster-Resource-Agents-agents-1.0.3.tar.bz2
drbd-8.3.8.1.tar.gz
Heartbeat-3-0-STABLE-3.0.3.tar.bz2
Load drbd modules
Pacemaker-1-0-Pacemaker-1.0.9.tar.bz2 Pacemaker-Python-GUI-pacemaker-mgmt-2.0.0.tar.bz2
Reusable-Cluster-Components-glue-1.0.6.tar.bz2
3、网络配置(双网卡采用BOND模式)
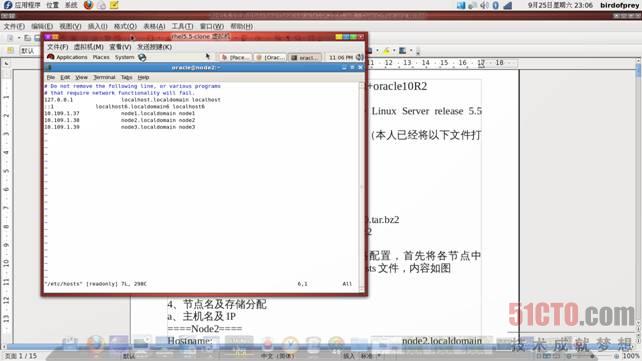
RHEL5.5系统安装完成之后需要修改网络配置,首先将各节点中eth0、eth1分别设置为静态IP。修改节点hosts文件,内容如图
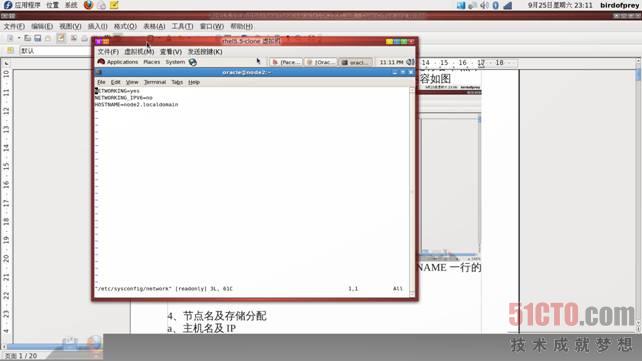
同时修改各节点/etc/sysconfig/network文件,将HOSTNAME一行的内容改为节点对应的主机名,如图(以node2为例)
4、节点名及存储分配
a、主机名及IP
====Node2==== Hostname: node2.localdomain Ip:10.109.1.38 ====Node3==== Hostname: node3.localdomain Ip: 10.109.1.39
b、DRBD镜像分区:
资源名称:oradata设备:/dev/drbd0
挂载点:/oradata (存放Oracle实例)
c、浮动主机名及IP
====Node1==== Hostname: node1.localdomain Ip: 10.109.1.37
#p#
5、安装Heartbeat
进入Linux根目录
cd /
建立HA目录
mkdir Ha
上传 Heartbeat3.0.3.tar.bz2文件到HA目录
进入HA目录
cd /HA/
5.1 解压Heartbeat压缩包,得到后续安装需要的各个安装文件
tar -jxvf Heartbeat3.0.3.tar.bz2
编译的顺序是:先Cluster Glue,再Resource Agents,然后才是Heartbeat。
解压Reusable-Cluster-Components
tar -jxvf Reusable-Cluster-Components-glue-1.0.6.tar.bz2
进入Reusable-Cluster-Components-glue-1.0.6目录
cd Reusable-Cluster-Components-glue-1.0.6
打开lib/stonith/main.c文件
vi lib/stonith/main.c
编辑:
- 找到其64行,将其注释掉。
- 找到其76到81行全部注释掉。
- 找到其390行,将其注释
使用以下两个进行配置
./autogen.sh ./configure LIBS='/lib/libuuid.so.1'
使用如下命令创建Heartbeat管理用户:
groupadd haclient useradd -g haclient hacluster
使用如下命令编译并安装:
make make install
5.2 解压Cluster-Resource-Agents
tar -jxvf Cluster-Resource-Agents-agents-1.0.3.tar.bz2
进入Cluster-Resource-Agents-agents-1.0.3目录
cd Cluster-Resource-Agents-agents-1.0.3
使用如下命令配置、编译并安装
./autogen.sh ./configure make make install
5.3 解压Heartbeat-3-0-STABLE
tar -jxvf Heartbeat-3-0-STABLE-3.0.3.tar.bz2
进入Heartbeat-3-0-STABLE-3.0.3目录
cd Heartbeat-3-0-STABLE-3.0.3
首先执行如下命令进行配置
./autogen.sh ./bootstrap ./ConfigureMe configure make
此时系统会报一个hbaping.lo错误,我们需要使用如下一组命令对hbaping.loT文件进行改名操作:
cd lib ls cd plugins/ ls cd HBcomm mv hbaping.loT hbaping.lo
之后再次执行以下两条命令进行安装操作,应该就不会报错了。
make make install
使用cd /usr/etc/命令进入/usr/etc/目录中
使用cp -R ha.d/ /etc/命令将/usr/etc/ha.d全部复制到/etc/目录中
使用rm -rfv ha.d删除/usr/etc/中整个ha.d目录
使用cd /etc/命令进入/etc/目录中
使用ln -s /etc/ha.d /usr/etc/ha.d命令创建/etc/ha.d到/usr/etc/ha.d的软连接文件。
5.4 解压Pacemaker-1-0
tar -jxvf Pacemaker-1-0-Pacemaker-1.0.9.tar.bz2
进入Pacemaker-1-0-Pacemaker-1.0.9目录
cd Pacemaker-1-0-Pacemaker-1.0.9
执行如下命令配置、编译并安装
./autogen.sh ./ConfigureMe configure make make install
5.5 解压Pacemaker-Python-GUI
tar -jxvf Pacemaker-Python-GUI-pacemaker-mgmt-2.0.0.tar.bz2
进入Pacemaker-Python-GUI-pacemaker-mgmt-2.0.0目录
cd Pacemaker-Python-GUI-pacemaker-mgmt-2.0.0
首先执行如下命令
./bootstrap
使用rpm命令在RHEL5.5安装光盘中安装gettext-devel、intltool包,具体命令如下:
cd /media/RHEL_5.5\ i386\ DVD/Server/ rpm -ivh gettext-devel-0.14.6-4.el5.i386.rpm rpm -ivh intltool-0.35.0-2.i386.rpm
之后再次进入Pacemaker-Python-GUI-pacemaker-mgmt-2.0.0目录
cd Pacemaker-Python-GUI-pacemaker-mgmt-2.0.0
执行如下命令:
./ConfigureMe configure autoreconf -ifs ./bootstrap make make install
使用passwd命令设置 hacluster用户口令
将hbmgmtd复制到/etc/pam.d/目录
cp /usr/etc/pam.d/hbmgmtd /etc/pam.d/
6、安装DRBD
使用tar zxvf drbd-8.3.8.1.tar.gz解压该文件
使用cd /media/RHEL_5.5\ i386\ DVD/Server/进入光盘挂载目录中
使用rpm依次安装内核相关的源码包
rpm -ivh kernel-devel-2.6.18-194.el5.i686.rpm rpm -ivh kernel-headers-2.6.18-194.el5.i386.rpm rpm -ivh kernel-doc-2.6.18-194.el5.noarch.rpm
使用cd drbd-8.3.8.1命令进入drbd-8.3.8.1目录中依次执行如下命令配置、编译并安装
./autogen.sh ./configure --prefix=/usr --localstatedir=/var --sysconfdir=/etc/ --with-km make make install
使用chkconfig --add drbd命令创建drbd服务启动脚本
使用chkconfig --add heartbeat命令创建heartbeat服务启动脚本
使用chkconfig heartbeat off命令关闭heartbeat服务
使用chkconfig drbd off命令关闭drbd服务
使用cat Load\ drbd\ modules >> /etc/rc.d/rc.sysinit命令将Load drbd modules中的内容添加到rc.sysinit系统文件的***部分,以便系统启动时能自动将drbd.ko驱动模块加载到核心中,正常使用drbd服务。(该步逐在rhel5.5中需要省略,否则drbd服务将无法正常启动)。
#p#
7、配置DRBD
