如果说提供云计算这种巨型计算服务的IT架构必然是集结了大规模基础资源的数据中心“超级航母”,它也必然要求大规模计算网络与其相适应。
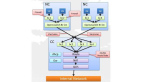
云计算IT资源供应模型
云计算既然拥有近乎无限的计算、存储、数据通信能力,那么提供云计算服务的IT架构必然是集结了大规模基础资源的数据中心“超级航母”。
云计算IT资源的大规模集中运营,可极大优化基础资源的分布与调度,图1所示为理想的业务模型。对于使用云计算服务的企业或个人而言,能够满足IT业务的***方式为计算能力按需增长、应用部署快速实现、工作负载可动态调整、投入成本规划可控;对于云计算服务供应商而言,为满足大量客户(个人或企业)的IT资源需求,其运营的IT基础架构需要有一个大规模的资源池,可基于服务客户数量的增长、客户业务负载增长的需求变化情况提供匹配的IT资源支持能力。

图1 云计算IT资源供应模型
大规模云计算服务运营趋势
大规模的IT集中建设与运营带来将是大幅度的成本节约效应。据国外一份统计数据显示(如图2所示),在大规模IT服务环境下,网络、存储、服务器/管理等各方面的投入都会在单位资源尺度内极大降低,从而在大规模经营条件下使得单位资源带来更大的产出。

图2 大规模IT运营的成本优势
(正文从这里开始)
在大规模云计算运营趋势下,IT基础组件必然走向全面标准化,以使得云所支撑各部分可以在保持发展的同时相互兼容。当前的虚拟化标准组织、云计算标准化组织已经基本形成,它们的工作目的就是制定云计算不同组件、不同技术之间的公共接口,这样众多的软硬件供应商能够在云计算环境下提供互通、协作的标准化产品,从而可期望在远期目标上使得云计算的大规模IT运营架构逐步摆脱隔离性、垄断性,使公共服务得以构建在开放的公共化标准技术基础上,并随着技术发展而持续性降低成本。
对于大规模的计算网络,在基础形态上主要有两种模式:虚拟化计算与集群计算。其实这两种方式并无完全的割离,即可能分别部署,也可能相互结合。
一、大规模虚拟化计算与网络架构
虚拟化计算技术已经逐步成为云计算服务的主要支撑技术,特别是在计算能力租赁、调度的云计算服务领域起着非常关键的作用。
在大规模计算资源集中的云计算数据中心,以X86架构为基准的不同服务器资源,通过虚拟化技术将整个数据中心的计算资源统一抽象出来,形成可以按一定粒度分配的计算资源池,如图3所示。虚拟化后的资源池屏蔽了各种物理服务器的差异,形成了统一的、云内部标准化的逻辑CPU、逻辑内存、逻辑存储空间、逻辑网络接口,任何用户使用的虚拟化资源在调度、供应、度量上都具有一致性。

图3 大规模虚拟化云计算
虚拟化技术不仅消除大规模异构服务器的差异化,其形成的计算池可以具有超级的计算能力(如图4所示),一个云计算中心物理服务器达到数万台是一个很正常的规模。一台物理服务器上运行的虚拟机数量是动态变化的,当前一般是4到20,某些高密度的虚拟机可以达到100:1的虚拟比(即一台物理服务器上运行100个虚拟机),在CPU性能不断增强(主频提升、多核多路)、当前各种硬件虚拟化(CPU指令级虚拟化、内存虚拟化、桥片虚拟化、网卡虚拟化)的辅助下,物理服务器上运行的虚拟机数量会迅猛增加。一个大型IDC中运行数十万个虚拟机是可预见的,当前的云服务IDC在业务规划时,已经在考虑这些因素。

图4 密集的虚拟机群
在虚拟化云计算网络环境,超高密度的虚拟机数量引入了有别于任何以往传统意义上数据中心的业务承载问题,在表象相似的网络平台上,“服务器/虚拟机”的数量在单位空间和单位网络接口剧增,如图5所示,对基础网络的转发表项、吞吐能力、突发流量吸收提出了苛刻的要求。

