













【51CTO独家特稿】低碳指数:在这里为了方便计算和直观,我们以Intel至强X7500处理器的TDP为标准计算能耗(TDP=130W/h=2.167W/m=0.036W/s)。另外根据中国林业局的数据,一棵树一天吸收二氧化碳量为5.023kg,每一度电产生0.785公斤二氧化碳。
如果按照本文方法优化后数据库执行时间由27秒缩减到14秒,也就是单位时间少47.8%的能量消耗。那么在一天里将减少1.486kw电能消耗,约合1.167kg二氧化碳排放,按我们的计算是一天减少0.232棵树二氧化碳吸收量。
51CTO数据库频道向您推荐《数据库性能优化与调试》和《SQL Server 2008/2005全解》专题,以便于您更好的理解本文。
设定过滤条件提高索引效率
优秀的索引是SQL Server数据库性能的关键,然而高效的索引都是经过精心设计而成的。众所周知,主键是储存数据对象的***标识,如果数据表中没有聚簇索引,为了维护主键的***性,SQL Server数据库在默认情况下将为主键创建聚簇索引(Clustered index),除非用户特别指定将索引创建为非聚簇索引(Non-clustered index)。
毫无疑问,我们应当为频繁访问的数据创建聚簇索引,当然频繁访问的字段应当经过详细的分析和慎重选择,并且索引值应当尽可能短。提到创建索引,大家往往首先想到主键,但是主键的数据并不一定被频繁访问,而且很多时候为了保证主键的***性,主键的数值往往不是很短,比如我们经常会选择全局***标识符(GUID)类型作为主键的数据类型,***标识符的长度一般是16个字节,就长度而言,这种数据类型并不是最理想的聚簇索引选项,在这种情况下,可以为主键创建非聚簇索引,因为主键值在WHERE语句中用来查询特定的记录是非常高效的,创建非聚簇索引可以将查询的效率再上一个台阶。如果您选择了整型作为主键的数据类型,那就可以考虑将为主键生成聚簇索引。
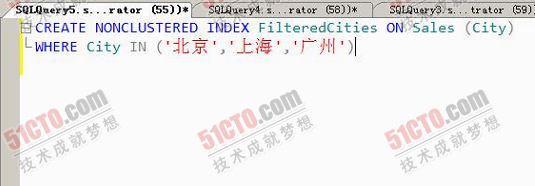
SQL Server 2008为我们提供了另外一种索引——设定过滤条件索引(Filtered index),一个设定过滤条件索引是一个特殊的非聚簇索引,它是某些字段的特定子集。换句话说,设定过滤条件索引是基于一部分选定的字段生成的。比如说,在销售业绩数据表中,分公司所在城市的数据存储在City字段,如果我们创建一个非聚簇索引,那么所有的分公司所在的城市,都会被纳入索引当中。但是如果我们使用设定过滤条件索引,我们就可以只选择一部分城市被索引,比如北京,上海和广州,代码如下:
- CREATE NONCLUSTERED INDEX FilteredCities ON Sales(City)
- WHERE City IN ('北京','上海','广州')
与常规索引的区别在于,我们使用了WHERE语句来设定我们的过滤条件。假定公司的绝大部分收入都是来自于这三个城市的,那么我们的数据库查询会经常访问到在这三个城市产生的销售记录,在这种情况下,设定过滤条件索引会占据较少的磁盘空间,因为只有City字段的数值是北京,上海和广州的记录会被索引,这些记录只是整个销售数据表格中的一部分。
利用设定过滤条件索引可以提升数据库的性能,首先,只有被索引到记录发生变化的时候,才需要重建索引。比如,某一条在北京发生的销售记录需要调整,在更新操作之后,索引也要随之更新,这跟其他的索引是一样的。但如果发生在西安的销售记录发生了变化,无论添加或删除了多少条记录,我们之前建立的设定过滤条件索引都是不需要任何操作的,因为只有位于北京、上海和广州分公司的销售记录有影响到这个索引。设定过滤条件索引的另外一个优势是可以减少磁盘读写操作,比如我们要查询所有北京分公司的销售记录,那么使用刚才建立的设定过滤条件索引比常规的非聚簇索引要减少很多不必要的磁盘操作。
