【51CTO独家特稿】本篇文章是《明明白白你的Linux服务器》系列的***篇。写这篇文章的目的,是因为我经常要到客户的机房或托管的IDC去从事相关系统工作,少则十几台,多则上百,通过下面的内容,你应该能很清楚你目前的Linux服务器的状态性能等信息。
一、如何查看服务器的CPU
今天安装了9台Linux服务器,型号完全不一样(有DELL、HP和IBM服务器),又懒得去对清单,如何在Linux下cpu的个数和核数呢?另外,nginx的cpu工作模式也需要确切的知道linux服务器到底有多少个逻辑cpu,不过现在服务器那是相当的彪悍,直接上worker_processes 8吧。
判断依据:
1.具有相同core id的cpu是同一个core的超线程。(Physical id and core id are not necessarily consecutive but they are unique. Any cpu with the same core id are hyperthreads in the same core.)
2.具有相同physical id的cpu是同一颗cpu封装的线程或者cores。(Any cpu with the same physical id are threads or cores in the same physical socket.)
以自己的惠普DL380G6为例说明:
①物理cpu个数:
[root@localhost ~]# cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
②每个物理cpu中core的个数(即核数)
[root@localhost ~]# cat /proc/cpuinfo | grep "cpu cores" | uniq cpu cores : 4
这样可以推算出自己服务器的逻辑CPU为物理个数*核数,如果你的服务器是server2003,你可以在你的资源管理器里以图形化方式看到你的逻辑CPU个数。
二、查看服务器的内存情况
有时候,你运行了许多大的进程,比如你开启了300个fast-cgi。这时候你感觉系统很慢,便需要查看服务器的内存情况:
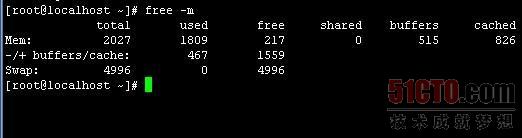
[root@server ~]# free -m total used free shared buffers cached Mem: 249 163 86 0 10 94 -/+ buffers/cache: 58 191 Swap: 511 0 511
参数解释:
total 内存总数 used 已经使用的内存数 free 空闲的内存数 shared 多个进程共享的内存总额 buffers Buffer Cache和cached Page Cache 磁盘缓存的大小 -buffers/cache (已用)的内存数:used - buffers - cached +buffers/cache(可用)的内存数:free + buffers + cached 可用的memory=free memory+buffers+cached
上面的数值是一台我公司内网供PHP开发人员使用的DELL PE2850,内存为2G的服务器,其可使用内存为=217+515+826。记住,Linux的内存使用管理机制是有多少就用多少(特别是在频繁存取文件后),即Linux内存不是拿来看的,是拿来用的。
三、服务器磁盘使用情况
有时感觉硬盘反映很慢,或需要查看日志所在分区时,下列命令可以查看磁盘的使用情况,很有用:
①查看硬盘分区情况
fdisk –l
②查看当前硬盘使用情况
df –h
③查看硬盘性能
# iostat -x 1 10
Linux 2.6.18-92.el5xen 03/01/2010
avg-cpu: %user %nice %system %iowait %steal %idle
1.10 0.00 4.82 39.54 0.07 54.46
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 3.50 0.40 2.50 5.60 48.00 18.48 0.00 0.97 0.97 0.28
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdd 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sde 0.00 0.10 0.30 0.20 2.40 2.40 9.60 0.00 1.60 1.60 0.08
sdf 17.40 0.50 102.00 0.20 12095.20 5.60 118.40 0.70 6.81 2.09 21.36
sdg 232.40 1.90 379.70 0.50 76451.20 19.20 201.13 4.94 13.78 2.45 93.16
像我们公司,开发人员占多数。有时为了节约成本,会同时采购一些性价比比较高的二手服务器;这时一般将服务器的硬件的工作模式设置为RAID1,同时对几种型号的服务器作相同文件的写操作,然后各自执行iostat –d,作对比性测试。这样服务器的硬盘性能孰优孰劣,一下子就能对比出来。

图解:
Tps 该设备每秒I/O传输的次数(每秒的I/O请求)
Blk_read/s 表求从该设备每秒读的数据块数量
Blk_wrth/s 表示从该设备每秒写的数据块数量
编辑推荐:Linux系统监控之磁盘I/O篇
#p#
四、查看系统内核
查看系统内核主要为了掌握其版本号,为安装LVS等软件做准备。
uname –a
有关查看内核信息的更多指令,可参考Linux查看版本信息及CPU内核、型号等一文。有关Linux的内核优化,则可参考Linux 2.6.31内核优化指南一文。
五、查看服务器使用的Linux发行版的名称、版本号及描述信息等
lsb_release -a
这是我的某台用于SVN实验的vmware机器情况:

六、查看服务器的平均负载
感觉到系统压力较大时用可top或uptime查看下服务器的平均负载。uptime的另一个用法是查看你的Linux服务器已经稳定运行多少天没有重启了,我这边的机器***记录是360多天。
七、查看系统整体性能情况
如果感觉系统比较繁忙,可以用vmstat查看系统整体性能情况。vmstat不仅仅适应于linux系统,它一样适用于FreeBSD等unix系统。
vmstat 1 2
如果 r经常大于 4 ,且id经常少于40,表示cpu的负荷很重。
如果pi,po 长期不等于0,表示内存不足。
如果disk 经常不等于0, 且在 b中的队列 大于3, 表示 io性能不好。
编辑推荐:Linux系统监控工具之vmstat详解
八、查看系统已载入的相关模块
Linux操作系统的核心具有模块化的特性,应此在编译核心时,务须把全部的功能都放入核心。你可以将这些功能编译成一个个单独的模块,待需要时再分别载入。比如说在安装LVS+Keepalived,下列用法被经常用到:
#检查内核模块,看一下ip_vs是否被加载 lsmod |grep ip_vs ip_vs 77313 0
如果要查看当前系统的已加载模块,直接lsmod。
九、Linux下查找PCI设置
有时需要在Linux下查找PCI设置,可用lspci命令,它可以列出机器中的PCI 设备,比如声卡、显卡、Modem、网卡等,主板集成设备也能列出来。lspci 读取的是hwdata 数据库。有的小伙可能和我一样,最关心的还是网卡型号:
[root@mail ~]# lspci | grep Ethernet 03:00.0 Ethernet controller: Broadcom Corporation NetXtreme II BCM5708 Gigabit Ethernet (rev 12) 07:00.0 Ethernet controller: Broadcom Corporation NetXtreme II BCM5708 Gigabit Ethernet (rev 12)
推荐阅读:七大实用命令行工具 玩转Linux网络配置。至于网络流量的监控,建议用centos自带的工具iptraf,其用法可参考这篇文章。
掌握上面这九条,你对你的Linux服务器的硬件信息基本就可以随时掌控了。
【编辑推荐】