












Scala近期正式发布了2.8版本,这门优秀的编程语言将简洁、清晰的语法与面向对象和函数式编程范式无缝融合起来,同时又完全兼容于Java,这样Scala就能使用Java开发者所熟知的Java API和众多的框架了。在这种情况下,我们可以通过Scala改进并简化现有的Java框架。此外,Scala的学习门槛也非常低,因为我们可以轻松将其集成到“众所周知的Java世界中”。
51CTO推荐专题:Scala编程语言
本文将介绍如何通过Scala整合当今世界最为流行的框架之一Spring。Spring不仅支持如依赖注入和面向方面的编程等高效的编程范式,还提供了大量的胶水代码与Hibernate、Toplink等框架以及JEE环境交互,后者更是可以保证Scala能平滑地融入到企业当中,毫无疑问,这是Spring的成功所在。
为了清楚地阐释Scala与Spring的整合原理,本文将使用一个简单的示例应用。这个应用会使用到Scala、Spring和Hibernate/JPA,其领域模型如下图所示:
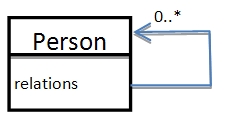
该领域模型展示了一个简化的社交网络应用:人与人之间可以彼此链接起来。
第一步
后面的讲解都将基于该领域模型。首先介绍如何实现一个泛型DAO,并通过Hibernate/JPA使用Scala为Person实体实现一个具体的DAO,该DAO的名字为PersonDao,里面封装了CRUD操作。如下所示:
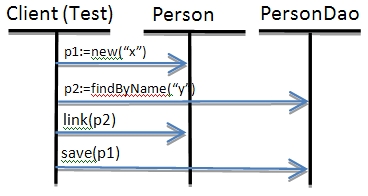
- val p1 = new Person(“Rod Johnson”)
- val p2 = dao.findByName(“Martin Odersky”)
- p1.link(p2)
- personDao.save(p1)
第二步
接下来介绍如何将Person实体转换为一个“内容丰富”的领域对象,在调用link方法时,该对象内部会使用NotificationService执行额外的逻辑,这个服务会“神奇地”按需注入到对象中。下图展示了这一切:
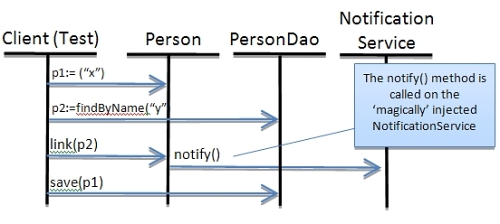
- val p1 = Person(“Martin Odersky”) //the omission of the ‘new’ keyword is intentional
- val p2 = dao.findByName(“Rod Johnson”)
- p1.link(p2) //magic happens here
- personDao.save(p1)
第三步
最后,本文将介绍Spring是如何从Scala的高级概念:特征(traits)中受益的。特征可以将内容丰富的Person领域对象转换为羽翼丰满的OO类,这个类能够实现所有的职责,包括CRUD操作。如下所示:
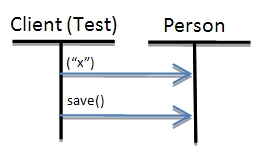
- Person(“Martin Odersky”).save
第一步:使用Scala、Spring和Hibernate/JPA实现DAO
需求
毫无疑问,DAO在设计上应该有一个泛型DAO和一个针对Person实体的具体DAO。泛型DAO中应该包含基本的CRUD方法,如save、remove、findById和findAll等。由于是泛型,因此它处理的是类型而不是具体的实体实现。总的来说,这个泛型DAO具有如下的接口定义:
- trait GenericDao[T] {
- def findAll():List[T]
- def save(entity:T):T
- def remove(entity:T):Unit
- def findById(id:Serializable):T
- }
Person实体类的具体DAO应该增加一个特定于Person实体的finder方法:
- trait PersonDao extends GenericDao[Person] {
- def findByName(name:String):List[Person]
- //more finders here…
- }
我们需要考虑如下具体的实现细节以便利用上Scala提供的众多富有成效的特性:
◆关于集合:虽然底层的JPA实现并不知道所谓的Scala集合,但DAO接口返回的却是Scala集合类型(scala.List)而不是Java集合。因为Scala集合要比Java集合强大的多,因此DAO方法的调用者非常希望方法能够返回Scala集合。这样,我们需要将JPA返回的Java集合平滑地转换为Scala集合。
◆关于回调:Spring用于粘合JPA、JMS等框架的大多数胶水代码都是基于模板模式,比如JpaTemplate、JmsTemplate等。虽然这些模板通过一些便捷的方法在一定程度上隐藏了底层框架的复杂性,但很多时候我们还是不可避免地要直接访问底层的实现类,如EntityManager、JmsSession等。在这种情况下,Spring通过JpaCallback等回调类来实现我们的愿望。回调方法doIn…(..)唯一的参数就是指向实现类的引用,比如EntityManager。下面的示例阐述了这种编程模型:
- jpaTemplate.execute(new JpaCallback() {
- public Object doInJpa(EntityManager em) throws PersistenceException {
- //… do something with the EntityManager
- return null;
- }
- });
上面的代码有两点值得我们注意:首先,匿名内部回调类的实例化需要大量的样板代码。其次,还有一个限制:匿名内部类JpaCallback之外的所有参数都必须是final的。如果从Scala的视角来看待这种回调模式,我们发现里面充斥的全都是某个“函数”的繁琐实现。我们真正想要的只是能够直接访问EntityManager而已,并不需要匿名内部类,而且还得实现里面的doInJpa(…)方法,这有点太小题大作了。换句话说,我们只需要下面这一行足矣:
- jpaTemplate.execute((em:EntityManager) => em.createQuery(…)// etc. );
问题在于如何通过优雅的方式实现这个功能。
◆关于getter和setter:使用了Spring bean的类至少要有一个setter方法,该方法对应于特定bean的名称。毫无疑问,这些setter是框架所需的样板代码,如果不使用构造器注入也能避免这一点岂不美哉?
实现
如果用Scala实现泛型与Person DAO,那么上面提到的一切问题都将迎刃而解,请看:
- object GenericJpaDaoSupport {
- implicit def jpaCallbackWrapper[T](func:(EntityManager) => T) = {
- new JpaCallback {
- def doInJpa(session:EntityManager ) = func(session).asInstanceOf[Object]}
- }
- }
- import Scala.collection.jcl.Conversions._
- class GenericJpaDaoSupport[T](val entityClass:Class[T]) extends JpaDaoSupport with GenericDao[T] {
- def findAll():List[T] = {
- getJpaTemplate().find("from " + entityClass.getName).toList.asInstanceOf[List[T]]
- }
- def save(entity:T) :T = {
- getJpaTemplate().persist(entity)
- entity
- }
- def remove(entity:T) = {
- getJpaTemplate().remove(entity);
- }
- def findById(id:Serializable):T = {
- getJpaTemplate().find(entityClass, id).asInstanceOf[T];
- }
- }
- class JpaPersonDao extends GenericJpaDaoSupport(classOf[Person]) with PersonDao {
- def findByName(name:String) = { getJpaTemplate().executeFind( (em:EntityManager) => {
- val query = em.createQuery("SELECT p FROM Person p WHERE p.name like :name");
- query.setParameter("name", "%" + name + "%");
- query.getResultList();
- }).asInstanceOf[List[Person]].toList
- }
- }
使用:
- class PersonDaoTestCase extends AbstractTransactionalDataSourceSpringContextTests {
- @BeanProperty var personDao:PersonDao = null
- override def getConfigLocations() = Array("ctx-jpa.xml", "ctx-datasource.xml")
- def testSavePerson {
- expect(0)(personDao.findAll().size)
- personDao.save(new Person("Rod Johnson"))
- val persons = personDao.findAll()
- expect(1)( persons size)
- assert(persons.exists(_.name ==”Rod Johnson”))
- }
- }
接下来解释上面的代码是如何解决之前遇到的那些问题的:
关于集合
Scala 2.7.x提供了一个方便的Java集合到Scala集合的转换类,这是通过隐式转换实现的。上面的示例将一个Java list转换为Scala list,如下代码所示:
导入Scala.collection.jcl.Conversions类的所有方法:
- import Scala.collection.jcl.Conversions._
这个类提供了隐式的转换方法将Java集合转换为对应的Scala集合“包装器”。对于java.util.List来说,Scala会创建一个Scala.collection.jcl.BufferWrapper。
调用BufferWrapper的toList()方法返回Scala.List集合的一个实例。
下面的代码阐述了这个转换过程:
- def findAll() : List[T] = {
- getJpaTemplate().find("from " + entityClass.getName).toList.asInstanceOf[List[T]]
- }
总是手工调用“toList”方法来转换集合有些麻烦。幸好,Scala 2.8(在本文撰写之际尚未发布最终版)将会解决这个瑕疵,它可以通过scala.collection.JavaConversions类将Java转换为Scala,整个过程完全透明。
关于回调
可以通过隐式转换将Spring回调轻松转换为Scala函数,如GenericJpaDaoSupport对象中所示:
- implicit def jpaCallbackWrapper[T](func:(EntityManager) => T) = {
- new JpaCallback {
- def doInJpa(session:EntityManager ) = func(session).asInstanceOf[Object]}
- }
借助于这个转换,我们可以通过一个函数来调用JpaTemplate的execute方法而无需匿名内部类JPACallback了,这样就能直接与感兴趣的对象打交道了:
- jpaTemplate.execute((em:EntityManager) => em.createQuery(…)// etc. );
这么做消除了另一处样板代码。
关于getter和setter
默认情况下,Scala编译器并不会生成符合JavaBean约定的getter和setter方法。然而,可以通过在实例变量上使用Scala注解来生成JavaBean风格的getter和setter方法。下面的示例取自上文的PersonDaoTestCase:
- import reflect._
- @BeanProperty var personDao:PersonDao = _
@BeanProperty注解告诉Scala编译器生成setPersonDao(…)和getPersonDao()方法,而这正是Spring进行依赖注入所需的。这个简单的想法能为每个实例变量省掉3~6行的setter与getter方法代码。
第二步:按需进行依赖注入的富领域对象
到目前为止,我们精简了DAO模式的实现,该实现只能持久化实体的状态。实体本身并没有什么,它只维护了一个状态而已。对于领域驱动设计(DDD)的拥趸来说,这种简单的实体并不足以应对复杂领域的挑战。一个实体若想成为富领域对象不仅要包含状态,还得能调用业务服务。为了达成这一目标,需要一种透明的机制将服务注入到领域对象中,不管对象在何处实例化都该如此。
Scala与Spring的整合可以在运行期轻松将服务透明地注入到各种对象中。后面将会提到,这种机制的技术基础是DDD,可以用一种优雅的方式将实体提升为富领域对象。
需求
为了说清楚何谓按需的依赖注入,我们为这个示例应用加一个新需求:在调用Person实体的link方法时,它不仅会链接相应的Person,还会调用NotificationService以通知链接的双方。下面的代码阐述了这个新需求:
- class Person
- { @BeanProperty var notificationService:NotificationService = _ def link(relation:Person) =
- { relations.add(relation) notificationService.nofity(PersonLinkageNotification(this, relation))
- } //other code omitted for readability
- }
毫无疑问,在实例化完Person实体或从数据库中取出Person实体后就应该可以使用NotificationService了,无需手工设置。
使用Spring实现自动装配
我们使用Spring的自动装配来实现这个功能,这是通过Java单例类RichDomainObjectFactory达成的:
- public class RichDomainObjectFactory implements BeanFactoryAware
- {
- pritic RichDomainObjectFactory singleton = new
- RichDomainObjectFactory();
- public static RichDomainObjectFactory autoWireFactory()
- {
- return singleton;
- }
- public void autowire(Object instance)
- {
- factory.autowireBeanProperties(instance)
- }
- public void setBeanFactory(BeanFactory factory) throws BeansException {
- this.factory = (AutowireCapableBeanFactory) factory;
- }
- }
通过将RichDomainObjectFactory声明为Spring bean,Spring容器确保在容器初始化完毕后就设定好了AutowireCapableBeanFactory:
- <bean class="org.jsi.di.spring.RichDomainObjectFactory" factory-method="autoWireFactory"/>
这里并没有让Spring容器创建自己的RichDomainObjectFactory实例,而是在bean定义中使用了factory-method属性,它会强制Spring使用autoWireFactory()方法返回的引用,该引用是单例的。这样会将AutowireCapableBeanFactory注入到单例的RichDomainObjectFactory中。由于可以在同一个类装载器范围内访问单例对象,这样该范围内的所有类都可以使用RichDomainObjectFactory了,它能以一种非侵入、松耦合的方式使用Spring的自动装配特性。毋庸置疑,Scala代码也可以访问到RichDomainObjectFactory单例并使用其自动装配功能。
在设定完这个自动装配工厂后,接下来需要在代码/框架中定义钩子(hook)了。总的来说需要在两个地方定义:
◆ORM层,它负责从数据库中加载实体
◆需要“手工”创建新实体的代码中
自动装配ORM层中的领域对象