7.1、修改各节点主机DEBD配置文件/etc/drbd.d/global_common.conf中usage-count 的参数为no,如图:
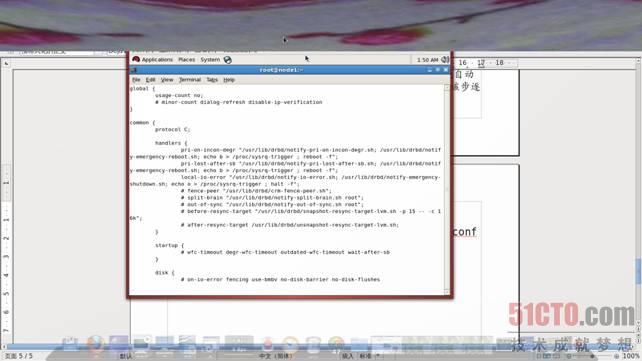
完成后存盘退出。
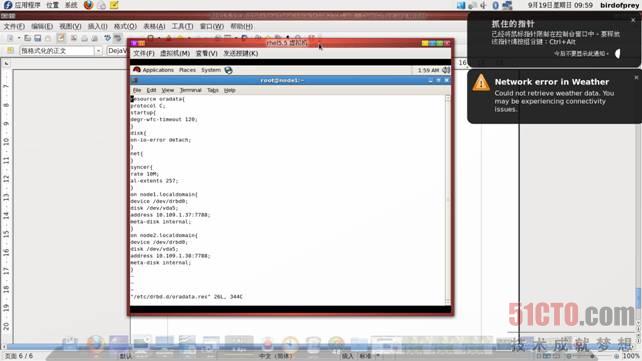
7.2、在各节点主机中创建文件/etc/drbd.d/oradata.res,并在oradata.res文件中添加如下内容:
resource oradata { # 资源组的名称
protocol C;
startup {
degr-wfc-timeout 120; # 2 minutes. 启动时连接其他节点的超时时间
}
disk {
on-io-error detach; # 当磁盘有错误时,不连接
}
net {
}
syncer {
rate 10M; # 设置主备节点同步时的网络速率***值
al-extents 257;
}
on node2.localdomain{ # 节点主机名
device /dev/drbd0; # 今后使用的设备
disk /dev/vda5; # 该节点上的用于存放数据的分区号
address 10.109.1.38:7788; # 该节点的IP地址
meta-disk internal; # meta data信息存放的方式
}
on node3.localdomain{
device /dev/drbd0;
disk /dev/vda5;
address 10.109.1.39:7788;
meta-disk internal;
}
}
如图例:
7.3、初始化分区
在各节点上执行drbdadm create-md oradata命令,初始 化分区(创建meta data信息),这里的oradata即为配置文件中的资源组名称。
7.4、启动服务在两台节点服务器上启动drbd服务。如图:
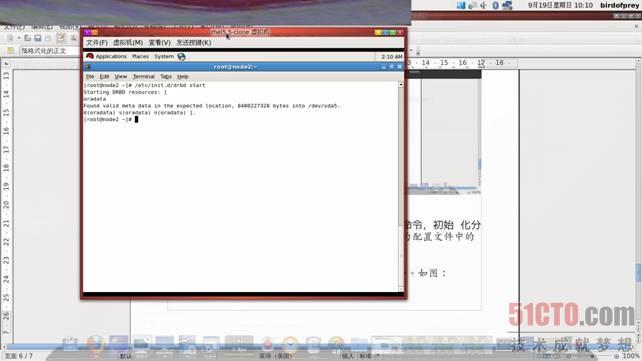
之后用cat /proc/drbd 或 service drbd status 查看当前状态,出现下图信息说明DRBD服务已经正常启动了,如图:
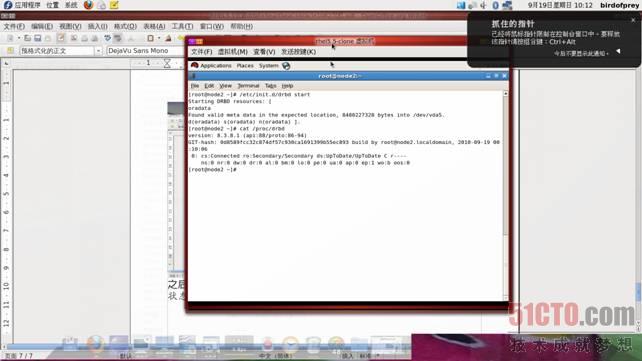
※ 注意,现在两机器都是处于Secondary,即备机状态,还进行数据同步。
7.5、设置primary主机
在确认作为主数据服务器的机器上执行:
[root@node1 ~]# drbdadm adjust oradata [root@node1 ~]# drbdsetup /dev/drbd0 primary -o
这样,将把node1作为主机,把vda5中的数据以块的方式同步到node2中。可再次查看状态:
[root@node1 ~]# cat /proc/drbd version: 8.3.8 (api:88/proto:86-94) GIT-hash: d78846e52224fd00562f7c225bcc25b2d422321d build by root@hatest1, 2010-07-07 08:59:44 0: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r---- ns:719756 nr:0 dw:0 dr:720896 al:0 bm:43 lo:0 pe:62 ua:36 ap:0 ep:1 wo:b oos:1378556 [=====>..............] sync'ed: 34.4% (1378556/2096348)K delay_probe: 149 finish: 0:04:59 speed: 4,580 (7,248) K/sec [root@node2 ~]# cat /proc/drbd version: 8.3.8 (api:88/proto:86-94) GIT-hash: d78846e52224fd00562f7c225bcc25b2d422321d build by root@hatest1, 2010-07-07 08:59:44 0: cs:SyncTarget ro:Secondary/Primary ds:Inconsistent/UpToDate C r---- ns:0 nr:752096 dw:751584 dr:0 al:0 bm:45 lo:17 pe:49 ua:16 ap:0 ep:1 wo:b oos:1344764 [======>.............] sync'ed: 36.0% (1344764/2096348)K queue_delay: 2.9 ms finish: 0:02:11 speed: 10,224 (10,020) want: 10,240 K/sec
