Linux Kernel 2.6.20 以上的内核支持进程 IO 统计,可以用类似 iotop 这样的工具来监测每个进程对 IO 操作的情况,就像用 top 来实时查看进程内存、CPU 等占用情况那样。但是对于 2.6.20 以下的 Linux 内核版本就没那么幸运了。笔者写了一个简单的 Python 脚本用来在 linux kernel < 2.6.20 下打印进程 IO 状况。
Kernel < 2.6.20
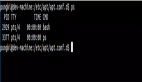
这个脚本的想法很简单,把 dmesg 的结果重定向到一个文件后再解析出来,每隔1秒钟打印一次进程 IO 读写的统计信息,执行这个脚本需要 root:
#!/usr/bin/python
# Monitoring per-process disk I/O activity
# written by http://www.vpsee.com
import sys, os, time, signal, re
class DiskIO:
def __init__(self, pname=None, pid=None, reads=0, writes=0):
self.pname = pname
self.pid = pid
self.reads = 0
self.writes = 0
def main():
argc = len(sys.argv)
if argc != 1:
print "usage: ./iotop"
sys.exit(0)
if os.getuid() != 0:
print "must be run as root"
sys.exit(0)
signal.signal(signal.SIGINT, signal_handler)
os.system('echo 1 > /proc/sys/vm/block_dump')
print "TASK PID READ WRITE"
while True:
os.system('dmesg -c > /tmp/diskio.log')
l = []
f = open('/tmp/diskio.log', 'r')
line = f.readline()
while line:
m = re.match(\
'^(\S+)\((\d+)\): (READ|WRITE) block (\d+) on (\S+)', line)
if m != None:
if not l:
l.append(DiskIO(m.group(1), m.group(2)))
line = f.readline()
continue
found = False
for item in l:
if item.pid == m.group(2):
found = True
if m.group(3) == "READ":
item.reads = item.reads + 1
elif m.group(3) == "WRITE":
item.writes = item.writes + 1
if not found:
l.append(DiskIO(m.group(1), m.group(2)))
line = f.readline()
time.sleep(1)
for item in l:
print "%-10s %10s %10d %10d" % \
(item.pname, item.pid, item.reads, item.writes)
def signal_handler(signal, frame):
os.system('echo 0 > /proc/sys/vm/block_dump')
sys.exit(0)
if __name__=="__main__":
main()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
Kernel >= 2.6.20
如果想用 iotop 来实时查看进程 IO 活动状况的话,需要下载和升级新内核(2.6.20 或以上版本)。编译新内核时需要打开 TASK_DELAY_ACCT 和 TASK_IO_ACCOUNTING 选项。解压内核后进入配置界面:
# tar jxvf linux-2.6.30.5.tar.bz2
# mv linux-2.6.30.5 /usr/src/
# cd /usr/src/linux-2.6.30.5
# make menuconfig- 1.
- 2.
- 3.
- 4.
- 5.
选择 Kernel hacking –> Collect scheduler debugging info 和 Collect scheduler statistics,保存内核后编译内核:
# make; make modules; make modules_install; make install- 1.
修改 grub,确认能正确启动新内核:
# vi /boot/grub/menu.lst- 1.
出了新内核外,iotop 还需要 Python 2.5 或以上才能运行,所以如果当前 Python 是 2.4 的话需要下载和安装最新的 Python 包。这里使用源代码编译安装:
# tar jxvf Python-2.6.2.tar.bz2
# cd Python-2.6.2
# ./configure
# make; make install- 1.
- 2.
- 3.
- 4.
别忘了下载 setuptools:
# mv setuptools-0.6c9-py2.6.egg.sh setuptools-0.6c9-py2.6.egg
# sh setuptools-0.6c9-py2.6.egg- 1.
- 2.
有网友对以上脚本提出问题,问到 WRITE 为什么会出现是 0 的情况,这是个好问题,笔者在这里好好解释一下。首先看看我们怎么样才能实时监测不同进程的 IO 活动状况。
block_dump
Linux 内核里提供了一个 block_dump 参数用来把 block 读写(WRITE/READ)状况 dump 到日志里,这样可以通过 dmesg 命令来查看,具体操作步骤是:
# sysctl vm.block_dump=1
or
# echo 1 > /proc/sys/vm/block_dump- 1.
- 2.
- 3.
然后就可以通过 dmesg 就可以观察到各个进程 IO 活动的状况了:
# dmesg -c
kjournald(542): WRITE block 222528 on dm-0
kjournald(542): WRITE block 222552 on dm-0
bash(18498): dirtied inode 5892488 (ld-linux-x86-64.so.2) on dm-0
bash(18498): dirtied inode 5892482 (ld-2.5.so) on dm-0
dmesg(18498): dirtied inode 11262038 (ld.so.cache) on dm-0
dmesg(18498): dirtied inode 5892496 (libc.so.6) on dm-0
dmesg(18498): dirtied inode 5892489 (libc-2.5.so) on dm-0- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
问题
一位细心的网友提到这样一个问题:为什么会有 WRITE block 0 的情况出现呢?笔者跟踪了一段时间,发现确实有 WRITE 0 的情况出现,比如:
# dmesg -c
...
pdflush(23123): WRITE block 0 on sdb1
pdflush(23123): WRITE block 16 on sdb1
pdflush(23123): WRITE block 104 on sdb1
pdflush(23123): WRITE block 40884480 on sdb1
...- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
答案
原来我们把 WRITE block 0,WRITE block 16, WRITE block 104 这里面包含的数字理解错了,这些数字不是代表写了多少 blocks,是代表写到哪个 block,为了寻找真相,笔者追到 Linux 2.6.18 内核代码里,在 ll_rw_blk.c 里找到了答案:
$ vi linux-2.6.18/block/ll_rw_blk.c
void submit_bio(int rw, struct bio *bio)
{
int count = bio_sectors(bio);
BIO_BUG_ON(!bio->bi_size);
BIO_BUG_ON(!bio->bi_io_vec);
bio->bi_rw |= rw;
if (rw & WRITE)
count_vm_events(PGPGOUT, count);
else
count_vm_events(PGPGIN, count);
if (unlikely(block_dump)) {
char b[BDEVNAME_SIZE];
printk(KERN_DEBUG "%s(%d): %s block %Lu on %s\n",
current->comm, current->pid,
(rw & WRITE) ? "WRITE" : "READ",
(unsigned long long)bio->bi_sector,
bdevname(bio->bi_bdev,b));
}
generic_make_request(bio);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
很明显从上面代码可以看出 WRITE block 0 on sdb1,这里的 0 是 bio->bi_sector,是写到哪个 sector,不是 WRITE 了多少 blocks 的意思。还有,如果 block 设备被分成多个区的话,这个 bi_sector(sector number)是从这个分区开始计数,比如 block 0 on sdb1 就是 sdb1 分区上的第0个 sector 开始。
原文地址:http://www.vpsee.com/2010/07/monitoring-process-io-activity-on-linux-with-block_dump/
【编辑推荐】