读操作与一致性
Brewer的CAP定理是分布式系统中的一个基本定理:分布式系统可以有一致性(Consistency)、可用性(Availability)以及分区容错性(Partition-tolerance)这三种属性,但是只能同时确保其中的两个属性.在Cassandra中,他们保证AP并弱化一致性为众所周知的最终一致性(Eventual Consistency). 考虑下面这种情况,读操作与写操作在时间上非常接近.假设你拥有一个Key “A”,它的值在你的集群中为“123”.现在,你将“A”更新为“456”.写操作被发送到N个不同的节点,每个节点都耗费部分时间来写这个值.现在,你发送一个读取Key “A”的请求.这些节点中的某些节点中这个Key对应的值可能仍然为“123”,而同时节点中的其他节点此Key的值为“456”.他们最终都会返回“456”,但并不能保证什么时候可以做到(在实践中,通常是几个毫秒的时间).接下来你就会发现为什么这一点很重要.
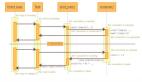
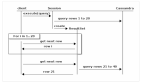
在你的客户端,读操作与写操作类似,客户端发送一个读请求到Cassandra集群中的任一随机节点(也就是存储代理,Storage Proxy).这个代理确定持有需要被读取数据的N份拷贝所在的环上的节点(根据复制放置策略),并对每一个节点发出一个读请求.由于最终一致性的限制,Cassadra允许客户端选择读一致性的强度:
◆单一读 – 代理返回它获得的第一份响应. 这样很可能返回过期的数据.
◆仲裁数读取 – 代理等待一个简单多数返回同样的数据.这样读取过期数据(除非有节点宕机)会变得更加困难,但也更慢了.
在后台,代理还会对任何不一致的响应执行读修复(read repair).代理会往任何返回较早的值的节点发送一个写请求,以确保这些节点在将来可以返回最新的值.下面是部分边缘状况,我不清楚Cassandra是如何进行处理的:
◆如果有偶数个节点有回应,其中一半返回值“X”而另一半返回值“Y”?由于每个列的值都有时间戳,我推测它可能会使用时间戳来做最后的裁判.
◆如果有两个包含旧时间戳的节点返回“X”而一个有新时间戳的节点返回“Y”,Cassandra该如何处理? 多数会覆盖时钟吗?
◆如果集群的节点的始终不同步,Cassandra会如何操作?
扫描范围
作为键值存储(Key/value store),Cassandra运转良好:给定一个键(Key),它就会为你返回这个键(Key)对应的值(Value).但这通常还不足以回答关键的问题:如果我想要读取所有姓(last name)从Z开始用户?或者读取所有在2010年2月1日到2010年3月1日之间下的订单?要回答这些问题,Cassandra必须知道如何来确定持有这些相关值的节点.这个工作是由分割器(Partitioner)来完成的.默认情况下,Cassandra会使用RandomPartitioner(随机分割器),它可以确保将负载均匀地分布在集群上,但是无法使用它来做范围扫描.作为替代,一个列族(Column Family)可以配置使用OrderPreservingPartitioner(保留顺序的分割器),它知道如何将一个范围的键(Key)映射(map)到一个或多个节点上.实际上,它知道哪个(些)节点持有你的按字母排序的用户的数据以及哪个(些)节点持有二月份的订单.
单一节点上的读取操作
因此,将分布式系统的所有胡说八道都放在一边,当执行读操作时每个节点在做什么? 回想一下, Cassandra有两个级别的存储:Memtable与SSTable. 从Memtable中读取相对无痛 – 我们是在内存中进行操作,数据量也相对较小,在这些内容中循环查找尽可能很快.扫描SSTable时,Cassandra使用一个更低级别的列索引与布隆过滤器(bloom filter)来查找磁盘上的必要的数据块,对数据进行反序列化(deserialize),并确定需要返回的真实数据. 这里会发生大量的磁盘IO,因此最终造成的读延时会比类似的DBMS还要高. Cassandra提供了部分行缓存(row caching),它确实解决大部分的延时.
这篇文章时一个Cassandra的读取路径的旋风之旅. 要想知道更多关于此主题的内容,请参考存储配置(StorageConfiguration)的维基文章. 我将在下篇文章中介绍Cassandra中的部分技巧(诀窍), Cassandra用它们来解决分布式系统内置的无数边缘状况

原文链接:http://www.dbthink.com/?p=432