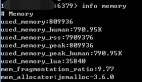
你对JVM内存结构是否熟悉,这里向大家描述一下,主要包括类装载子系统,方法区,PC寄存器,堆和栈等内容,其中方法区被所有线程共享,垃圾收集也会清理方法区中的无用类型对象。
JVM内存结构
1)JVM内存结构之类装载子系统
装载连接初始化
(2)JVM内存结构之方法区。
被所有线程共享。垃圾收集也会清理方法区中的无用类型对象。
a.类型信息。
类加载器加载类时,从类文件中提取出来。
类的完整有效名
父类的完整有效名(interfaceandjava.lang.Object除外,因为无父类)
类型的修饰符
类型直接接口列表
b.常量池。
存储了一个类型所使用的常量所有类型、域和方法的符号引用。
c.域信息。
jvm必须在方法区中保存类型的所有域的相关信息以及域的声明顺序,
域的相关信息包括:
域名
域类型
域修饰符(publicprivateprotectedstaticfinalvolatiletransient…)
d.方法信息。
方法名
方法返回类型
方法参数
方法的修饰符
方法的字节码(abstractandnative除外)(被PC寄存器指向)
操作数栈和方法栈帧的局部变量区的大小#p#
异常表
e.类的静态变量(所有对象共享一分拷贝)
f.类的被声明为final的类变量(所有对象共享一分拷贝)
g.加载一个类的类加载器的引用
h.Class类的引用
i.方法表。
j.一个例子:
ClassLava{
privateintspeed=5;
voidflow();
}
ClassVolcano{
publicstaticvoidmain(String[]args){
Lavalava=newLava();
lava.flow();
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
下面我们描述一下main()方法的***条指令的字节码是如何被执行的。不同的jvm实现的差别很大,这里只是其中之一。
为了运行这个程序,你以某种方式把“Volcano"传给了jvm。有了这个名字,jvm找到了这个类文件(Volcano.class)并读入,它从类文件提取了类型信息并放在了方法区中,通过解析存在方法区中的字节码,jvm激活了main()方法,在执行时,jvm保持了一个指向当前类(Volcano)常量池的指针。
注意jvm在还没有加载Lava类的时候就已经开始执行了。正像大多数的jvm一样,不会等所有类都加载了以后才开始执行,它只会在需要的时候才加载。
main()的***条指令告知jvm为列在常量池***项的类分配足够的内存。
jvm使用指向Volcano常量池的指针找到***项,发现是一个对Lava类的符号引用,然后它就检查方法区看lava是否已经被加载了。
这个符号引用仅仅是类lava的完整有效名”lava“。这里我们看到为了jvm能尽快从一个名称找到一个类,一个良好的数据结构是多么重要。这里jvm的实现者可以采用各种方法,如hash表,查找树等等。同样的算法可以用于Class类的forName()的实现。
当jvm发现还没有加载过一个称为"Lava"的类,它就开始查找并加载类文件"Lava.class"。它从类文件中抽取类型信息并放在了方法区中。
jvm于是以一个直接指向方法区lava类的指针替换了常量池***项的符号引用。以后就可以用这个指针快速的找到lava类了。而这个替换过程称为常量池解析(constantpoolresolution)。在这里我们替换的是一个native指针。
jvm终于开始为新的lava对象分配空间了。这次,jvm仍然需要方法区中的信息。它使用指向lava数据的指针(刚才指向volcano常量池***项的指针)找到一个lava对象究竟需要多少空间。
一旦jvm知道了一个Lava对象所要的空间,它就在堆上分配这个空间并把这个实例的变量speed初始化为缺省值0。假如lava的父对象也有实例变量,则也会初始化。
当把新生成的lava对象的引用压到栈中,***条指令也结束了。下面的指令利用这个引用激活java代码把speed变量设为初始值,5。另外一条指令会用这个引用激活Lava对象的flow()方法。
(3)JVM内存结构之堆。
存放运行时所有对象和数组。
(4)JVM内存结构之栈。
每次启动一个新的线程,就会被分配一个栈。
(5)JVM内存结构之PC寄存器(程序计数器)
总是指向该线程下一步要执行的指令。指令的位置放在方法区的方法字节码中。内容是相对于***个指令的偏移量。
(6)JVM内存结构之本地方法栈。
【编辑推荐】