













本文将从一个实例讲述.NET应用访问数据库的开销问题。作者主要是从.NET应用访问数据库的遍历顺序改进讲起。当然,与之配套的也就是我们熟悉的SQL Server数据库。
拿今天的一个例子说话吧,那就表中存放的是全国的地域信息,表结构如下:
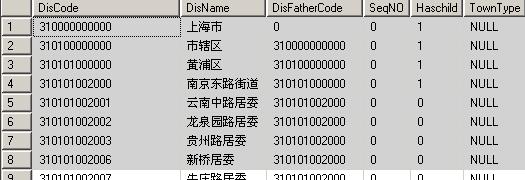
首先用代码生成器和存储过程生成器生成基本表的操作,推荐两个工具:动软.Net代码生成器- 全功能的三层架构.Net代码生成器和codeplex上面的一个存储过程生成工具Stored Procedure Generator (for SQL Server 2000/2005 ... 。
现在提供了一个方法,可以获取***和二级地域的信息,最开始的做法是先获取***的地域信息,然后循环***地域信息,获取它的子节点。
- List<KB.DSN.Entity.District> topDistrictList = new List<KB.DSN.Entity.District>();
- KB.DSN.BusinessAccess.District dictrictBll = new KB.DSN.BusinessAccess.District();
- topDistrictList = dictrictBll.GetEntityList(string.Format("DisFatherCode='{0}' {1}", 0, Settings.District_Order_By));
- foreach (KB.DSN.Entity.District dis in topDistrictList)
- {
- dis.ChildrenDis = dictrictBll.GetEntityList(string.Format("DisFatherCode='{0}' {1}", dis.DisCode, Settings.District_Order_By));
- }
- return topDistrictList;
上面的做法,可以实现功能,***测试获取一级和二级的地域信息,花费时间5秒左右,不说能接受吧,起码可以忍受。HttpWatch: An HTTP Viewer and HTTP Sniffer for IE and Firefox 这个工具可以查看浏览器获取数据的时间。
后面又写了一个方法,可以根据地域编号和想要获取的层级数目,获取指定地域下面的N层地域。和上面差不多,完成后一次是,一次获取上海下面的二级花费10秒,获取三级50秒。这好像就不能忍受了吧。
然后进行优化,代码如下,变成一次获取二级的数据,然后用C#代码来生成层级关系。
- List<KB.DSN.Entity.District> districtList = new List<KB.DSN.Entity.District>();
- KB.DSN.BusinessAccess.District dictrictBll = new KB.DSN.BusinessAccess.District();
- districtList = dictrictBll.GetEntityList(string.Format(" {0} {1}", Settings.Get_Top_And_Second_District_Where,
- Settings.District_Order_By));
- var top = from c in districtList
- where c.DisFatherCode.Trim() == "0"
- select c;
- var second = from c in districtList
- where c.DisFatherCode.Trim() != "0"
- select c;
- foreach (KB.DSN.Entity.District dis in top)
- {
- var se = from c in second
- where c.DisFatherCode == dis.DisCode
- select c;
- dis.ChildrenDis = se as List<KB.DSN.Entity.District>;
- }
- return top as List<KB.DSN.Entity.District>;
作者后续
提到数据库的访问,尤其是递归层级调用问题,应该减少往返数据库的次数,而是从数据库将所需数据一次性获取出来,然后在C#代码中处理成树形层级关系,这样会提升很大的效率。
其实递归这种东西,用在数值计算中还可以,如果是复杂处理就***不用了,很消耗CPU和内存的,因为要使用栈存放很多内容。只是代码看起来好理解,量大、操作复杂还是转成非递归的好。
如果层级不多,变化不大,可以考虑使用缓存,效率就会更高。具体缓存的应用可以参看李天平的:系统缓存全解析 ,后面我可能也会写一两篇这方面的文章。
上一篇我们讨论的数据是全国的行政地域信息,它有固定的格式。每个行政区划的编码长度都是12位,总共分5级来管理,前两位代表31个省(直辖市),往后两位代表一般的市(州),往后两位代表市中的区(县),往后三位是街道办事处,***三位是居民委员会(社区)。
系统中其实有很多类似的类型编码都被 放在数据库中,有的是一级的,有的是分层级关系的。就像上面的地域信息,全国的5级总共有8万左右条数据。***的办法是一次将他们读取到服务器的内存中,形成树形层级,放在缓存中,如果有需要就直接获取返回给客户端,这样可以较少很多的数据库消耗。当然,前提是这类信息的变动很小,几乎没有变化。系统缓存全解析6:数据库缓存依赖 中介绍了,可以使用数据库依赖缓存,这样就不怕数据库内容有变化了,如果有变化,会自动更新缓存。缓存的正确使用,可以极大的提供效率
原文标题:NET应用访问数据库之数据库的开销问题
链接:http://www.cnblogs.com/virusswb/archive/2010/03/05/1679383.html
【编辑推荐】
- 浅谈如何在SQL Server中生成脚本
- SQL Server使用索引实现数据访问优化
- SQL Server 05数据库被置为“可疑”的解决方法
- 详解SQL Server的版本区别及选择
- SQL Server不存在或拒绝访问故障的排除