图5 密集的应用与性能要求
虚拟化的云中,计算资源能够按需扩展、灵活调度部署,这由虚拟机的迁移功能实现,虚拟化环境的计算资源必须在二层网络范围内实现透明化迁移(如图6所示)。

图6 透明网络支持虚拟资源的调度迁移
透明环境不仅限于数据中心内部,对于多个数据中心共同提供的云计算服务,要求云计算的网络对数据中心内部、数据中心之间均实现透明化交换(如图7所示),这种服务能力可以使客户分布在云中的资源逻辑上相对集中(如在相同的一个或数个VLAN内),而不必关心具体物理位置;对云服务供应商而言,透明化网络可以在更大的范围内优化计算资源的供应,提升云计算服务的运行效率、有效节省资源和成本。

图7 大规模虚拟化云计算的透明化网络承载
二、大规模集群计算与网络架构
集群计算很早就广泛应用了,只是在不同的领域有着不同的表现形式,或者说有不同的术语,如在科学计算领域的并行计算或高性能计算当前主要以集群计算的方式实现。集群通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作,在某种意义上,集群可以被看作是一台计算机。
人们使用集群的目的是为了获得强大的计算能力,虽然这可以通过购买具备超级计算能力的大型机来实现,但是在成本投入上是巨大的。对于一般计算机,计算能力是有限的,虽然摩尔定律说计算能力每18个月可以翻一番,但要达到大型机的性能,很长一段时间内是难以实现的(摩尔定律被普遍认为在过去30年相当有效,未来10~15年应依然适用)。因此,为突破摩尔定律的限制,将多台低成本计算机通过集群方式,以并行计算来获取更大的计算能力,成为各种追求高性能计算领域的主流方向(如图8所示)。

图8 以集群架构超越摩尔定律
以互联网应用为例,有的计算服务要求提供超级计算能力,如大型搜索引擎的构建,就是大量服务器群共同协作实现的巨量计算。
科研领域并行计算的主流技术是MPI(Message Passing Interface),但以支持Fortran、C语言的科学计算为优势。云计算领域的代表性技术是Hadoop(还有其它类似的分布式计算技术),突出商用的扩展性架构、大数据量处理,大大简化开发难度,屏蔽系统底层的复杂性。
Hdoop是目前在互联网使用广泛的一种云计算支撑架构,借助于Hadoop, 程序员可以轻松地编写分布式并行程序,将其运行于大型计算机集群上,完成海量数据的计算。图9是当前广为流传的Hadoop分布式文件系统体系架构模型,这一类的集群架构将服务器按群分置不同角色群,角色协同完成大规模计算任务。

图9 Hadoop分布式文件系统体系架构
这些角色包括NameNode,它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。DataNode 响应来自 HDFS 客户机的读写请求。NameNode 与每个 DataNode 有定期心跳(heartbeat)消息检查健康性。
分布式文件系统的设计需求对应到网络的架构上主要有:并发吞吐性能、可伸缩性、容错需求等。
HDFS的目标就是构建在大规模廉价机器上的分布式文件系统集群,一个文件可以表示为其内容在不同位置的多个拷贝。这样做带来了两个好处:访问同个文件时可以从多个服务器中获取从而改善服务的伸缩性,另外就是提高了容错能力,某个副本损坏了,仍然可以从其他服务器节点获取该文件。同时集群内部还通过心跳检测、集群的负载均衡等特性提升容错性。
传统HDFS采用一种称为rack-aware的策略来改进数据的可靠性、有效性和网络带宽的利用,典型的组网逻辑如图10所示(也是流传比较广泛的一张图,笔者未加修改)。

