













【51CTO.com综合报道】构建高可用性网络是一个复杂的系统工程,如何不断向着5个9的目标迈进,是所有网络产品和解决方案提供者和使用者所面临的永恒课题。
随着网络的快速普及和应用的日益深入,各种核心及增值业务在网络广泛部署,网络与业务的结合越来越深入。因此,短时间的网络中断将可能影响核心业务处理,给企业带来巨大损失。在这种背景下,从运营商到各种类型的企业客户,在构建生产网络(production network)时,5个9的网络可用性(一年中不能提供服务的时间在5分钟左右),已经成为通常建网的追求。但在实际的网络建设中,由于影响网络系统可用性的因素众多,往往很难满足这一理论目标,其中尤其以广域网的高可用性最难控制。
度量网络的可用性
首先,高可用的网络肯定不能频繁出现故障。IP承载网即使只出现很短时间的中断,都会影响业务运营,特别是时性强、对丢包和时延敏感的业务,如语音、视频和在线游戏等。
其次,高可用性的网络即使出现故障,也应该能很快恢复。如果一个网络一年仅出一次故障,但这次故障需要几个小时,甚至几天才能恢复,那么这个网络也算不上一个高可用的网络。
故障次数少、恢复时间短两个特征基本概括了高可用网络的特点,再加入统计学的概念,就可以用“可靠性(Availability)”这一参数来度量网络的可用性:
![]()
MTBF:平均无故障时间(Mean Time Between Failures)
MTTR:平均修复时间(Mean Time To Repair)
可见,如果要提高网络可用性,提高MTBF或者降低MTTR都是有效的方法。MTBF取决于网络设备硬件和软件本身的质量,而这一手段的作用是有极限的,无法一味的通过提高MTBF数值来获得高可用性,因此通过减小MTTR来实现网络高可靠性成为必然的选择。
从MTTR的构成来看,要想减小其数值需要从两方面入手,一是以最快的速度发现故障,二是快速从故障状态中恢复出来。因此构建高可靠性网络的基础就是要实现快速故障检测和快速故障恢复。
在实际的网络运行环境下,依靠以上的理论公式很难精确计算,因此网络采用更具实际意义的工程经验公式来表示网络系统的可用性,举例来说:
某企业共n个分支节点,为5000用户提供7*24接入,分支3在3月份网络中断10分钟,分支9在同月网络中断5分钟,现计算三月份的网络可用性:

#p#
网络高可用设计框架
构建高可用性网络是一个复杂的系统工程,必须从多方面入手,不仅要提升网元本身可用性,同时要缩短故障发生后的恢复时间。系统性的来看,在网络规划和设计阶段如图1所示。

图1 高可用网络设计架构图
网络组件:网络组件是构成网络系统的基本元素,核心的网络组件完成网络的基本连接,数据包的路由转发,典型代表为各种交换机、路由器等网络设备。网络组件的可用性是决定整个网络系统可用性的关键,因此在网络设计时这部分内容往往是最优先考虑的部分。
网络架构:网络架构表明了网络组件的连接关系,不同的连接方式影响到网络系统可用性的计算方法选择。对于广域网链路,虽然单条链路会受各种自然条件的限制,但良好的拓扑设计可以最大程度的弥补这一不足。
