在Linux/unix服务器的维护过程中,遇到各种各样的问题;有的严重,有的很好解决,有的解决过程我就记录下来与大家分享下,希望能给大家带来帮助。
51CTO特别推荐:明明白白你的Linux服务器
故障一、
今天早上来的第一件事,就是检查昨天晚上刚刚重新安装的一台64位的CentOS 5.5服务器,那台服务器是四块硬盘作的二个RAID1,一个专用于OS,一个用于data,
在安装系统的过程中,为了不损失数据,data分区我碰也碰过,今天用root进系统后,我用mount /dev/mapper/ddf1_datap1 /data进行挂载,很顺利的挂载上去了,结果进去用ll命令一看,我靠,文件全出错了,都不正常了,吓我一跳,data分区里有的数据很重要,特别是mysql数据库,我问了下同事,同事也不是太清楚什么回事,我突然想起,这个是不是没正确挂载的原因,所以将其写进/etc/fstab里,如
/dev/mapper/ddf1_datap1 /data ext3 defaults 0 0
大家别小看defaults选项,这个默认会作许多事情的,reboot后一切正常,虚惊一场,特此记录工作心得,希望也给大家带来帮助;最后是将所有的数据备份后再仔细的fsck一遍,确认无误再进行挂载。
故障二、
故障描述:我们的jail母机192.168.21.36,因root的shell设置成的bash,而其依赖的库文件libintl.so.8发生丢失,导致了root不能登陆,具体报障如下:
/libexec/ld-elf.so.1: Shared object "libintl.so.8" not found, required by "bash"
Connection to 192.168.21.36 closed.
解决方法如下:
1.用单用户模式进入系统;
2.扫描磁盘(此步非做不可,而且是安全的)
fsck -y
3.将文件系统重新挂载
mount -a
4.将root的默认shell切换到sh
chsh -s sh
重启后一切正常
故障三、
在某台工作机上,不小心删除了GRUB所在的分区怎么办?今天闲来无事,不小心删除了grub所在的分区/dev/hdb8,因为装的是windows2003和Centos5.3双系统,搞得连windows也进不了,想想看这已经是第二次犯错了。因为我的工作机上没有光驱和软驱(以前本着经济的原则配置的),上次是借别人的光驱,难道这次又要借,不行,我一定要自己想办法搞定了。花了不少时间把我的台电酷闪8G的优盘量产成了USB-CDROM+USB-HDD双启动的优盘,工作机居然不支持,晕。天寒地冻的,难道真要出门,忽然想起了,工作站支持网络引导,呵呵,那就应该有办法了。请出心爱的网刻软件MaxDOS_71PXE_G115.exe,以下为实验步骤截图:
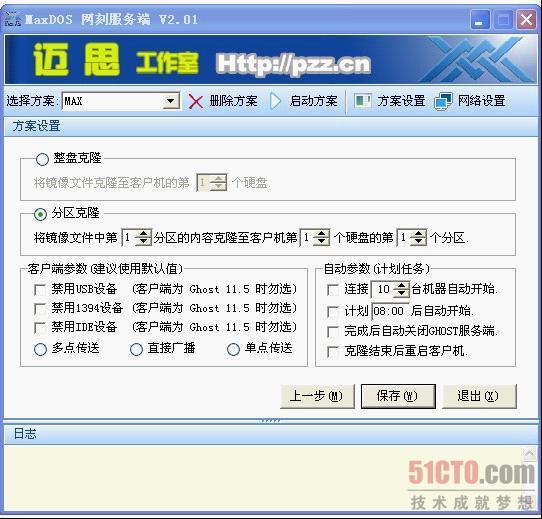
搞定后原以为万事大吉了,发现一启动还是回到了gub报错状态,呵呵,看来还要想心思;不选择"克隆结束后重启计算机",这样就能回到Dos界面下,选择一款MBR修复软件,diskgen或spfdisk即可;或直接fdisk/mbr;其实还有个办法也可行:在“grub>”提示符后输入:“rootnoverify (hd0,0)” 回车将第一块硬盘(hd0)的第一个分区(0)设为根分区/root设备,但不加载文件系统;在“grub>”提示符后输入:“chainloader +1” 回车,将启动引导权转交给当前分区的首扇区(Windows系统所在分区的首扇区)。
其实,这只是一个很简单的、常遇见的grub错误,只要有dos引导盘即可,但关键是我的工作机比较老,即无光驱、软驱,连U盘引导也不支持,如果网络引导也不支持的话,可以用第二种办法尝试(或者强大的Linux命令dd)。修复后重启,故障排除;将以上步骤记录下,方便下次犯错时能迅速排障和重温习下网络Ghost。
故障四、
有台同事在处理Linux服务器时,他移走了一块硬盘,然后就直接启动红帽RHEL5,发现进了Emergency模式,焦急中他连忙跑过来找我;我第一句就是问他:你改动了硬件没,他说他移走了硬盘后就直接启动了,不是跟windows2003一样嘛,有什么问题?我都无语了,没办法 ,耐心跟他讲解 linux下/etc/fatab的作 用及语法,最后告诉他可以在Emergency模式下输入root密码进入此模式,然后用mount –o remount,rw /将/分区设置成可读写,编辑/etc/fatab,将移除的硬盘用#号屏蔽掉后重启服务器,故障解除。
故障五、
FreeBSD下的某台jail虚拟机,可能发生了程序错误形成了死循环,在不停的写某个文件,导致/usr占满,此时Nagios狂报警;这时候 需要快速将其抓取出来,这时候可以先新建 一个测试文件 touch test ,然后 用命令find / -newer test,为了证明其通用性,我特的选择了FreeBSD服务器
……
以上仅仅只是我遇到的形形色色的各种Linux/unix服务器故障之一二而已,我总结了下平时Linux/unix应该注意的事项:
①服务器中最容易坏掉的是风扇,如果是电信机房要注意检查;如果是自己内网服务器机房,平时注意将温度控制在19度以下即可;
②DELL的机器的RAID卡放电和充电都是正常现象,如果有Nagios报警也是正常的;
③有时间就多巡视下机房,检查下服务器的硬盘灯指示情况;
④注意网线不要松脱 了,不然你使用Heartbeat的服务器就很麻烦了;
⑤平时如果有时间和机会,可以作一些关于Keepalived和Heartbeat的模拟故障实验,保证其高可用性。
⑥虚心学习网络相关方面的知识和疑难问题,有时绝大多数的问题是网络方面引起来的;另外,电信一般会封掉80端口的,就不要在这些问题上纠结了。
遇到服务器故障时,一定要胆大心细,谨慎操作,因为有时是线上环境,稍有不慎就灰飞烟灭了,多总结多思考,这样才能成长得更快。
【编辑推荐】