本节向大家介绍一下Hadoop文件系统的快速安装与使用,希望通过本节的介绍大家能够掌握Hadoop文件系统安装与使用方法,欢迎大家一起来学习。
Hadoop文件系统(HDFS)快速安装与使用技术文档
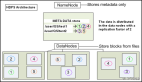
准备3台机器,一台作为Namenode,命名为master,两台作为dataNode,命名为slave01,slave02
在3台机器上都设置hadoop用户。
设置hadoop用户从master到slavessh不需要密码,设置方法参见“设置SSH服务器只采用密钥认证”一文。
注意:
(1)authorized_keys文件的访问权限应该设置为644,否则可能导致无密码登录失败。
(2)从master到master登录也需要配置无密码登录,否则会导致Namenode启动失败
下载并安装JDK,并在/etc/profile配置相应的环境变量,比如
JAVA_HOME=/usr/java/jdk1.6.0_18
CLASSPATH=.:$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
exportJAVA_HOMECLASSPATHPATH
在三台机器上创建相同的目录路径,为HDFS运行准备环境,比如在/data目录下创建hadoop目录,将其属主改成hadoop,然后在下面如下创建4个目录:
install:Hadoop源码解压后,放在该目录下
name:HDFS的名字节点存放目录
data01,data02:HDFS的数据存放目录,当然也可以是一个。
tmp:临时空间
注意:name目录只存放在master上,且权限为755,否则会导致后面的格式化失败。
编辑Hadoop文件系统HDFS配置文件,所有节点都要保持一致,共有四个:
core-site.xml:核心配置
hdfs-site.xml:站点多项参数配置
masters:主节点,在HDFS中就是Namenode的名称
slaves:数据节点(Datanode)名称
各个配置文件举例
核心配置:core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
站点节点配置:hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>2</value>
- </property>
- <property>
- <name>dfs.name.dir</name>
- <value>/data/hadoop/name</value>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/data/hadoop/data01,/data/hadoop/data02</value>
- </property>
- <property>
- <name>dfs.tmp.dir</name>
- <value>/data/hadoop/tmp</value>
- </property>
- </configuration>
主节点名称:masters
master
数据节点名称:slaves
master
slave01
slave02
注意:(1)如需要,可以在hadoop-env.sh中配置JAVA_HOME变量,比如:
exportJAVA_HOME=/usr/java/jdk1.6.0_18
(2)保证Hadoop文件系统各个节点上配置文件的一致性。
初始化namenode节点
登录到namenode上,cd/data/hadoop/install/bin,然后格式化Image文件的存储空间:
./hadoopnamenode-format
如果出错,就查看/data/hadoop/install/logs下的日志文件。
启动HDFS服务
在/data/hadoop/install/bin下有很多命令,
*start-all.sh启动所有的Hadoop守护,包括namenode,datanode,jobtracker,tasktrack,secondarynamenode。
*stop-all.sh停止所有的Hadoop。
*start-mapred.sh启动Map/Reduce守护,包括Jobtracker和Tasktrack。
*stop-mapred.sh停止Map/Reduce守护
*start-dfs.sh启动HadoopDFS守护,Namenode和Datanode。
*stop-dfs.sh停止DFS守护
简单使用
创建目录:./hadoopdfs-mkdirtest
查看目录:./hadoopdfs-ls
drwxr-xr-x-hadoopsupergroup02010-03-0421:27/user/hadoop/test
拷贝文件:./hadoopdfs-put/etc/servicestest,即把本地的文件存放到HDFS中
WEB界面
HDFS启动后,可以通过WEB界面来查看,缺省端口为50070,比如:http://master:50070/
即可查看整个HDFS的状态以及使用统计。
对于Mapreduce的WEB界面,缺省端口是50030。本节关于Hadoop文件系统的安装与使用介绍到这里。
【编辑推荐】