由于文中的示例代码使用了JPA/Hibernate,因此在实体加载后需要将这些框架所提供的设备挂载到RichDomainObjectFactory中。JPA/Hibernate提供了一个拦截器API,这样可以拦截和定制实体加载等事件。为了自动装配刚加载的实体,需要使用如下的拦截器实现:
- class DependencyInjectionInterceptor extends EmptyInterceptor {
- override def onLoad(instance:Object, id:Serializable, propertieValues:Array[Object],propertyNames:Array[String], propertyTypes:Array[Type]) = {
- RichDomainObjectFactory.autoWireFactory.autowire(instance)
- false
- }
- }
该拦截器需要做的唯一一件事就是将加载的实体传递给RichDomainObjectFactory的autowire方法。对于该示例应用来说,onLoad方法的实现保证了每次从数据库中加载Person实体后都将NotificationService注入其中。
此外,还需要通过hibernate.ejb.interceptor属性将拦截器注册到JPA的持久性上下文中:
- <persistence-unit name="ScalaSpringIntegration" transaction-type="RESOURCE_LOCAL">
- <provider>org.hibernate.ejb.HibernatePersistence</provider>
- <property name="hibernate.ejb.interceptor" value="org.jsi.domain.jpa.DependencyInjectionInterceptor" />
- </properties>
- <!-- more properties here-->
- </persistence-unit>
DependencyInjectionInterceptor非常强大,每次从数据库中加载实体后它都能将在Spring中配置的服务注入其中。那如果我们在应用代码而非JAP等框架中实例化实体时又该怎么办呢?
自动装配“手工”实例化的领域对象
要想自动装配应用代码中实例化的实体,最简单也是最笨的办法就是通过RichDomainObjectFactory的方式显式进行自动装配。由于这个办法将RichDomainObjectFactory类与实体创建代码紧耦合起来,因此并不推荐使用。幸好,Scala提供了“组件对象”的概念,它担负起工厂的职责,可以灵活实现构造逻辑。
对于该示例应用,我们采用如下方式实现Person对象以便“自动”提供自动装配功能:
- import org.jsi.di.spring.RichDomainObjectFactory._
- object Person {
- def apply(name:String) = {
- autoWireFactory.autowire(new Person(name))
- }
- }
import声明会导入RichDomainObjectFactory的所有静态方法,其中的autoWireFactory()方法会处理RichDomainObjectFactory单例对象。
Scala对象另一个便利的构造手段就是apply()方法,其规则是拥有apply方法的任何对象在调用时可以省略掉.apply()。这样,Scala会将对Person()的调用转给Person.apply(),因此可以将自动装配代码放到apply()方法中。
这样,无需使用“new”关键字就可以调用Person()了,它会返回一个新的实体,返回前所有必要的服务都已经注入进去了,该实体也成为一个“富”DDD实体了。
现在我们可以使用富领域对象了,它是可持久化的,也能在需要时调用其中的服务:
- trait JpaPersistable[T] extends JpaDaoSupport {
- def getEntity:T;
- def findAll():List[T] = {
- getJpaTemplate().find("from " + getEntityClass.getName).toList.asInstanceOf[List[T]]
- }
- def save():T = {
- getJpaTemplate().persist(getEntity)
- getEntity
- }
- def remove() = {
- getJpaTemplate().remove(getEntity);
- }
- def findById(id:Serializable):T = {
- getJpaTemplate().find(getEntityClass, id).asInstanceOf[T];
- }
- //…more code omitted for readability
- }
在继续之前,我们需要解释一下为何要用Java而不是Scala来实现RichDomainObjectFactory,原因是由Scala处理static的方式造成的。Scala故意没有提供static关键字,因为static与复合的OO/函数式范式有冲突。Scala语言所提供的唯一一个静态特性就是对象,其在Java中的等价物就是单例。由于Scala缺少static方法,因此Spring没法通过上文介绍的factory-method属性获得RichDomainObjectFactory这样的工厂对象。这样,我们就没法将Spring的AutowireCapableBeanFactory直接注入到Person对象中了。因此,这里使用Java而非Scala来利用Spring的自动装配功能,它能彻底填充static鸿沟。
第三步:使用Scala traits打造功能完善的领域对象