从蓝色比较的 地方,可区分主机在DRBD集群中的位置。使用下面的命令也可确认:
[root@node1 ~]# drbdadm role oradata Primary/Secondary [root@node2 ~]# drbdadm role oradata Secondary/Primary
把 drbd服务设置为自启动方式:
[root@node1 ~]# chkconfig --level 235 drbd on [root@node2 ~]# chkconfig --level 235 drbd on
至此,镜像分区已创建完成。
最终同步完 成后,两机器drbd的状态会变为:
[root@hatest1 ~]# cat /proc/drbd version: 8.3.8 (api:88/proto:86-94) GIT-hash: d78846e52224fd00562f7c225bcc25b2d422321d build by root@hatest1, 2010-07-07 08:59:44 0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r---- ns:2096348 nr:0 dw:0 dr:2096348 al:0 bm:128 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0 [root@hatest2 ~]# cat /proc/drbd version: 8.3.8 (api:88/proto:86-94) GIT-hash: d78846e52224fd00562f7c225bcc25b2d422321d build by root@hatest1, 2010-07-07 08:59:44 0: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate C r---- ns:0 nr:2096348 dw:2096348 dr:0 al:0 bm:128 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
7.6、DRBD中的split brain的处理
split brain实际上是指在某种情况下,造成drbd的两个节点断开了连接,都已Primary状态来运行。这通常发生在主节点断开,而备节点手动修改数据 后,因meta data数据不一致的情况。当drbd某primary节点连接对方节点准 备发送信息的时候如果发现对方也是primary状态,那么会会立刻自行断开连接,并认定当前已经发生split brain了,这时候他会在系统日志中记录以下信息:“Split-Brain detected,dropping connection!”当发生split brain之后,如果查看连接状态,其中至少会有一个是StandAlone状态,另外一个可能也是StandAlone(如果是同时发现split brain状态),也有可能是WFConnection的状态。
DRBD可在配置文件中设定发生split brain时的处理机制,但这可能与实际情况不一致,不建议使用。若没有配置split brain自动解决方案,我们可以手动来处理。
首先我们必须要确定哪一边应该作为解决问题后的primary(也就是拥有***数据的一边).一旦确定好这一点,那么我们同时也就确定接受 丢失在split brain之后另外一个节点上面所做的所有数据变更了。当这些确定下来后,我们就可以通过以下操作来恢复了:
(1)首先在确定要作为 secondary的节点上面切换成secondary并放弃该资源的数据:
drbdadm disconnect resource_name drbdadm secondary resource_name drbdadm -- --discard-my-data connect resource_name