为了验证设定过滤条件索引所带来的性能优势,我们进行了对比测试。
首先,我们在VirtualBox虚拟机里安装Windows Server 2008 R2与SQL Server 2008 R2中文版,顺便说一下,我们安装的都是可以试用180天的试用版,在微软官方网站可以直接下载,而且现在试用版也不需要申请序列号了,在安装过程中可以直接选择安装180天试用,就可以直接安装,这位实验和学习带来了不少便利。
我们在数据库中创建了一个500万条记录的销售数据表,当然,销售金额都是随机产生的,而city字段,我们随机产生1到9这9个不同的数字,然后再根据需要将它们在替换为不同的城市,在这个实验中,我们把北京、上海和广州的销售记录总比例设定为67%。
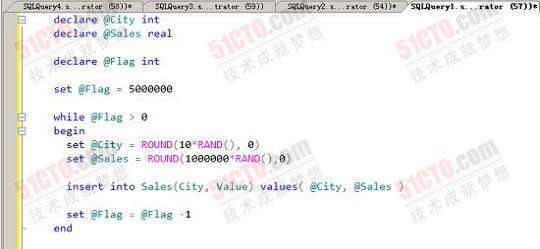
点击查看清晰大图
接下来,我们将虚拟机进行完整的复制,这样就可以得到两套完全一致的操作系统和数据库,数据库中已经包含了我们刚刚创建的数据表,相关过程可以参考VirtualBox的技术文档。复制整个虚拟机的目的在于确保硬件和操作系统对数据库性能的影响最小,以便于我们将注意力集中在不同索引方式下,数据库性能的表现。
下一步,我们在***个虚拟机中创建city字段的完整的非聚簇索引,代码如下:
- CREATE NONCLUSTERED INDEX FilteredCities ON Sales(City)
在第二个虚拟机中,我们创建设定过滤条件索引,代码如下
- CREATE NONCLUSTERED INDEX FilteredCities ON Sales(City)
- WHERE City IN ('北京','上海','广州')
点击查看清晰大图
然后我们在两个虚拟机的数据库中来计算北京、上海和广州这三个城市的销售金额总和,代码如下
- SELECT SUM(Value) FROM Sales
- WHERE City = '北京' or City = '上海' or City = '广州'
在使用完整的非聚簇索引的情况下,我们花费了27秒,而使用设定过滤条件索引的情况下,我们只需要14秒就得到了计算结果,可见非聚簇索引在大规模数据计算的情况下,对性能的提升还是非常可观的,我们截取的屏幕如下,供大家参考:

优化前:点击查看清晰大图

优化后:点击查看清晰大图
在选择过滤条件的时候,我们需要考虑哪些数据会随着时间的推移而经常变化,比如,新增加的记录是添加到索引的中间还是末尾?当记录删除的时候,索引值是否需要随之删除?这些问题的答案都会影响我们对索引的设计。
在这里,我们需要用到填充因子(Fill Factor),填充因子是一个以百分比表示的数值,在重建索引的时候,填充因子的值决定了每个页面上要填充数据的空间百分比,以便保留一些剩余空间作为以后扩展索引的可用空间,以下代码演示了如何将填充因子设定为80,只有在高级选项打开的情况下才能设定填充因子:
- Use DatabseName;
- GO
- sp_configure 'show advanced options', 1;
- GO
- RECONFIGURE;
- GO
- sp_configure 'fill factor', 80;
- GO
如果填充因子的值是100,那么索引页就被会全部填充。我们一般考虑将填充因子设定为50到80中间的数值来保证添加新值的时候,不会发生页拆分。如果经常需要在索引末尾添加字段值的话,可以考虑将填充因子设定为90到100之间的值。最理想的状态是同时保证最少次数的的页拆分和索引重建。
【编辑推荐】










