本节和大家一起学习一下Hadoop方面的知识,本节主要内容有Hadoop概念介绍,Hadoop结构示意图和Hadoop的优点及使用场景,欢迎大家一起来学习Hadoop。首先看一下Hadoop的概念。
Hadoop概念
Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。
简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
Hadoop实现了一个分布式文件系统(HadoopDistributedFileSystem),简称HDFS。HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(highthroughput)来访问应用程序的数据,适合那些有着超大数据集(largedataset)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streamingaccess)文件系统中的数据。
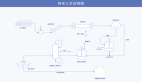
Hadoop结构示意图
在Hadoop的系统中,会有一台Master,主要负责NameNode的工作以及JobTracker的工作。JobTracker的主要职责就是启动、跟踪和调度各个Slave的任务执行。还会有多台Slave,每一台Slave通常具有DataNode的功能并负责TaskTracker的工作。TaskTracker根据应用要求来结合本地数据执行Map任务以及Reduce任务。
说到这里,就要提到分布式计算最重要的一个设计点:MovingComputationisCheaperthanMovingData。就是在分布式处理中,移动数据的代价总是高于转移计算的代价。简单来说就是分而治之的工作,需要将数据也分而存储,本地任务处理本地数据然后归总,这样才会保证分布式计算的高效性。
为什么要选择Hadoop?
说完了What,简单地说一下Why。官方网站已经给了很多的说明,这里就大致说一下其优点及使用的场景(没有不好的工具,只用不适用的工具,因此选择好场景才能够真正发挥分布式计算的作用):
可扩展:不论是存储的可扩展还是计算的可扩展都是Hadoop的设计根本。
经济:框架可以运行在任何普通的PC上。
可靠:分布式文件系统的备份恢复机制以及MapReduce的任务监控保证了分布式处理的可靠性。
高效:分布式文件系统的高效数据交互实现以及MapReduce结合LocalData处理的模式,为高效处理海量的信息作了基础准备。
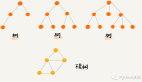
使用场景:个人觉得最适合的就是海量数据的分析,其实Google最早提出MapReduce也就是为了海量数据分析。同时HDFS最早是为了搜索引擎实现而开发的,后来才被用于分布式计算框架中。海量数据被分割于多个节点,然后由每一个节点并行计算,将得出的结果归并到输出。同时***阶段的输出又可以作为下一阶段计算的输入,因此可以想象到一个树状结构的分布式计算图,在不同阶段都有不同产出,同时并行和串行结合的计算也可以很好地在分布式集群的资源下得以高效的处理。本节关于Hadoop的介绍完毕,请关注本节其他相关报道。
【编辑推荐】