网络协议与配置:仅仅关注物理联通的网络可用性是无意义的,一个完善的网络系统会部署大量的逻辑协议,如路由、链路检测、VPN隧道等等,这些协议的部署也影响着网络系统的可用性,尤其是对于网络业务的快速回复方面。
网络运维:由于各种因素影响,网络故障总是难免发生的,在发生事故时,高素质的运维水平,可以使影响范围和恢复时间缩小到最小范围,弥补对业务造成的影响,因此网络的运维对整体的高可用性至关重要。
网络基础支撑:网络设备的运行环境为网络系统的正常运转提供电力、空调、防雷等各种支撑,良好的基础支撑可以进一步提升整体网络的可用性。
针对广域网我们着重强调前三个方面的设计考虑,并不是说其他方面不重要,只不过这些内容不是本文的重点而已。 #p#
广域网网络组件的高可用设计
网络组件的高可用设计硬件结构的高可用和软件系统的高可用两个层面。其结构如图2所示。
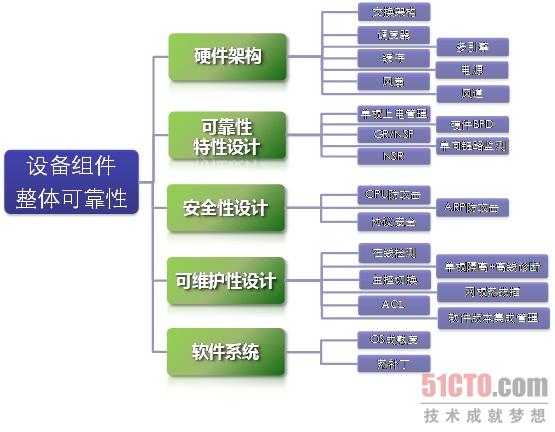
图2 网络组件高可用设计架构图
硬件高可用性主要技术点
主控冗余
主控冗余在控制和转发分离的架构下才能发挥最大的效用。在控制和转发分离的架构中,控制平面负责各种协议,如路由协议(如RIP/OSPF/IS-IS/BGP)、标签分发协议(如LDP/RSVP-TE/BGP)等的处理,形成路由信息表(RIB)和标签信息表(LIB),从中选择最优者,加上必要的二层信息,形成路由转发信息表(FIB)和标签转发信息表(LFIB),下发到转发平面,转发平面据此实现快速转发。控制平面的处理在主控板上进行,转发平面的处理在业务板上。这样,即使控制平面出现故障,转发平面的转发表项的内容在短时间内不会失效,因此可以继续转发数据而不会出现问题(如环路)。当然,控制平面必须能快速恢复并重新和邻居建立协议会话,收敛后再对转发平面进行检查,对表项作必要更新,删除在新的会话环境下不再正确的转发表项。主控冗余是指设备配置两块主控板,互为备份,一块为Master,另一块备用,称为Slave。只有Master进行控制平面的处理,并生成转发表项。Slave上的映像文件虽然也充分启动,配置也从Master实时备份,但Slave不参与控制平面的处理。Master转发平面的各种表项会以实时增量备份和定期完整备份相结合的方式持续备份到Slave上。虽然Slave上的控制平面对网络状况一无所知,但由于其在转发平面上和Master同步,基本能反映当时的网络转发状态,因此随时可以替换Master承担起转发任务,这就是转发和控制分离带来的效果。
设备实时检测Master是否正常工作,检测手段可以是检测主备板之间的硬件心跳,也可以使用IPC通道或用其他方式进行检测。一旦发现Master异常,立即启动主备切换,由Slave接管Master的工作,Master和Slave的角色互换。和单主控相比,双主控的收敛性能要好得多,因为在双主控情况下,Slave已经预先完成映象文件的加载和配置的初始化工作,主备切换时业务板不需要重新注册,二三层接口也不会出现up/down。另外,因为Slave上已经备份有转发表项,可以立即承担转发任务,在一定程度上可以避免业务中断。