到目前为止一切尚好,此外,Scala还为OO纯粹主义者提供了更多特性。使用DAO持久化实体与纯粹的OO理念有些许冲突。从广泛使用的DAO/Repository模式的角度来说,DAO只负责执行持久化操作,而实体则只维护其状态。但纯粹的OO对象不仅有状态,还要有行为。
上文介绍的实体是拥有服务的,这些服务封装了一些行为性职责,但持久化部分并不在其中。为什么不把所有的行为性和状态性职责都赋给实体呢,就像OO纯粹主义者所倡导的那样,让实体自己负责持久化操作。事实上,这是习惯问题。但使用Java很难以优雅的方式让实体自己去实现持久化操作。这种设计严重依赖于继承,因为持久化方法要在父类中实现。这种方式相当麻烦,也缺少灵活性。Java从概念上就缺少一个良好设计的根基,没法很好地实现这种逻辑。但Scala则不同,因为Scala有traits。
所谓trait就是可以包含实现的接口。它类似于C++中多继承的概念,但却没有众所周知的diamond syndrome副作用。通过将DAO代码封装到trait中,该DAO trait所提供的所有持久化方法可自动为所有实现类所用。这种方式完美地诠释了DRY(Don’t Repeat Yourself)准则,因为持久化逻辑只实现一次,在需要的时候可以多次混合到领域类中。
对于该示例应用来说,其DAO trait如下代码所示:
- trait JpaPersistable[T] extends JpaDaoSupport {
- def getEntity:T;
- def findAll():List[T] = {
- getJpaTemplate().find("from " + getEntityClass.getName).toList.asInstanceOf[List[T]]
- }
- def save():T = {
- getJpaTemplate().persist(getEntity)
- getEntity
- }
- def remove() = {
- getJpaTemplate().remove(getEntity);
- }
- def findById(id:Serializable):T = {
- getJpaTemplate().find(getEntityClass, id).asInstanceOf[T];
- }
- //…more code omitted for readability
- }
作为一个传统的DAO,该trait继承了Spring的JpaDaoSupport,但它并没有提供save、update和delete方法(这些方法需要接收一个实体作为参数)转而定义了一个抽象方法getEntity,需要持久化功能的领域对象得实现这个方法。JpaPersistable trait在内部实现中使用getEntity来保存、更新和删除特定的实体,如下代码片段所示。
- trait JpaPersistable[T] extends JpaDaoSupport {
- def getEntity:T
- def remove() = {
- getJpaTemplate().remove(getEntity);
- }
- //…more code omitted for readability
- )
实现该trait的领域对象只需实现getEntity方法即可,该方法的实现仅仅是返回一个自身引用:
- class Person extends JpaPersistable[Person] with java.io.Serializable {
- def getEntity = this
- //…more code omitted for readability
- }
这就是全部了。所有需要持久化行为的领域对象只需实现JpaPersistable trait即可。最后我们得到的是一个包含了状态和行为功能完善的领域对象,完全符合纯粹的OO编程的理念:
- Person(“Martin Odersky”).save
无论你是否为纯粹的OO理念的拥护者,这个示例都阐释了Scala(尤其是traits概念)是如何轻松实现纯粹的OO设计的。
结论
本文示例介绍了Scala与Spring是如何实现互补的。Scala简明、强大的范式(比如函数与特征)再结合Spring的依赖注入、AOP和Java AP为我们I提供了更广阔的空间,相对于Java代码来说,Scala的实现更具表现力、代码量也更少。
如果具有Spring和Java基础,Scala的学习曲线非常低,因为我们只需要学习一门新语言就行,无需再学大量的API了。
Scala和Spring所提供的众多功能使得这一组合成为企业采用Scala的最佳选择。总之,我们能以极低的代价迁移到更加强大的编程范式上来。
关于作者
Urs Peter是Xebia的高级咨询师,专注于企业级Java和敏捷开发。它有9年的IT从业经历。在整个IT职业生涯中,他担任过不同角色,从开发者、软件架构师到Scrum Master。目前,他在下一代的荷兰铁路信息系统项目中担任Scrum Master,该项目部分使用Scala实现。他还是Xebia的一名Scala布道师和荷兰Scala用户组的活跃分子。
文中所用源代码
感兴趣的读者可以使用git:git clone git://github.com/upeter/Scala-Spring-Integration.git在http://github.com/upeter/Scala-Spring-Integration上下载完整的源代码并使用maven构建。
查看英文原文:Scala & Spring: Combine the best of both worlds
【编辑推荐】
- 编程思想碰撞 Scala不是改良的Java
- Scala 2.8最终发布 全新功能值得期待
- Scala vs F#:函数式编程特性大比拼(一)
- Scala vs F#:函数式编程特性大比拼(二)
- 用Java在各种框架下编译Scala项目