(2)在要作为primary的节点重新连 接secondary(如果这个节点当前的连接状态为WFConnection的话,可以省略)
drbdadm connect resource_name
当作完这些动作之后,从新的primary到secondary的re- synchnorisation会自动开始(重新同步)。
7.7、格式化分区
7.7.1、与软RAID、LVM等类似,要使用DRBD 创建的镜像分区,不是直接使用/dev/vda5设备,而是在配置文件中指定的/dev/drbd0。同样的,不必等待初始化完成后才使用drbd0设 备。
[root@node1 ~]# drbdadm role oradata Primary/Secondary [root@node1 ~]# mkfs.ext3 /dev/drbd0 [root@node1 ~]# tune2fs -c 0 -i 0 /dev/drbd0
7.7.2注意事项
需要注意,drbd0设备只能在Primary一端使用,下面的操作都是会报错的:
[root@node2 ~]# mount /dev/vda5 /oradata mount: /dev/vda5 already mounted or /oradata busy [root@node2 ~]# drbdadm role oradata Secondary/Primary [root@node2 ~]# mount /dev/drbd0 /oradata/ mount: block device /dev/drbd0 is write-protected, mounting read-only mount: 错误的介质类型
另外,为避免误操作,当机器重启后,默认都处于Secondary状态,如要使用 drbd设备,需手动把其设置为Primary。
7.7.3、挂载
先把drbd0设备挂载到/oradata目录中:
[root@hatest1 ~]# mount /dev/drbd0 /oradata [root@hatest1 ~]# df -h /oradata 文件系 统 容量 已用 可用 已用% 挂载点 /dev/drbd0 2.0G 36M 1.9G 2% /oradata
#p#
8、安装ORACLE10.2
8.1、分别在各节点配置Linux内核参数。
以root身份登录后,进入etc目录,打开sysctl.conf文件,然后将以下内容写入图中位置:
kernel.shmall = 2097152
kernel.shmmax = 1717986918
kernel.shmmni= 4096
kernel.sem = 250 32000 100 128
fs.file-max = 65536
net.ipv4.ip_local_port_range = 1024 65000
net.core.rmem_default = 262144
net.core.rmem_max = 262144
net.core.wmem_default = 262144
net.core.wmem_max = 262144
这些参数都可按照该列表填写,在这些参数中的shmmax(红色标注)则有自己的计算方法:内存以G为单位,将其换算成Byte单位在乘以80%,例如;2G内存,换算公式为
2*1024*1024*1024*80%=1717986918
8.2、创建oracle安装要求的用户名和用户组,并修改oracle用户环境变量(即修改oracle用户目录下的.bash_profile文件)
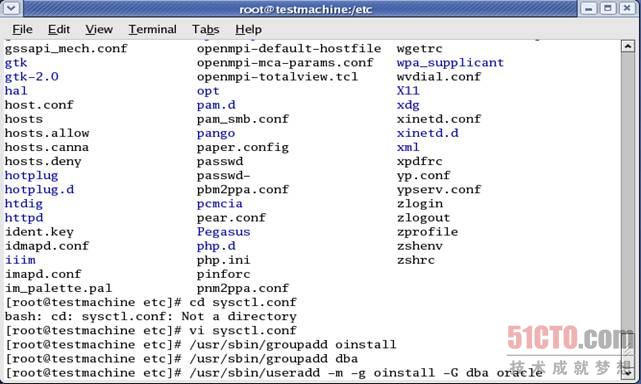
8.2.1、在两个节点中分别执行如下groupadd oinstall、groupadd dba、useradd -m -g oinstall -G dba oracle命令,创建oracle用户,如图
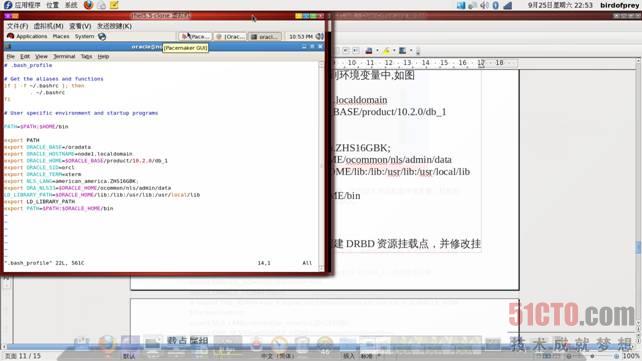
8.2.2、在各节点修改oracle环境变量, 以oracle用户身份,打开.bash_profile文件将如下内容添加到环境变量中,如图
