本节和大家学习一下Hadoop的分布式文件系统HDFS,主要包括HDFS的设计思想,还有HDFS的一些相关功能介绍,希望通过本节的介绍大家对HDFS有一定的认识。
Hadoop的分布式文件系统HDFS的设计思想:
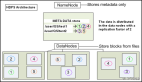
构建一个非常庞大的分布式文件系统。在集群中节点失效是正常的,节点的数量在Hadoop中不是固定的.单一的文件命名空间,保证数据的一致性,写入一次多次读取.典型的64MB的数据块大小,每一个数据块在多个DN(DataNode)有复制.客户端通过NN(NameNode)得到数据块的位置,直接访问DN获取数据。
NameNode功能:
Hadoop的分布式文件系统HDFS中的NameNode功能。映射一个文件到一批的块,映射数据块到DN节点上。集群配置管理,数据块的管理和复制。处理事务日志:记录文件生成,删除等。因为NameNode的全部的元数据在内存中存储,所以NN的内存大小决定整个集群的存储量。NN内存中保存的数据:
文件列表
每一个文件的块列表
每一个DN中块的列表
文件属性:生成时间,复制参数,文件许可(ACL)
File,Derectory,Block在内存中的大小(HadoopJIRA页面):
File:122+fileName.length
Directory:152+fileName.length
Block:112+24*replication
备注:上面数据和jira中不一样是因为在0.16以上的版本在INode中添加了一个8字节的数据类型为long的permission数据。
NN的复制线程负责根据文件复制数量选择DN,磁盘的使用负载平衡,DN复制时的IPC通信负载平衡。
SecondaryNamenode的功能:
SecondaryNamenode是一个让人混淆的名字,其实SecondaryNamenode是一个辅助NN处理FsImage和事务日志的Server,它从NN拷贝FsImage和事务日志到临时目录,合并FsImage和事务日志生成一个新的FsImage,上传新的FsImage到NN上,NN更新FsImage并清理原来的事务日志。
DataNode功能:
在本地文件系统存储数据块,存储数据块的元数据,用于CRC校验。响应客户端对数据块和元数据的请求。周期性的向NN报告这个DN存储的所有数据块信息。客户端要存储数据时从NN获取存储数据块的DN位置列表,客户端发送数据块到第一个DN上,第一个DN收到数据通过管道流的方式把数据块发送到另外的DN上。当数据块被所有的节点写入后,客户端继续发送下一个数据块。DN每3秒钟发送一个心跳到NN,如果NN没有受到心跳在重新尝试后宣告这个DN失效。当NN察觉到DN节点失效了,选择一个新的节点复制丢失的数据块。我们再来看一下Hadoop的分布式文件系统HDFS中数据块的问题。
数据块的放置位置和数据正确性:
在典型的配置里,数据块一个放在当前的节点,一个放在远程的机架上的一个节点,一个放在相同机架上的一个节点,多于3个的数据块随意选择放置。客户端选择最近的一个节点读取数据。Hadoop使用CRC32效验数据的正确性,客户端每512个byte计算一次效验,DN负责存储效验数据。客户端从DN获取数据和效验数据,如果效验出错,客户端尝试另外节点上复制的数据。
Tips:
单点的NN,现在Hadoop没有HA的解决方案。在我的概念中Hadoop加上Zookeeper是一个HA的解决方案。事务日志可以存储在NM的多个目录中。比如:一个本地文件系统,一个远程文件系统(NFS)。Hadoop没有快照功能,可以考虑使用LVM或ZFS做系统快照。本节关于Hadoop的分布式文件系统HDFS介绍完毕。
【编辑推荐】
- Hadoop简介:HDFS和MapReduce的实现
- Hadoop 学习总结 :HDFS概念及其用法
- 轻松实现Hadoop Hdfs配置
- Hadoop集群搭建过程中相关环境配置详解
- Hadoop完全分布模式安装实现详解