图10 经典的Hadoop组网结构
图10中每个交换及所接服务器被安装在数据中心的同一个机架(rack)内,该交换机称为Top of rack switch,典型情况下每个机架内部署40台服务器(国外比较流行,国内当前达到这样密度的IDC很少),一般采用48千兆端口的交换机,传统设计中会采用4个到8个千兆上行,因此每个机架上行的带宽收敛比一般在5:1~10:1。
不同机架间的两台机器的通讯需要通过交换机,显然通常情况下,同一个机架内的两个节点间的带宽会比不同机架间的两台机器的带宽大。因此Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度。
通过一个称为Rack Awareness的过程,Namenode决定了每个Datanode所属的rack id。一个简单但没有优化的策略就是将副本存放在单独的机架上。这样可以防止整个机架(非副本存放)失效的情况,并且允许读数据的时候可以从多个机架读取。这个简单策略设置可以将副本分布在集群中,有利于组件失败情况下的负载均衡。但是,这个简单策略加大了写的代价,因为一个写操作需要传输block到多个机架。
为了降低整体的带宽消耗和读延时,HDFS会尽量让reader读最近的副本。如果在reader的同一个机架上有一个副本,那么就读该副本。如果一个HDFS集群跨越多个数据中心,那么reader也将首先尝试读本地数据中心的副本。
HDFS支持数据的均衡分布处理,如果某个Datanode节点上的空闲空间低于特定的临界点,那么就会启动一个计划自动地将数据从一个Datanode搬移到空闲的Datanode。当对某个文件的请求突然增加,那么也可能启动一个计划创建该文件新的副本,并分布到集群中以满足应用的要求。
我们可以看到,Hadoop系统在开发过程中关注了数据交换对象(计算节点)之间的距离,实际上是考虑了网络构建模型中带宽不匹配因素。这种因素的引入,不仅编程人员需要关心,业务部署人员、网络维护人员也都要关心,在小规模环境下还能够勉强运行,但是如果要支持全互联网级的大规模应用,集群可能达到数千台、数万台,业务的部署、扩展、运行、支撑都会存在很多问题。如图11是一种高扩展要求的集群模型,这类集群应用自身是分层架构,每一层应用都是一个大规模集群,采用传统方式构建交换网络,必将存在诸多限制,无法发挥云计算巨型计算的服务能力。

图11 大规模集群架构
随着网络交换万兆技术的发展和设备成本的不断降低,目前大规模集群的构建也发展到新的阶段,需要新的网络结构来支持和运行:
无阻塞网络架构:满足集群环境中所有服务器的对等通信要求,任意节点之间可以达到相等带宽(当前是以千兆为主),服务器应用程序不再关注数据交互节点是在一个机架内还是在其它机架。
大规模集群能力:当前2千台规模的服务器集群已经在互联网行业广泛部署,随着云计算业务的开发提供,更大规模的集群(5000-1万台)将成为支持云计算的主流网络结构,无阻塞架构是这种网络的基本要求。
足够扁平化的架构:所谓扁平化就是极大减少组网结构层次,目前数据中心扁平化结构以两层物理网络为主流。在还是千兆为主的服务器端口条件下,接入交换机的用户端口数一般为48个千兆,要满足无阻塞的跨机架带宽,则上行带宽需要5个万兆(当然也可以只使用40个千兆接入,4个万兆上行),而核心交换则需要高密的万兆(>120)全线速能力。
图12是一种新的无阻塞网络模型,也被称为CLOS组网结构。在接入层交换机当前可达到50个千兆端口(常规是48,可用两个万兆自适应千兆),无阻塞上行5个万兆到5台高密万兆核心设备,当核心万兆密度超过140端口,则整个集群规模可达到7000台服务器。网络规划上将二层终结在接入层,使用等价路由将接入交换机的上行链路带宽进行负载分担,从而可以实现整个网络的无阻塞交换,任意服务器端口之间可以具有千兆线速的能力,完全消除了云计算集群内部的带宽限制因素。

图12 大规模无阻塞集群网络
消除了带宽限制的无阻塞集群,应用内部交换数据变得足够灵活,数据访问不再受限于服务器的物理位置,将使得数据中心的流量在大范围内流动(如图13所示)。以无阻塞网络构建的大规模计算群,更有利于云计算性能的充分发挥。

图13 大规模集群的大范围流量交换
三、结束语
云计算的大规模运营,给传统网络架构和传用应用部署经验都带来了挑战,新一代网络支撑这种巨型的计算服务,不论是技术革新还是架构变化,都需要服务于云计算的核心要求,动态、弹性、灵活,并实现网络部署的简捷化。