export ORACLE_BASE=/oradata export ORACLE_HOSTNAME=node1.localdomain export ORACLE_HOME=$ORACLE_BASE/product/10.2.0/db_1 export ORACLE_SID=orcl export ORACLE_TERM=xterm export NLS_LANG=american_america.ZHS16GBK; export ORA_NLS33=$ORACLE_HOME/ocommon/nls/admin/data LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib:/usr/local/lib export LD_LIBRARY_PATH export PATH=$PATH:$ORACLE_HOME/bin
8.3、创建ORACLE安装挂载点
在各oracle 安装节点使用如下命令创建DRBD资源挂载点,并修改挂载点属组
[root@node1 ~]# cd / [root@node1 /]# mkdir oradata [root@node1 /]# chown -R oracle:oinstall oradata
8.4修改IP地址为浮动IP并设置DEBD资源为primary
在安装oracle10G2的机器上首先需要将IP地址及主机名修改为未来浮动IP及主机名(这样主要是为了未来双机应用时oracle能顺利切换,并正常启动),执行drbdadm primary oradata命令 设置DRBD资源为primary如图:
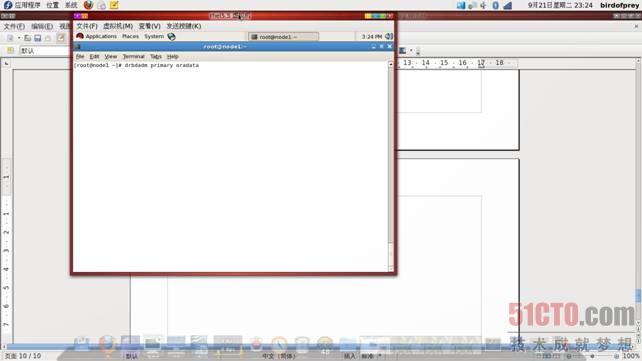
执行drbdadm role oradata查看状态,如图:
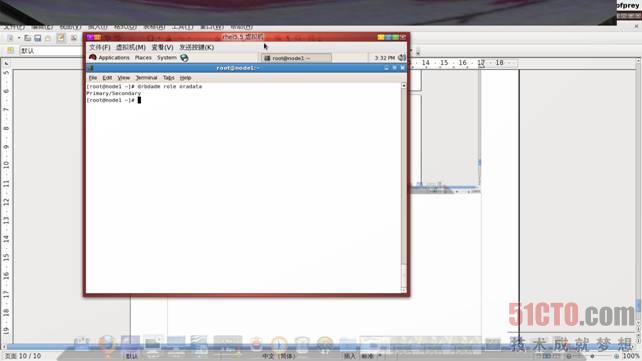
8.5、挂载DRBD资源并修改资源属组
执行mount /dev/drbd0 /oradata命令挂载DRBD资源,如图:
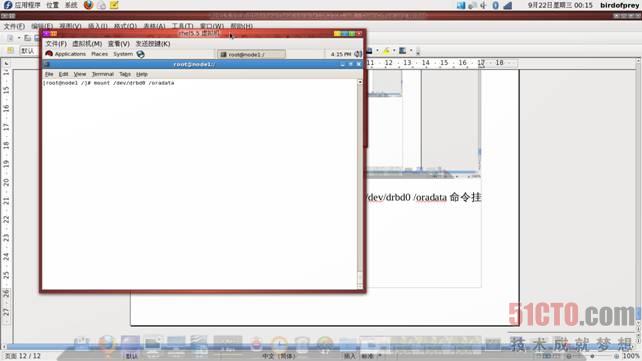
之后执行mount命令查看信息,如图
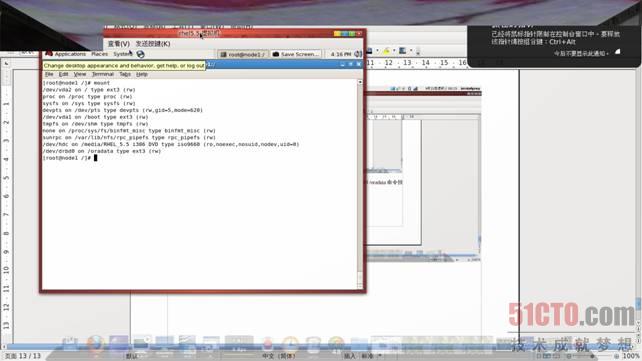
信息中出现/dev/drbd0 on /oradata type ext3 (rw)行,说明资源挂载正常,之后执行
chown -R oracle:oinstall oradata
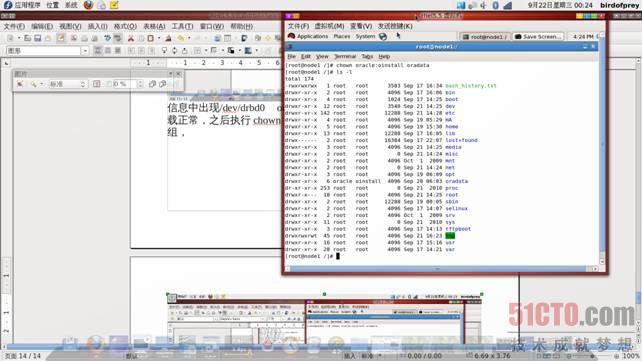
命令修改oradata属组,并使用ls -l查看信息,如图:
8.6、安装oracle10G2数据库
具体可以查看其他文档。
8.7、***配置
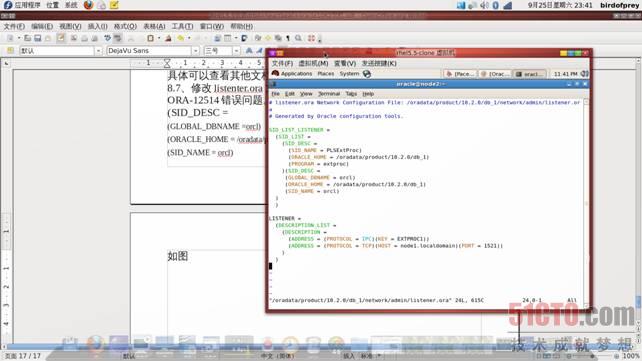
8.7.1、修改listenter.ora文件,添加如下内容,解决双机切换报监听ORA-12514错误问题。
(SID_DESC = (GLOBAL_DBNAME =orcl) (ORACLE_HOME = /oradata/product/10.2.0/db_1) (SID_NAME = orcl)
如图:
8.7.2、修改主机名为原节点主机名及IP。
8.7.3、终止在用oracle节点的各oracle进程,并卸载掉oracle资源;
在另一节点中挂载资源并启动oracle应用进程并进行测试。如果没有问题可进行HA的配置。
#p#
9、heartbeat的配置
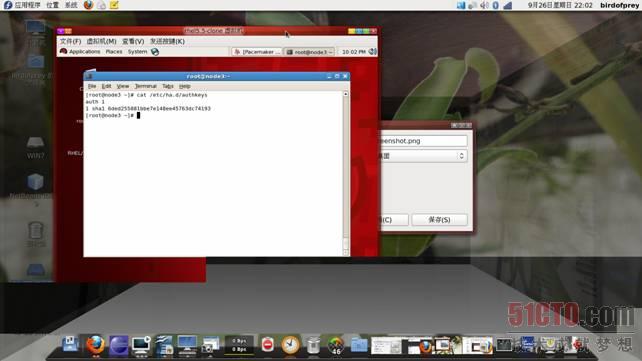
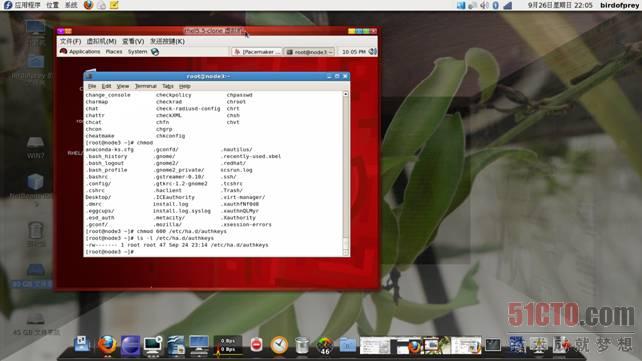
9.1、配置authkeys
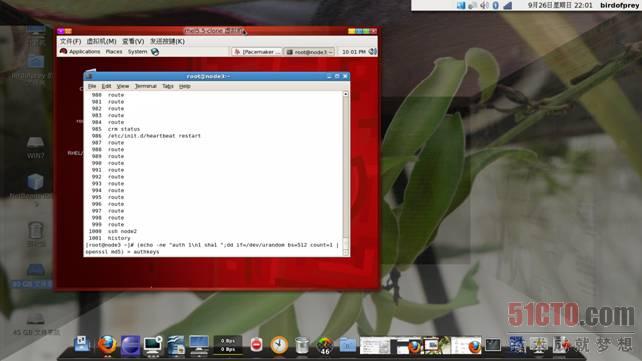
这里我用随机数来获得密钥,命令如下:
# (echo -ne "auth 1\n1 sha1 ";dd if=/dev/urandom bs=512 count=1 | openssl md5) > /etc/ha.d/authkeys # cat authkeys # chmod 600 /etc/ha.d/authkeys
效果如图:
9.2、配置ha.cf
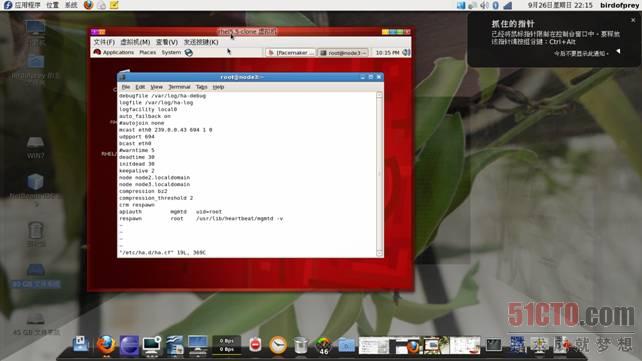
使用命令vi /etc/ha.d/ha.cf编辑配置文件,修改为如下内容:
