本节从用户的角度出发,全面地介绍了Hadoop Map-Reduce框架的各个方面,希望通过本节介绍大家对Hadoop Map-Reduce有一定的认识,欢迎大家一起来学习。
先决条件
请先确认Hadoop被正确安装、配置和正常运行中。
概述
Hadoop Map-Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
一个Map-Reduce作业(job)通常会把输入的数据集切分为若干独立的数据块,由map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序,然后把结果输入给reduce任务。通常作业
的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,Map-Reduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。
Map-Reduce框架由单独一个masterJobTracker和每个集群节点一个slaveTaskTracker共同组成。这个master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上,master监控它们的执行,重新执行已经失败的任务。而slave仅负责执行由master指派的任务。
应用程序至少应该指明输入/输出的位置(路径),并通过实现合适的接口或抽象类提供map和reduce函数。再加上其他作业的参数,就构成了作业配置(jobconfiguration)。然后,Hadoop的jobclient提交作业(jar包/可执行程序等)和配置信息给JobTracker,后者负责分发这些软件和配置信息给slave、调度任务且监控它们的执行,同时提供状态和诊断信息给job-client。
虽然Hadoop框架是用JavaTM实现的,但Map-Reduce应用程序则不一定要用Java来写。
HadoopStreaming是一种运行作业的实用工具,它允许用户创建和运行任何可执行程序(例如:Shell工具)来做为mapper和reducer。
HadoopPipes是一个与SWIG兼容的C++API(没有基于JNITM技术),它也可用于实现Map-Reduce应用程序。
Hadoop Map-Reduce输入与输出
Map-Reduce框架运转在<key,value>键值对上,也就是说,框架把作业的输入看为是一组<key,value>键值对,同样也产出一组<key,value>键值对做为作业的输出,这两组键值对的类型可能不同。
框架需要对key和value的类(classes)进行序列化操作,因此,这些类需要实现Writable接口。另外,为了方便框架执行排序操作,key类必须实现WritableComparable接口。
一个Map-Reduce作业的输入和输出类型如下所示:
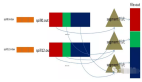
(input)<k1,v1>->map-><k2,v2>->combine-><k2,v2>->reduce-><k3,v3>(output)
Hadoop Map-Reduce-用户界面
这部分文档为用户将会面临的Map-Reduce框架中的各个环节提供了适当的细节。这应该会帮助用户更细粒度地去实现、配置和调优作业。然而,请注意每个类/接口的javadoc文档依然是能提供最全面的
文档;本文只是想起到教程的作用。
我们会先看看Mapper和Reducer接口。应用程序通常会通过提供map和reduce方法来实现它们。
然后,我们会讨论其他的核心接口,其中包括:JobConf,JobClient,Partitioner,OutputCollector,Reporter,InputFormat,OutputFormat等等。
最后,我们将以通过讨论框架一些有用的功能点(例如:DistributedCache,IsolationRunner等等)的方式来收尾。
Hadoop Map-Reduce核心功能描述
应用程序通常会通过提供map和reduce来实现Mapper和Reducer接口,它们组成作业的核心。
Mapper
Mapper将输入键值对(key/valuepair)映射到一组中间格式的键值对集合。
Map是一类将输入记录集转换为中间格式记录集的独立任务。这种转换的中间格式记录集不需要与输入记录集的类型一致。一个给定的输入键值对可以映射成0个或多个输出键值对。
HadoopMap-Reduce框架为每一个InputSplit产生一个map任务,而每个InputSplit是由对应每个作业的InputFormat产生的。
概括地说,对Mapper的实现者需要重写JobConfigurable.configure(JobConf)方法,这个方法需要传递一个JobConf参数,目的是完成Mapper的初始化工作。然后,框架为这个任务的InputSplit中每个键值对调用一次map(WritableComparable,Writable,OutputCollector,Reporter)操作。之后,应用程序可以通过重写Closeable.close()方法来执行相应的清理工作。
输出键值对不需要与输入键值对的类型一致。一个给定的输入键值对可以映射成0个或多个输出键值对。通过调用OutputCollector.collect(WritableComparable,Writable)可以收集输出的键值对。
应用程序可以使用Reporter报告进度,设定应用级别的状态消息,更新Counters(计数器),或者仅是表明自己运行正常。
框架随后会把与一个特定key关联的所有中间过程的值(value)分成组,然后把它们传给Reducer以产出最终的结果。用户可以通过JobConf.setOutputKeyComparatorClass(Class)来指定具体负责分组的Comparator。
Mapper的输出被排序后,就被划分给每个Reducer。分块的总数目和一个作业的reduce任务的数目是一样的。用户可以通过实现自定义的Partitioner来控制哪个key被分配去哪个Reducer。
用户可选择通过JobConf.setCombinerClass(Class)指定一个combiner,它负责对中间过程的输出进行本地的聚集,这会有助于降低从Mapper到Reducer数据传输量。
这些被排好序的中间过程的输出结果通常是以SequenceFile格式的文件被存放的。应用程序可以通过JobConf控制对这些中间结果是否进行压缩以及怎么压缩,使用哪种ompressionCodec。本节关于Hadoop Map-Reduce相关内容介绍到这里。
【编辑推荐】
- Hadoop MapReduce的简单应用Cascading详解
- 如何实现Cassandra与Hadoop MapReduce的整合?
- Hadoop集群与Hadoop性能优化
- HadoopHBase实现配置简单的单机环境
- 深入剖析Hadoop HBase