【51CTO独家特稿】低碳指数:在这里为了方便计算和直观,我们以Intel至强X7500处理器的TDP为标准计算能耗(TDP=130W/h=2.167W/m=0.036W/s)。另外根据中国林业局的数据,一棵树一天吸收二氧化碳量为5.023kg,每一度电产生0.785公斤二氧化碳。
如果按照本文方法优化后数据库执行时间由191秒缩减到189秒,也就是单位时间少1%的能量消耗。那么在一天里将减少0.03kw电能消耗,约合0.023kg二氧化碳排放,按我们的计算是一天减少0.05棵树二氧化碳吸收量。
本文引用一套实验室信息管理系统(LIS)使用的数据库,假设我们要查询2008年11月做检验的患者记录,条件是大于80岁,姓周的患者,最终结果按检查日期进行倒序排列。要使用的表有三个:
◆lis_report:报告主表,我们要用到的字段包括i_checkno(检查号),d_checkdate(检查日期),i_patientid(患者ID);
◆comm_patient:患者信息表,我们要用到的字段包括i_patientid(患者ID),s_name(患者姓名),s_code(患者住院号),i_age(患者年龄),i_dept(患者所在病区);
◆lis_code_dept:病区信息表,我们要用到的字段包括i_id(病区ID,主键,与comm_patient中的i_dept关联),s_name(病区名)。
最终我们构造的SQL如下:
- select a.i_checkno, a.d_checkdate, b.s_name, b.s_code, b.i_age, c.s_name
- from lis_report a
- inner join comm_patient b on a.i_patientid = b.i_patientid
- inner join lis_code_dept c on b.i_dept = c.i_id
- where a.d_checkdate > '2008-11-01'
- and a.d_checkdate < '2008-11-30'
- and b.i_age>=80
- and b.s_name like '周%'
- order by a.d_checkdate desc
我们的SQL使用的这三张表除了创建主键时自动创建的索引外,均未创建其它索引,下图是无索引时的执行计划。
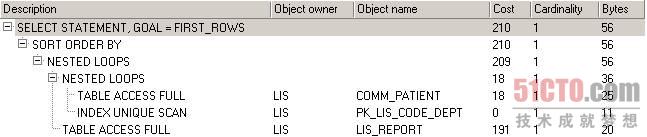
图 1 无索引时的执行计划
从图1可以看出,表comm_patient和lis_report都使用了全表扫描,comm_patient全表扫描的成本是18,lis_report全表扫描的成本是191,只有表lis_code_dept因关联时使用的是其主键,因此这里使用了主键索引,从而避免了全表扫描,它的成本是0。我们知道提高查询性能的目标之一就是消灭掉全表扫描,因此我们应该给表comm_patient和lis_report加上适当的索引,在SQL代码的where子句中,对comm_patient表,我们引用了i_age和s_name字段,对lis_report表,我们引用了d_checkdate字段,通常给这些条件中引用的字段加上索引会提高查询速度,我们先给comm_patient的i_gae字段加上索引,下面是对应的执行计划。
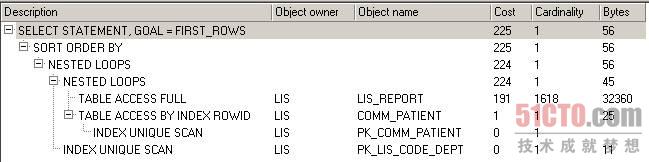
图 2 给comm_patient的i_age加上索引后的执行计划
从图2可以看出,表comm_patient的全表扫描消失了,取而代之的是索引唯一性扫描,成本从18一下子降低到1了,注意这里并未使用我们给i_age增加的索引,但却靠它触发了使用表主键对应的索引。但表lis_report仍然是全表扫描,由于where子句中引用了该表的d_checkdate字段,因此我们给该字段加上索引看看效果。
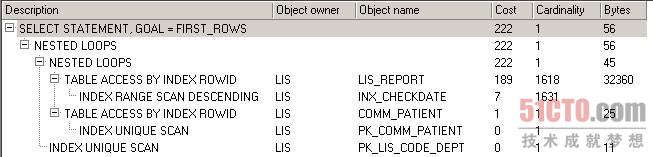
图 3 给lis_report的d_checkdate字段加上索引后的执行计划
从上图可以看出,表lis_report的全表扫描消失了,取而代之的是索引范围降序扫描(INDEX RANGE SCAN DESCENDING),成本也从191下降到189。注意这里的索引范围降序扫描的来历,因为我的where子句中引用d_checkdate是介于2008-11-01至2008-11-30的一个范围,这时引用的这种字段上建立的索引通常都是执行范围扫描,因为这种条件返回的值往往不止一行。使用降序扫描的原因是order by子句使用了降序排序,如果我们将SQL代码中的“order by a.d_checkdate desc”改为“order by a.d_checkdate”,则变为索引范围扫描(INDEX RANGE SCAN)。
至此我们全部消除了全表扫描,我们看到加上索引后,查询执行的成本开销也有所降低,因为数据库表中的记录数不大,因此效果不太明显,如果有上百万条记录则会更直观。
虽然索引能提高查询性能,但索引也不能滥用,一是因为索引会降低写入性能,二是索引过多给索引管理带来麻烦,有些索引根本就没有使用,这样的索引只会带来负面影响,基于这些弊端的考虑,在设计数据库结构时应综合考虑表的使用频率(使用次数越多越应重点考虑是否建立索引),表中字段的使用频率(字段使用次数越多越应建立索引),字段类型(数值型字段越应建立索引),值的唯一性(最应建立索引的字段),值的重复性(值重复度越高,建立索引的必要性越低),值是否可为空(允许为空的字段一般不建立索引),表中记录数(记录数很少时一般不宜建立索引),表是读操作多一些还是写操作多一些(读操作越多的表越应建立索引,写操作越多的表越应避免建立索引)等,创建索引的一般原则是:在大表的常用且值重复几率小的字段上创建索引。
数据库性能优化是无止境的,无论哪种优化技术只是一种手段,但最重要的不是技术,而是思想,掌握了索引优化技术仅仅刚入门,只有融会贯通,举一反三才能成为高手。
【编辑推荐】