debugfile /var/log/ha-debug logfile /var/log/ha-log logfacility local0 auto_failback none mcast eth0 239.0.0.43 694 1 0 udpport 694 bcast eth0 deadtime 30 initdead 30 keepalive 2 node node2.localdomain node node3.localdomain compression bz2 compression_threshold 2 crm respawn apiauth mgmtd uid=root respawn root /usr/lib/heartbeat/mgmtd -v
之后存盘退出。如图
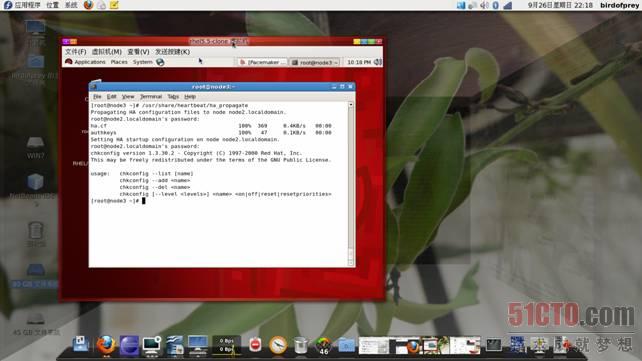
9.3、同步节点HA配置文件
执行# /usr/share/heartbeat/ha_propagate命令,并安提示输入同步节点主机root账户密码,如图
9.4、启动heartbeat
使用如下命令在两节点上启动heartbeat :
#service heartbeat start
如图:
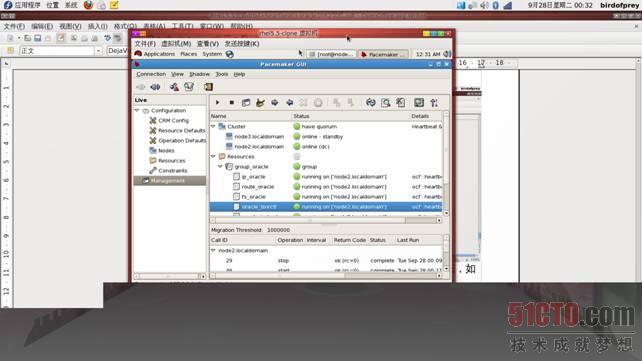
9.5、配置DRBD+Oracle的HA资源。
9.5.1、执行命令
# crm_attribute -t crm_config -n stonith-enabled -v false
或者
# crm configure property stonith-enabled="false"
关闭heartbeat的STONITH支持,避免启用了stonith而集群中又没有stonith资源时,集群中的资源都是无法启动的问题。
9.5.2、清空旧配置文件,以crm 交互方式提交如下命令:
# crm crm(live)# configure crm(live)configure# erase crm(live)configure# commit crm(live)configure# exit
清空旧配置文件。
9.5.3、关闭quorum
HA中有quorum的概念,即集群中必须有一半的节点处于online的状态,则集群被认为是have quorum(可以认为是达到合法节点数要求)。如果少于一半的节点在线,那么HA认为集群达不到节点数要求,从而拒绝启动集群中的资源。 但是这种策略对于2个节点的集群明显是不合理的,所以就会发生当2个节点的集群其中一个节点失效时所有的集群都无法启动的情况。
同样的,也关闭 STONITH,执行以下两条命令即可关闭quorun及STONITH支持
# crm configure property no-quorum-policy=ignore
# crm configure property stonith-enabled="false"
9.5.3、使用pacemaker进行HA资源配置
把DRBD设置为主备资源,其他oracle资源放在同一个组里面,并通过“顺序”、“协同”等限制条件让两资源配合运行。根据监控的情况,加入 start 超时、monitor 间隔时间等操作。
进入crm 交互模式:
# crm configure crm(live)configure#
然 后在configure状态下输入以下内容:
primitive drbd_oracle ocf:linbit:drbd \
params drbd_resource="oradata" \
op monitor interval="15s"
primitive fs_oracle ocf:heartbeat:Filesystem \
params device="/dev/drbd/by-res/oradata" directory="/oradata" fstype="ext3"
primitive ip_oracle ocf:heartbeat:IPaddr2 \
params ip="10.109.1.37" nic="bond0" cidr_netmask="24"
primitive oracle_instant ocf:heartbeat:oracle \
op monitor interval="120" timeout="30" \
op start interval="0" timeout="120" \
params sid="orcl"
primitive oracle_lsnrctl ocf:heartbeat:oralsnr \
params sid="orcl" \
operations $id="oracle_lsnrctl-operations" \