不过,因为新的Master在主备切换前不参与控制平面的处理,切换后需要重新和邻居进行会话协商,所以虽然保存了完整的转发表项,但只能避免部分流量不中断,如二层以及从本设备往外发送的流量;如果和邻居之间配置的是静态路由或静态LSP的话,邻居会继续向进行主备倒换的设备发送流量,流量也不会中断。但如果和邻居之间是动态路由协议或动态标签分发协议,则和邻居之间的流量会中断,这是因为在控制平面会话重置的情况下,邻居的控制平面会重新计算,选择它认为合适的路径。以OSPF协议为例,新Master在发出的Hello报文中没有原来邻居的RID,会导致邻居把OSPF会话状态重置,并把和发生切换的设备相关的LSA删除,导致路由重新计算。如果有其他可选路径的话,流量会绕开主备切换的设备;如果没有可选路径,则需要等待OSPF重新收敛,在重新收敛之前,邻居不会把流量发给该设备。
主备切换的前提条件,是检测到Master故障。在Master故障但没有被检测到的时间内,会导致报文丢失。其次,主备切换期间也会丢一部分报文。最后,主备切换完成后,设备需要和和邻居重建协议会话,这也需要一定时间。总的来说,主备切换的收敛时间为:Master故障检测时间+切换时间+信令收敛时间。
单板热插拔
单板热插拔,是指在设备正常运行时,在线插拔单板,而不影响其他单板的业务。一般的中高端机架式设备,均支持单板热插拔。单板热插拔功能包括:
往机框中新增单板不影响在线的单板业务;
可在线更换单板(即拔出老单板换一块新单板或老板重新插入时,新单板能继承原来的配置,并且不影响其他单板的工作;
对于分布式设备,在添加或插拔单板时,FIB表能同步到单板。
单板热插拔和跨板的链路捆绑技术相结合,一定程度上提供了单板间的1:N备份功能。
单板热插拔的收敛时间不好衡量,就以配置继承和生效为例,收敛时间和配置的类型及配置的多少有极大的关系。如果和链路捆绑结合,收敛时间还和链路捆帮的收敛时间相关。
电源风扇冗余
为了保证设备电源收入的稳定,中高端设备一般提供双路电源输入,当一路输入出现故障时,能自动切换到另一路,不影响设备功能。另外,中高端设备一般通过多个电源模块供电,采取1:N备份方式,一个电源模块为其他N个提供备份,在拔出某一个电源模块时,其他模块能提供足够电源功率。
风扇作为散热的重要手段,中高端设备也提供风扇冗余,一般提供多个风扇框,可以在线更换其中的风扇框,不影响产品功能。
电源和风扇的切换和更换不应该影响产品的转发功能,可以认为其收敛时间为0。
软件系统高可用性主要技术点
动态热补丁
1.热补丁原理
补丁是计算机软件系统和软件工程学中的一个术语,一般是为了对系统中的某些错误进行修正而发布的独立的软件单元。它能够在不影响系统正常运行的情况下完成对系统错误的修正,也就是对系统进行动态升级。
其基本原理就是在系统中保留一段内存空间,将新的函数实体以补丁文件的方式加载其中,根据要被替换函数的入口地址找到被替换函数的第一条执行指令,将其改为一条跳转指令,跳转地址为新函数的入口地址;这样当其他函数要调用被替换函数时,CPU根据跳转指令就会执行新的函数实体。
