本节向大家描述一下什么是Hadoop,主要内容有Hadoop概念介绍和Hadoop开源的实现等,相信看完本文的介绍,大家对Hadoop有更深刻的认识。
Hadoop是什么
Hadoop 是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。项目主页:http://hadoop.apache.org
Hadoop是一个用于运行应用程序在大型集群的廉价硬件设备上的框架。Hadoop为应用程序透明的提供了一组稳定/可靠的接口和数据运动。在Hadoop中实现了Google的MapReduce算法,它能够把应用程序分割成许多很小的工作单元,每个单元可以在任何集群节点上执行或重复执行。此外,Hadoop还提供一个分布式文件系统用来在各个计算节点上存储数据,并提供了对数据读写的高吞吐率。由于应用了map/reduce和分布式文件系统使得Hadoop框架具有高容错性,它会自动处理失败节点。已经在具有600个节点的集群测试过Hadoop框架。
Google的数据中心使用廉价的Linux PC机组成集群,在上面运行各种应用。即使是分布式开发的新手也可以迅速使用Google的基础设施。核心组件是3个:
1、GFS(Google File System)。一个分布式文件系统,隐藏下层负载均衡,冗余复制等细节,对上层程序提供一个统一的文件系统API接口。Google根据自己的需求对它进行了特别优化,包括:超大文件的访问,读操作比例远超过写操作,PC机极易发生故障造成节点失效等。GFS把文件分成64MB的块,分布在集群的机器上,使用Linux的文件系统存放。同时每块文件至少有3份以上的冗余。中心是一个Master节点,根据文件索引,找寻文件块。详见Google的工程师发布的GFS论文。
2、MapReduce。Google发现大多数分布式运算可以抽象为MapReduce操作。Map是把输入Input分解成中间的Key/Value对,Reduce把Key/Value合成最终输出Output。这两个函数由程序员提供给系统,下层设施把Map和Reduce操作分布在集群上运行,并把结果存储在GFS上。
3、BigTable。一个大型的分布式数据库,这个数据库不是关系式的数据库。像它的名字一样,就是一个巨大的表格,用来存储结构化的数据。
开源实现
这个分布式框架很有创造性,而且有极大的扩展性,使得Google在系统吞吐量上有很大的竞争力。因此Apache基金会用Java实现了一个开源版本,支持Fedora等Linux平台。目前Hadoop受到Yahoo的支持,有Yahoo员工长期工作在项目上,而且Yahoo内部也准备使用Hadoop代替原来的基于FreeBSD的系统。
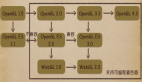
Hadoop实现了HDFS文件系统和MapRecue。目前版本是0.16。还不成熟,但是已经可以在2000个节点上运行。用户只要继承MapReduceBase,提供分别实现Map和Reduce的两个类,并注册Job即可自动分布式运行。
HDFS把节点分成两类:NameNode和DataNode。NameNode是***的,程序与之通信,然后从DataNode上存取文件。这些操作是透明的,与普通的文件系统API没有区别。
MapReduce则是JobTracker节点为主,分配工作以及负责和用户程序通信。
目前这个项目还在进行中,还没有到达1.0版本,和Google系统的差距也非常大,但是进步非常快,值得关注。另外,这是云计算(Cloud Computing)的初级阶段的实现,是通向未来的桥梁。
【编辑推荐】