op monitor interval="10" timeout="30"
primitive route_oracle ocf:heartbeat:Route \ operations $id="route_oracle-operations" \ params destination="0.0.0.0/0" gateway="10.109.1.1" group group_oracle ip_oracle route_oracle fs_oracle oracle_lsnrctl oracle_instant \ meta target-role="Started" is-managed="true" ms ms_drbd_oracle drbd_oracle \ meta master-max="1" master-node-max="1" \ clone-max="2" clone-node-max="1" notify="true" colocation oracle_on_drbd inf: group_oracle ms_drbd_oracle:Master order oracle_after_drbd inf: ms_drbd_oracle:promote group_oracle:start
***用commit 提交即可。
※ 说明:
a、根据DRBD官网的资料,ocf:heartbeat:drbd 已经被丢弃,不建议使用,故用ocf:linbit:drbd 代替;
b、IP的设定RA,用ocf:heartbeat:IPaddr2,其用 ip 命令设定虚拟IP,虚拟IP生效后,用ifconfig命令看不到,可用ip addr 查看;
c、输入上述命令时,可能会提示警 告,start、stop的超时时间少于建议值等,这可根据应用启动、停止的实际环境在“操作”中加入(可参考oracle_instant 资源);
d、 ms 是设置“主备资源”;
e、colocation 是设置“协同”限制,即group_oracle和ms_drbd_oracle必须在同一台机器上运行,并且若ms_drbd_oracle不能作为 Master运行时,不会运行group_oracle,相反group_oracle的状态不会影响ms_drbd_oracle;
g、 order 是设置“顺序”限制,即先激活ms_drbd_oracle资源(把drbd设备设置为primary状态),然后再启动group_oracle组资 源;
f、挂载操作中,/dev/drbd/by-res/oradata是为了方便使用,由drbd创建的一个指向/dev/drbd0的链接;
h、 如果您输入的命令比较长,可以用“\”调到下一行继续,但是必须注意,下一行前面的空白只能用空格,不能用Tab等字符。
配置提交后,两资源会自动运行(根据全局配置,有延迟),也可手动使用如下命令启动资源:
# crm resource start group_oracle
9.6、HA的管理命令
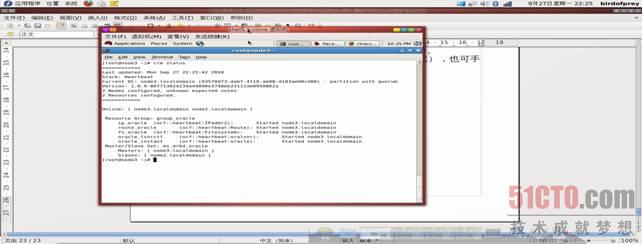
9.6.1、查看HA状态,执行如下命令:
# crm status
执行效果如图:
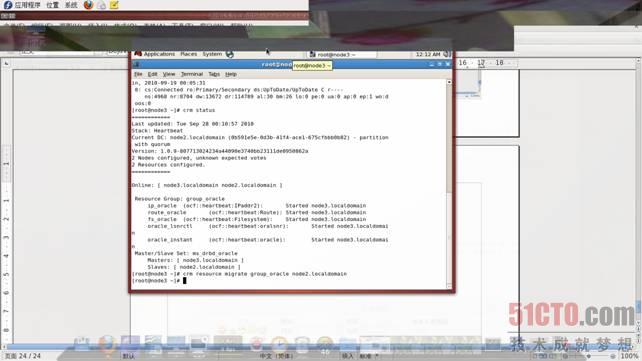
9.6.2、手动切换,执行如下命令
# crm resource migrate group_oracle node2.localdomain
如图
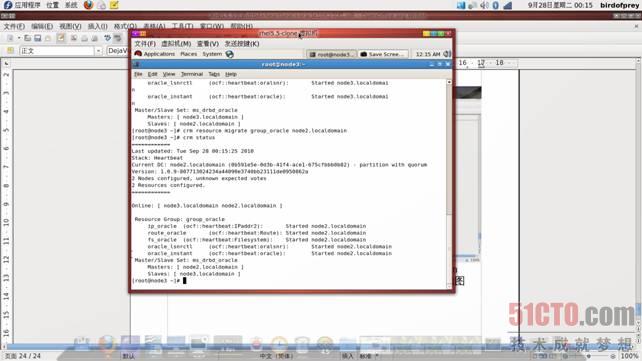
切机前资源均在node3.localdomain上,执行命令后再次执行crm status命令可以看到资源已经全部被node2.localdomain接管。如图
9.7、维护
有时候,我们需要对当前主机进行维护,这时,可先把资源迁移到备机上,然后把主机设置为“非管理”的 standby状态,如图:
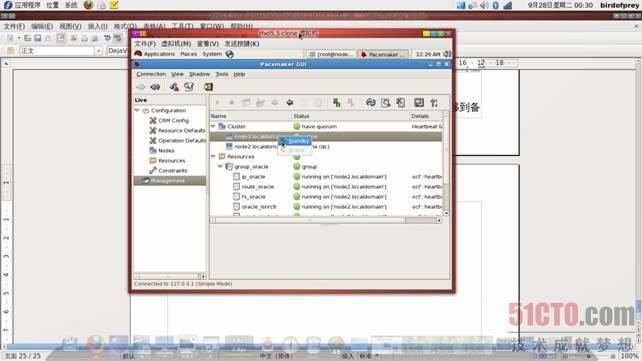
使用鼠标点击图中standby即可将选中主机设置为“非管理”状态,如图:
之后,就可以把主机上的heartbeat服务关掉,甚至关闭该机器或进行维护的工作。
来源:http://blog.chinaunix.net/u/6262/showart.php?id=2353394
感谢解宝琦的投递。
【编辑推荐】