2.热补丁状态转换
各厂商实现热补丁的基本原理大体相同,但具体实现上有一定差别。下面以H3C公司热补丁技术为例简单介绍状态机转换和各状态的作用。
补丁存在四种状态:
空闲(IDLE):初始状态,补丁没有被加载
去激活(DEACTIVE):补丁已经加载,但未被激活
激活(ACTIVE):补丁处于试运行状态
运行(RUNNING):补丁处于正式运行状态
激活态与运行态的最大区别在于系统重启后,激活态的补丁转换为去激活态,不再发挥作用,而运行态的补丁在系统重启后仍然保持为运行态,继续发挥作用。补丁的激活态主要是提供一个缓冲带,以防止因为补丁错误而导致系统连续运行故障。补丁的状态只有在用户命令的干预下才会发生切换,命令与补丁状态的切换关系如图3所示
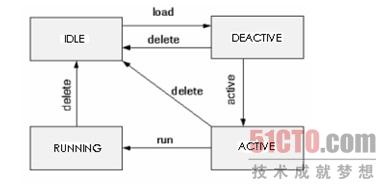
图3 命令与补丁状态切换关系#p#
广域网网络架构高可用设计
物理拓扑对网络可用性的影响
物理拓扑的连接状况决定了网络可用性的计算方法。如图4所示,f1和f2是网络设备自身的可用性指标,当网络设备串行连接时,其组成的部分网络系统的计算为两设备可靠性指标相乘;当网络设备并行连接时,其组成部分网络系统的计算为1减去设备可靠性指标相乘后的反值。多条链路对网络可用性的提升是显而易见的,但对于广域网来说,链路资源是非常宝贵的,因此实际的部署方案是结合具体情况综合考虑的结果。
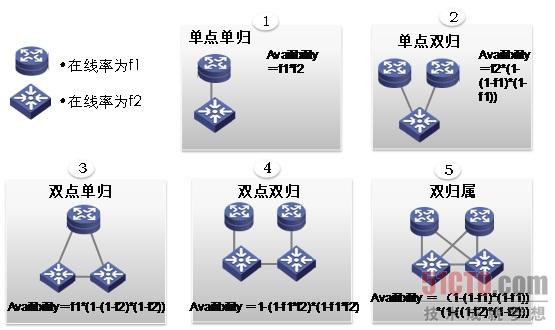
图4 不同拓扑连接方式的可用性计算方法
在条件允许的情况,一般都选用双点双归的拓扑连接方式。其可用性指标对比如表1所示:
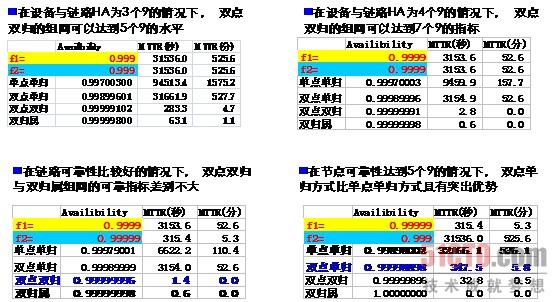
表1 不同拓扑连接方式的典型可用性计算值#p#
广域网路由协议部署高可用设计
广域网网络协议基本以路由协议为主,同时根据广域网拓扑连接和链路种类,会附加部署不同的链路检测协议。以典型的金融双中心网络为例,如图5所示
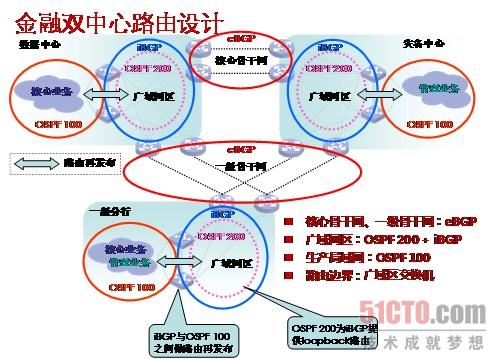
图5 金融双中心网络路由部署示意图
设计原则:路由的高可用设计和所选择的链路种类息息相关,对于大型分支之间链路连接一般选用高带宽的SDH链路,链路的稳定性较高,很少出现闪断和震荡的情况,而且分支之间作为骨干链路,承载着主要的业务流量,需要非常灵活的流量控制策略,因此可部署eBGP协议;对于小型分支与总部互联这种情况,链路种类复杂,链路状况不稳定,因此在部署收敛时间相对较快的路由协议(如OSPF)时,通常会启用BFD、NQA等辅助协议,完成对链路状况的检测,以提高路由协议的收敛速度。
结束语
构建高可用性广域网络,需要从网络组件、网络架构、网络协议部署、网络运维及网络基础支撑等方面全盘考虑,所涉及的内容及其丰富。本文仅针对前三个部分进行部分重点的框架性描述,具体实践还要根据不同的网络使用场景做有针对性的部署。











