












51CTO数据库频道之前曾报导过《走进列数据库Infobright的世界》,Infobright的总体构架图如下:
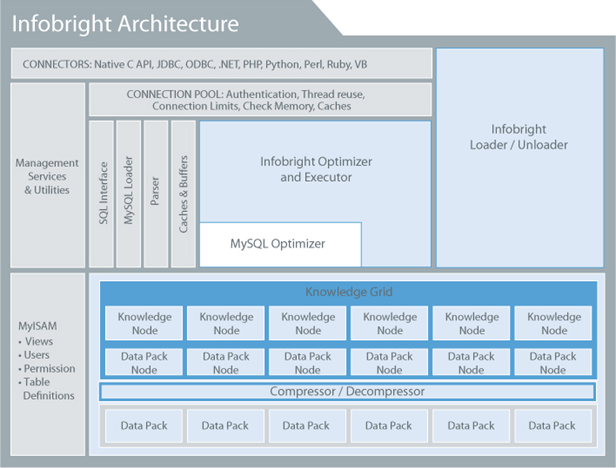
如上图所示,Infobright采用了和MySQL一致的构架,分为两层。上层是服务及应用管理,下层是存储引擎。Infobright的默认存储引擎是brighthouse,但是Infobright还可以支持其他的存储引擎,比如MyISAM、MRG_MyISAM、Memory、CSV。Infobright通过三层来组织数据,分别是DP(Data Pack)、DPN(Data Pack Node)、KN(Knowledge Node)。而在这三层之上就是无比强大的知识网络(Knowledge Grid)。
数据块(DP)是存储的***层,列中每64K个单元组成一个DP。DP比列更小,具有更好的压缩比率;又比单个数据单元更大,具有更好的查询性能。
数据块节点(DPN),DPN和DP之间是一对一的关系。DPN记录着每一个DP里面存储和压缩的一些统计数据,包括***值、最小值、null的个数、单元总数count、sum等等。
KN里面存储着指向DP之间或者列之间关系的一些元数据集合,比如值发生的范围(MIin_Max)、列数据之间的关联。大部分的KN数据是装载数据的时候产生的,另外一些事是查询的时候产生。
在这三层之上是知识网络(Knowledge Grid),Knowledge Grid构架是Infobright高性能的重要原因。

Knowledge Grid可分为四部分,DPN、Histogram、CMAP、P-2-P。
DPN如上所述。Histogram用来提高数字类型(比如date,time,decimal)的查询的性能。Histogram是装载数据的时候就产生的。DPN中有mix、max,Histogram中把Min-Max分成1024段,如果Mix_Max范围小于1024的话,每一段就是就是一个单独的值。这个时候KN就是一个数值是否在当前段的二进制表示。

Histogram的作用就是快速判断当前DP是否满足查询条件。如上图所示,比如select id from customerInfo where id>50 and id<70。那么很容易就可以得到当前DP不满足条件。所以Histogram对于那种数字限定的查询能够很有效地减少查询DP的数量。
CMAP是针对于文本类型的查询,也是装载数据的时候就产生的。CMAP是统计当前DP内,ASCII在1-64位置出现的情况。如下图所示
比如上面的图说明了A在文本的第二个、第三个、第四个位置从来没有出现过。0表示没有出现,1表示出现过。查询中文本的比较归根究底还是按照字节进行比较,所以根据CMAP能够很好地提高文本查询的性能。
Pack-To-Pack是Join操作的时候产生的,它是表示join的两个DP中操作的两个列之间关系的位图,也就是二进制表示的矩阵。
Knowledge Grid还是比较复杂的,里面还有很多细节的东西,可以参考官方的白皮书和Brighthouse: an analytic data warehouse for ad-hoc queries这篇论文。
原文链接:http://blog.chinaunix.net/u2/72637/showart_2306089.html
【编辑推荐】











